 Оценка 220
Оценка 220 
 Оценить
Оценить 





| Оценка 220 Оценить
|
В отличие от алгоритмов компрессии с потерей информации, алгоритмы без потерь не смогут ошеломить нас двух- и более значными степенями сжатия. Также не поразят они нас новизной своих идей – большинство таких алгоритмов было разработано не одно десятилетие назад, тогда как новые алгоритмы компрессии с потерями (например, для сжатия потока видеоданных) появляются почти каждый год. Тем не менее, потребность в компрессионных алгоритмах, позволяющих полностью восстанавливать исходную информацию, имеющих хорошие коэффициенты сжатия, надежно и качественно реализованных и не требующих больших ресурсных затрат, очень высока. Особенно это касается областей, где ресурсы являются критической проблемой, а также там, где используются каналы передачи данных с низкой пропускной способностью.
Среди всех известных алгоритмов компрессии без потерь можно выделить несколько фаворитов, которые наиболее часто используют в современных компрессорах. Их высокая популярность объясняется, прежде всего, тем, что в большинстве случаев они обеспечивают лучшие результаты компрессии по сравнению с другими известными методами. Одним из таких алгоритмов является алгоритм «предсказание по частичному совпадению» PPM (Prediction by Partial Matching). Считается, что это один из лучших алгоритмов для сжатия текстовой информации, но и для других типов информации, например для бинарных данных, его коэффициенты сжатия очень высоки.
Но, несмотря на большое количество разнообразных реализаций этого алгоритма, ощущается недостаток такой реализации, которая сочетала бы в себе высокую компрессию с ресурсными ограничениями, которая бы поддерживала РРМ-модели различных порядков, имела бы возможность подключения экспериментальных алгоритмов для улучшения сжатия, а также имела бы строгую и ясную структуру всего кода реализации. Последнее требование не менее важно, чем все другие, поскольку позволяет использовать кодек в решении конкретных прикладных задач, а не оставлять его на уровне просто тестовой программы. Попытка создания такой реализации и предпринята в этой работе.
В этом разделе излагаются только основные идеи алгоритма РРМ. Более подробное описание этого метода и способов улучшения его компрессии можно найти в книге Д. Ватолина и др. «Методы сжатия данных» [6] или [14].
Алгоритм компрессии РРМ был впервые предложен Д. Клири и Я. Уиттеном в 1984 году [1]. Он относится к методам контекстного моделирования, в которых процесс сжатия информации явно разделяется на две части – моделирование и кодирование. Моделирование создает набор правил и характеристик, описывающих структуру источника информации, а кодирование преобразует информацию в код в соответствии с этим описанием, которое еще называют моделью.
Под источником информации подразумеваются источник, порождающий элементарные единицы информации, в качестве которой чаще всего рассматривают биты или байты. Предполагают, что распределение вероятности появления единиц информации, выбранных из определенного набора, однозначно характеризует источник информации. Если такое распределение известно, то можно подсчитать оптимальную длину кода (наименьшее число бит) кодирования каждой единицы информации, используя теорему К. Шеннона [2] из теории информации.
В общем случае вычислить вероятность распределения появления единиц информации на выходе источника информации является трудной или вовсе невыполнимой задачей. Поэтому строят абстрактную модель источника информации. Задачей такой модели является задание вероятности появления символа, а кодирование происходит с учетом этой вероятности. То есть символ кодируется на основе вероятности, предсказанной моделью. Чем точнее эта вероятность согласуется с реальной вероятностью появления символа, тем плотнее символ может быть закодирован.
Контекстная модель строится на предположении о наличии в кодируемой информации устоявшихся сочетаний символов, то есть о том, что символы часто встречаются в определенном фиксированном окружении других символов. Хорошим примером наличия большого количества устойчивых сочетаний являются естественные языки. Например, в русском языке наиболее часто встречаются двухбуквенные сочетания: «ст», «но», «то», «на», «ов», «ни», «ра», «во», «ко», или трехбуквенные: «сто», «ено», «нов», «тов», «ово», «ова». Контекстная модель пытается более точно предсказать вероятность возникновения символа на источнике информации, используя условные вероятности появления этого символа в определенных сочетаниях с другими символами. Большая точность предсказания появления символа позволяет уменьшить чисто бит для его кодирования. Например, если во французском языке вероятность появления буквы «u» равна 6.05%, то, согласно [2], ее можно закодировать минимальным кодом длиной 4.06 бита, если же учесть, что вероятность появление этой буквы за буквой «q» равна 99%, то букву «u» уже можно закодировать, используя минимальный код длинной 0.014 бита.
Окружение символов, в котором встречается данный символ, называют его контекстом. В алгоритме РРМ рассматриваются только контексты из цепочки символов, расположенные перед взятым символом, поскольку при декомпрессии известны только такие символы. Если накладывают ограничение на максимальное число символов, из которого может состоять контекст, то такую модель источника информации называют контекстной моделью ограниченного порядка(finite context modeling), а порядком модели называют это наибольшее возможное число символов контекста. Такая модель строится на предположении, что если символ возник недавно на источнике информации в каком-то окружении, то он может снова появиться в ближайшем будущем в таком же окружении. Чем чаще появляется символ в данном контексте, тем больше вероятность его последующих появлений этом же контексте, и каждый раз, когда он снова возникает, нужно увеличивать величину вероятности его появления. Такая модель относится к Марковским моделям, поскольку она считает выходную цепочку символов Марковской последовательностью, где появление каждого символа зависит только от предыдущей фиксированной последовательности символов. Подавляющее большинство реализаций алгоритма РРМ использует эту модель (в качестве исключения можно упомянуть, например, реализацию РРМ*, где порядок модели не ограничен), и в этой работе также будет использоваться контекстная модель ограниченного порядка.
В РРМ для каждого контекста определенной длины строится своя модель. Каждая из этих моделей хранит все пришедшие контексты своего порядка, а также список символов, с которыми появились эти контексты, и их частоты. Модели называют по порядку контекста, с которым они работают, и обозначают как orderN, где N-порядок. Таким образом, например, модель пятого порядка, обозначаемая как order5, это модель, которая рассматривает контекст, состоящий только из пяти символов. Есть две модели, которые в алгоритме РРМ оговариваются особо. Первая – это модель, когда контекст вообще отсутствует. Эта модель хранит счетчики появления отдельных символов, по которым оценивается вероятность появления этих символов. Такую модель обозначают order0. Другая особая модель – это та, в которой решается так называемая проблема нулевой частоты, то есть осуществляется оценка вероятности появления символа, когда он приходит первый раз, и все его счетчики частот на всех вышестоящих моделях равны нулю. Эту модель обозначают order(-1) или order_static. Есть несколько методов оценки вероятности появления символа, о котором нет никакой информации. Самый простой из них – это плоское распределение, когда вероятность появления символа определяется как отношение единицы к общему числу символов алфавита.
В алгоритме РРМ попытка оценки вероятности появления текущего символа начинается с самого старшего порядка. Если на этом порядке не удается оценить символ, то осуществляется переход к более низкому порядку, если и на нем это также невозможно сделать, то снова идет переход на нижестоящий порядок. И так до тех пор, пока символ либо не будет оценен на каком-либо порядке, либо не произойдет переход на order_static, на котором оцениваются все пришедшие на него символы. Чтобы можно было декодировать символ, закодированный по вышеописанному принципу, необходимо каким-то образом сообщить декодеру, что произошел переход на более низкий порядок. Для этого в алгоритме РРМ используются дополнительный символ – код ухода (escape codes). Этот символ является специальным и не входящим в алфавит кодируемых символов. Его задача – дать понять декодеру, что текущий символ не может быть закодирован на данном контекстном порядке в виду нулевой частоты его появления, и нужно переходить к более низкому порядку. Таким образом, в РРМ каждый символ кодируется последовательностью вероятностей кодов ухода, завершающейся вероятностью символа, оцененной на каком-то порядке.
Казалось бы, что если вместо цепочки вероятностей кодов ухода перед вычисленной вероятностью символа помещать всего лишь одно число, характеризующее порядок, на котором произошла успешная оценка вероятности появления символа, то такой подход был бы гораздо эффективней, чем использование кодов ухода. Но это неверное предположение. Дело в том, что при кодировании символа часто не нужно посылать код ухода, чтобы декодер понял, что на данном порядке символ не был закодирован. Декодеру всегда известен текущий контекст символа, но неизвестен закодированный символ, который он и пытается найти. Если на текущем порядке данный контекст встретился впервые, то декодеру и без кода ухода понятно, что нужно переходить на более низкий порядок, и, следовательно, кодировщику нет необходимости его создавать. Получается, что даже если невозможно закодировать символ на текущем порядке, то можно не посылать код ухода, не нарушая тем самым процесс декодирования, если рассматриваемый контекст текущего символа встретился впервые. Кроме этого, если кодирование произошло на самом большом порядке модели, надобности в создании кодов ухода вообще нет.
Подход с применением кодов ухода на практике показал свою высокую эффективность по сравнению с другими методами, он и был использован в описываемой в этой работе реализации.
Как будет показано на тестах, метод расчета вероятности кода ухода, существенно влияет на степень компрессии всего алгоритма, поэтому выбор метода вычисления кода ухода является одной из наиболее важных проблем при разработке алгоритма на базе РРМ. В этом разделе описываются различные методы его вычисления.
Код ухода кодируется вероятностью своего возникновения, что можно рассматривать как вероятность появления символа, который в текущем контексте еще не встречался. Как уже отмечалось, чем точнее оцененная вероятность символа согласуется с его реальной вероятностью появления, тем плотнее может быть закодирован этот символ. То же в полной мере относится и к оценке вероятности кода ухода.
Использование кодов ухода расширяет алфавит символов и поэтому влияет на оценку вероятности появления самих символов. Различные модификации РРМ предлагают различные варианты вычисления вероятности кода ухода P(esc) и вероятность появления символа P(s).
Первые два метода были предложены самими разработчиками РРМ в [1]. Первый метод называется метод PPMA, он рассматривает код ухода как еще один символ, с частотой появления равной единице, тогда вероятности будут вычисляться по следующим формулам:
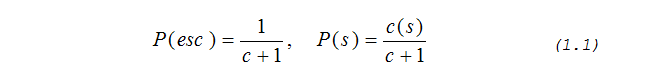
где с – суммарная накопленная частота текущего контекста, а с(s) – накопленная частота символа s в текущем контексте. Подробнее о накопленной частоте символа и суммарной накопленной частоте говорится ниже, в разделе «Кодирование вероятностей».
Метод PPMB предлагает вычислять вероятность появления кода ухода как отношение числа различных символов в данном контексте к частоте этого контекста. Чтобы суммарный вес модели при наличии кода ухода не изменялся, из его частоты следует вычесть единицу при расчете вероятности появления символа. По методу РРМВ имеем:
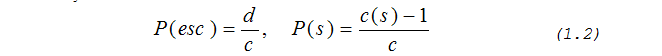
где d – число уникальных (неповторяющихся) символов, встретившихся с данным контекстом. Это число может учитывать исключение символов, о котором речь пойдет чуть ниже.
Более эффективный метод был предложен Э. Маффатом в работах [3] и [4]. Этот метод называется метод РРМС и является логическим продолжением метода РРМА, но, в отличие от последнего, он считает частоту кода ухода равной не единице, а числу уникальных символов, встретившихся с данным контекстом. Вероятности согласно этому методу будут вычисляться следующим образом:
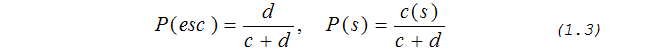
Следующий шаг в улучшении точности вычисления кода ухода был предложен П. Говардом в [5]. Этот метод называется метод РРМD и является развитием метода PPMС. Согласно ему при появлении нового символа в текущем контексте величины счетчиков для кода ухода и обычного символа должны быть увеличены не на единицу, а на ½, чтобы суммарный вес модели не изменился. Получаем:
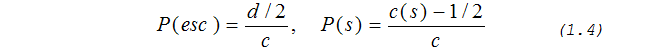
Cсуществуют и другие методы вычисления кода ухода, например, можно найти информацию о PPMP, PPMX и PPMXC [6], но они хорошо работают только для специфических типов исходной информации, а существенного улучшения компрессии в общем случае не дают.
Автор данной работы предлагает свой оригинальный метод вычисления кодов ухода. Этот метод учитывает информацию, полученную в текущем контексте от вышестоящих его контекстов, но при этом этот метод достаточно прост и не требует ни дополнительной памяти, ни сложных многоступенчатых вычислений. Этот метод является дальнейшим развитием метода РРМD, и поэтому назван автором РРМD+ (РРМD плюс или PPMDp). Согласно этому методу код ухода следует считать по формуле:
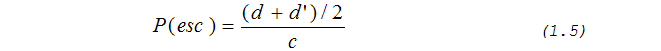
Здесь d’ – число неодинаковых символов, которые были исключены на вышестоящих порядках. Если эта величина равна нулю, то это значит, что ни один символ из списка символов текущего контекста, не был исключен. Тогда вычисление вероятностей по методу РРМD+ становится аналогичным вычислению вероятностей по методу РРМD. Это величину можно вычислить как разность между числом всех уникальных символов, встретившихся с текущим контекстом, и тем же числом, но подсчитанным с учетом исключения символов.
Приведенная формула расчета кода ухода явно учитывает влияние вышестоящих контекстных порядков на вероятность возникновения кода ухода на текущем порядке. Ниже будет предложен механизм вычисления вероятности кода ухода по формуле (1.5), а в тестах будет показана его эффективность в сравнении с другими методами.
Существует множество различных методов, не связанных с вычислением кода ухода, позволяющих улучшить компрессию при использовании алгоритма РРМ. Эти методы имеют разную эффективность и ресурсозатраты. Некоторые требуют большого количества памяти для хранения дополнительной информации, некоторые – достаточно комплексных вычислений. В этом разделе описываются только те методы, которые были использованы в представляемой реализации алгоритма РРМ. Они были выбраны экспериментальным путем, по критериям влияния метода на улучшение компрессии, требованиям к дополнительной памяти, а также сложности используемых вычислений.
Одним из наиболее эффективных методов улучшения компрессии является техника исключения символов (exclusion), впервые предложенная в [1]. Она рекомендует оценивать вероятность появления символа на текущем контекстном порядке без учета символов, которые встретились в уже просмотренных более высоких порядках. Поскольку если на этих порядках большой по размеру контекст встречался с другими символами, но был передан код ухода, то эти символы также не появятся с короткими контекстами и, следовательно, на более низких порядках их можно исключить.
Сказанное можно пояснить на примере. Пусть текущим символом является буква «т», а текущий контекст имеет вид «кор», при этом пусть этот контекст до сих пор встречался только с символами «а» и «с». Поскольку комбинация «корт» еще не встречалась, кодировщик должен передать код ухода, уменьшить контекст до «ор» и перейти на более низкий контекстный порядок. На этом порядке нужно оценить символ «т» в контексте «ор», для этого следует выяснить, с какими еще символами встречался данный контекст. Техника исключения говорит, что из этого списка символов следует исключить символы «а» и «с», поскольку на более высоком порядке было уже выяснено, что ни «а» ни «с» не могут следовать за «ор». Поэтому из суммарной частоты появления контекста «ор» следует вычесть частоты его появления с этими символами. Это увеличивает оценку вероятности появления символа «т» на этом контекстном порядке и следовательно, уменьшает затраты на его кодирование.
Техника исключения при обновлении (update exclusion) рекомендует при обновлении моделей контекстных порядков после кодирования очередного символа включать в обновление только контекстные порядки, начиная с того порядка, где произошло кодирование и вышестоящие порядки, тем самым лишая счетчики символов нижестоящих порядков каких бы то ни было изменений. По разным оценкам это дает выигрыш в компрессии в 1-3% и немного ускоряет работу компрессора.
Шаг изменения счетчиков частоты тоже не обязательно должен быть единичным. Эксперименты показали, что использование шагов с весовым коэффициентом >1 улучшает компрессию.
Другой метод улучшения компрессии связан с выбором начального контекстного порядка. По классической схеме, в начале кодирования в алгоритме РРМ выбирается максимальный контекстный порядок, и кодирование каждого символа начинается с этого порядка, и далее компрессор спускается к меньшим порядкам, если символ не может быть закодирован. Если правильно предсказать, с какого контекстного порядка, меньшего или равного максимальному порядку, стоит начинать компрессию для каждого символа, то можно уменьшить число посылаемых на кодирование кодов ухода. Этот механизм называется механизмом оценки локального порядка (Local Order Estimation or LOE). Существует несколько реализаций этого механизма, которые эвристическим путем выбирают некий критерий, по которому ведут оценку каждого контекстного порядка для выбора стартового. В предлагаемой реализации алгоритма РРМ используется достаточно простой метод LOE: для порядка, на котором произошло успешное кодирование символа, вычисляется коэффициент, зависящий от вероятности появления символа на этом уровне, который и является критерием оценки. Тот порядок, который на текущий момент имеет наибольший коэффициент в сравнении с другими и является предпочтительным. В соответствующем разделе будет представлена формула вычисления этого коэффициента, а в тестах будет показано, как эта реализация LOE влияет на степени сжатия.
Еще одним методом улучшения компрессии является прибавление дополнительного веса к счетчику частоты при его инициализации. Обычно при инициализации счетчика ему задают начальную частоту, равную выбранному шагу изменения частоты. Эксперименты показали, что если при обновлении контекстных порядков, выше того, на котором произошло кодирование, при инициализации счетчиков частоты, связанных с этим символом, к ним прибавить дополнительный вес, то это положительно скажется на компрессии. Величина дополнительного веса зависит от вероятности появления этого символа на том порядке, где он был закодирован. Чем больше эта вероятность, тем больше должен быть прибавляемый вес. В предлагаемой реализации для расчета величины дополнительного веса счетчика инициализации используется коэффициент, вычисляемый в LOE.
Нельзя не упомянуть еще об одном методе, который позволяет заметно улучшить точность вычисления кода ухода почти для всех типов исходной информации. Этот метод называют методом вторичной оценки кода ухода (Secondary Escape Estimation or SEE). Он также основывается на предположении о схожести моделей распределения вероятностей символов на разных контекстных порядках. Его особенностью является то, что он вычисляет вероятности кодов ухода адаптивно, используя статистику вышестоящих контекстных порядков для расчета кода ухода у нижестоящих порядков. Одной из первых реализаций такого подхода был метод РРМZ [7], другой известной реализацией является метод, предложенный Дмитрием Шкариным в его компрессоре PPMd [8]. Компрессор РРМd является одним из лидеров по степени сжатия данных среди всех реализаций алгоритма РРМ, и во многом это происходит благодаря использованию оригинального метода SEE. Этот метод улучшения сжатия не был использован в предлагаемой реализации алгоритма РРМ. Автор этой работы не смог создать приемлемый вариант реализации SEE, взаимодействие которого с другими применяемыми методами улучшения компрессии положительно бы сказалось на степени сжатия для различных типов данных. И тем не менее, в предлагаемой реализации алгоритма РРМ оставлена возможность подключения механизма SEE для возможного последующего использования.
Одним из важных вопросов для кодека, построенного на базе алгоритма РРМ, является то, каким образом будут кодироваться вероятности символов, которые он вычисляет. Для кодирования вероятностей, будь то вероятности появления символа или вероятности кода ухода, в кодеках на базе РРМ используются различные алгоритмы, например, арифметическое сжатие, кодирование по методу Хаффмана и другие. Но наибольшую популярность для кодирования вероятностей в РРМ получил интервальный кодировщик (range coder). Он является разновидностью арифметического кодировщика, но в отличие от последнего оперирует интервалами частот и байтам. Использование байтов вместо битов существенно улучшает скорость кодирования/декодирования при незначительных (порядка 1%) потерях в плотности сжатия. Кроме этого, использовать интервальный кодировщик с РРМ-алгоритмом очень удобно, поскольку такие величины, как накопленная частота символа и суммарная накопленная частота всех символов могут быть легко определены на любом порядке РРМ-модели.
Для кодирования символов интервальный кодировщик должен имеет интерфейс подобный этому:
void encode_freq(unsigned long sy_f, // частота символаunsigned long cump, // накопленная частота символаunsigned long tot_cump); // общая накопленная частота |
Накопленная частота символа есть суммарная частота всех символов, пришедших на кодирование до этого символа. Суммарная накопленная частота – это сумма частот всех уже закодированных символов.
Рассмотрим пример. Пусть необходимо закодировать символ 'и', пусть при этом последовательность появления символов выглядит так (в скобках указывается частота их появления): 'в’(2),’а’(4),’л’(3),’и’(2),’т’(3),’р’(1). Пусть кодирование идет по методу РРМС. Тогда частота кода ухода равняется числу уникальных символов, пришедших на кодирование, которое для данного примера равно 6. На рисунке 1 показано как при этом будет выглядеть кодирование символа 'и'.
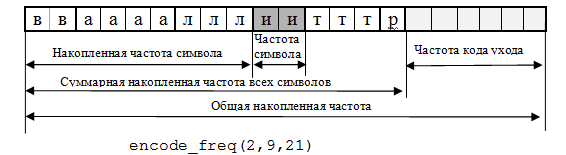
Рисунок 1. Кодирование символа
Пусть следующим после символа 'и' необходимо будет закодировать символ 'c', который еще ни разу не встречался. В этом случае кодировщик будет вынужден кодировать код ухода, поскольку он не обладает никакой информацией об этом символе. С учетом обновления модели на предыдущем шаге кодирование кода ухода будет выглядеть так, как показано на Рисунке 2.

Рисунок 2. Кодирование кода ухода
При декодировании символа необходимо знать только накопленную частоту, которую и выдает интервальный кодировщик. Функция декодирования интервального кодировщика имеет интерфейс подобный этому:
unsigned long decode_freq(unsigned long tot_cump); |
Необходимо послать на вход этой функции общую накопленную частоту, которая легко считается как сумма частот всех пришедших символов и частоты кода ухода. Если возвращаемое значение накопленной частоты больше суммарной накопленной частоты всех символов, то интервальный кодировщик вернул код ухода. Если эта частота меньше этого значения, то выданная кодировщиком частота – это накопленная частота символа. Сам символ находится путем последовательного суммирования частот всех символов в порядке их появления до тех пор, пока сумма не превысит величины, полученной от интервального кодировщика. Тот символ, чья накопленная частота при суммировании сравняется с величиной, полученной от кодировщика, и есть искомый символ.
После определения символа необходимо обновить декодер, чтобы он мог перейти к другому интервалу. Функция обновления аналогична функции кодирования символа и имеет интерфейс:
void decode_update(unsigned long sy_f, // частота символаunsigned long cump, // накопленная частота символаunsigned long tot_cump); // общая накопленная частота |
Рассмотрим пример кодирования согласно алгоритму РРМ порядка 5, по методам вычисления кодов ухода D и D+, с использованием исключения символов, исключения при обновлении и шагом изменения частоты равном единице. В таблице 1.1 приведен пример такого кодирования. В качестве теста взята строчка «и невозможное возможно, дорога долгая легка» из стихотворения А. Блока «Россия».
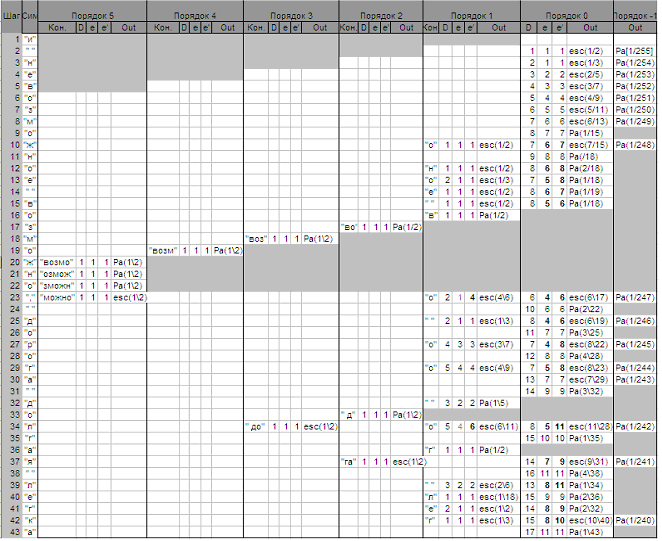
Таблица 1. Пример кодирования по методам РРМD и РРМD+.
В Таблице 1 показано кодирование по шагам для каждого символа исходного текста. Серым цветом закрашены порядки, которые исключаются из обновления после кодирования очередного символа. В поле «Кон.» указывается текущий контекст, в поле «D» – число различных символов, встретившихся в текущем контексте. В полях «e» и «e'» даются значения частоты кода ухода, вычисленные по методу D и D+ соответственно. В поле «Out» сообщается о том, что было подано на частотный кодировщик: если «esc», то была передана вероятность кода ухода, а если «Pa» – вероятность символа. В скобках указывается вероятность передачи кода ухода или символа как отношение их частот к общей накопленной частоте.
Кодирование идет от старших порядков к младшим. Если контекст появляется в первый раз, то происходит переход на другой порядок без всякого кодирования. Если текущий контекст уже встречался, но с данным символом он появился впервые, на кодирование выдается код ухода и идет переход к другому порядку. Если текущий контекст уже встречался с данным символом, то происходит кодирование последнего. После чего идет обновление всех порядков, начиная с того, где произошло кодирование символа.
Первый символ не кодируется, а передается в выходной поток, при этом обновляются только порядки order0 и order(-1). Кодирование следующего символа начинается с 1-го порядка, а следующего за ним со 2-го, и так далее, пока число обработанных символов не сравняется с порядком модели РРМ, то есть пяти. Далее кодирование всех символов начинается с этого наибольшего порядка модели.
В таблице жирным шрифтом помечены отличия частот кодов ухода, вычисленных по методам D и D+. Можно заметить, что частоты кодов ухода, вычисленных по методу D+, всегда равны или больше кодов ухода, вычисленных по методу D.
Этот пример текста размером 43 байта при использовании метода D сжимается до 38 байт, а по методу D+ – до размера 37 байт, при кодировании с использованием интервального кодировщика. Этот пример показывает преимущество применения метода D+ перед методом D даже на небольших по размеру фрагментах текста.
Под кодеком будем понимать программное обеспечение, реализующее тот или иной алгоритм кодирования и соответствующий ему алгоритм декодирования.
Далее идет описание реализации не просто РРМ кодека, а набора модулей, с помощью которых можно сконструировать множество РРМ-подобных кодеков. Эти модули дают возможность конструировать кодеки с произвольным максимальным порядком контекстной модели, вплоть до 10-го, выбирать формулы для вычисления кода ухода, ограничивать размеры используемой памяти, тестировать различные методы, улучшающие компрессию. Все модули кроссплатформенные, реализованы в виде шаблонов независимых друг от друга классов, написанных на языке программирования С++. Эти шаблоны образуют своего рода конструктор РРМ-подобных кодеков, а их модель построения сходна с архитектурой стандартной библиотеки шаблонов STL языка С++.
Главным достоинством такого подхода является высокая гибкость, поскольку она дает возможность собрать на базе алгоритма РРМ свой собственный кодек, отвечающий нуждам конкретной предметной области. При этом можно как использовать классы, входящие в представленный набор шаблонов, так и создавать свои собственные. Например, построить кодек, который не включает некоторые контекстные порядки, или подобрать свою формулу вычисления кода ухода, хорошо работающую с определенным типом исходных данных. Чтобы это осуществить, нужно всего лишь подменить соответствующие шаблоны предлагаемой реализации РРМ на новые, соблюдая при этом требования интерфейса.
Набор подставляемых шаблонов для конструирования РРМ-кодировщика объединен в библиотеку под названием РРМtc (ПэПэЭмТиСи). Все файлы, где реализованы модули этой библиотеки, имеют префикс «tc». Исходный код библиотеки распространяется под лицензией MIT License [9] как свободное программное обеспечение и может быть встроен в другие проекты или использоваться для построения отдельного независимого приложения.
Модель РРМ, предлагаемая библиотекой РРМtc, состоит из двух частей: модели вычислений ключевых параметров алгоритма и модели хранения статистической информации.
У модели вычисления задача только одна – достижение высокой плотности компрессии всего алгоритма. В нее входят следующие модули:
От модели хранения информации зависит то, какая и как статистическая информация будет храниться в памяти, и насколько быстро будет находиться запрашиваемая информации. Таким образом, она отвечает за ресурсоемкость и скорость работы всего алгоритма. В модель хранения информации входят следующие модули:
Шаблоны для построения кодеков различных порядков, использующие поддерживаемые библиотекой PPMtc методы вычисления кода ухода, находятся в файле tc_ppm_codecs.h.
Обобщенный алгоритм реализует основную идею РРМ-кодирования. Он выполнен в виде шаблонного класса T_ppm_generic_algo. Параметрами шаблона этого класса являются типы объектов вероятностного кодировщика и объекта исполнительной модели. Класс T_ppm_generic_algo содержит:
Типы последних двух объектов являются шаблонными параметрами T_ppm_generic_algo. Интерфейс этого класса имеет всего три функции: функцию инициализации, функцию кодирования и функцию декодирования. Функция инициализации должна быть вызвана один раз в начале сеанса кодирования и декодирования. Интерфейсы функций кодирования и декодирования очень схожи и выглядит так:
int encode(T_bytestream& in,int in_size,T_bytestream& out);
int decode(T_bytestream& in,int out_size,T_bytestream& out); |
Каждая функция принимает входной поток байт, а на выход передает заполненный выходной поток байт. При кодировании через входной поток принимается исходная информация, а на выходной поток подается информация, сжатая по алгоритму РРМ. При декодировании наоборот – сжатая информация принимается на вход, а исходная подается на выход. Описание интерфейса байтовых потоков РРМtc дается в соответствующем разделе.
Инициализировать все контекстные порядки. Инициализировать кодировщик вероятностей символов. Инициализировать объект исполнительной модели. Предварительное кодирование. while(входной поток не пуст) { Взять новый символ из потока. Очистить объект исполнительной модели. Установить стартовый контекстный порядок. loop(по всем контекстным порядкам) { Вызвать функцию encode_symbol() текущего порядка. if( не произошло кодирование) Перейти к контекстному порядку, меньшему на 1. else Выйти из цикла. } Обновление моделей всех порядков начиная с того где был закодирован символ и выше. Сдвиг цепочки символов влево на единицу. } Завершение кодирования. |
Вначале идет инициализация всех контекстных порядков, кодировщика вероятностей и ОИМ. Затем идет предварительное кодирование, о котором речь пойдет чуть позже. Каждый символ после чтения обрабатывается в основном цикле. Для каждого нового символа ОИМ устанавливает предпочтительный максимальный порядок, вычисляемый с помощью механизма LOE (или просто используется максимальный порядок, если LOE не задействован), после чего идет попытка закодировать символ, начиная с этого порядка. Если кодирование не произошло, ввиду того что символ не встречался в текущем контексте или данный контекст появился впервые, идет переход на более низкий порядок. Гарантией того, что кодирование рано или поздно произойдет, является порядок order(-1), который кодирует все пришедшие на него символы. После кодирования символа идет обновление моделей всех контекстных порядков, начиная с того, где произошло кодирование и выше, в соответствии с механизмом исключения при обновлении. Если кодирование произошло на order(-1), то обновляются все контекстные порядки. Далее идет изменение контекста символов путем сдвига его влево на один символ и добавления текущего считанного символа в крайнюю правую позицию контекста.
Для нормальной работы функций кодирования необходимо иметь контекст из числа символов, равного установленному максимальному порядку. Поскольку вначале нет полного контекста, вызывается функция предварительного кодирования. Вначале эта функция считывает первый символ потока и обновляет порядки order(-1) и order0. Затем идет процесс кодирования символа, схожий с описанным выше, с той лишь разницей, что стартовый контекстный порядок выбирается по числу символов, считанных из входного потока. Функция предварительного кодирования заканчивает работу, как только число символов контекста достигает максимального размера контекста, установленного для кодировщика РРМ.
При завершении сеанса кодирования необходимо вызвать соответствующую функцию для вероятностного кодировщика, чтобы он смог передать в выходной поток кэшируемые им данные.
Инициализировать все контекстные порядки. Инициализировать кодировщик вероятностей символов входным потоком. Инициализировать объект исполнительной модели. Предварительное декодирование. while(входной поток не пуст) { Очистить объект исполнительной модели. Установить стартовый контекстный порядок. loop(по всем контекстным порядкам) { Вызвать функцию decode_symbol() текущего порядка. if( не произошло декодирование) Перейти к контекстному порядку, меньшему на 1. else Выйти из цикла. } Запись декодированного символа в выходной поток. Обновление моделей всех порядков начиная с того, где был декодирован символ, и выше. Сдвиг цепочки символов влево на единицу. } Завершение декодирования. |
Если в случае кодирования чтение символа из входного потока шло напрямую, а за выходной поток отвечал вероятностный кодировщик, то при декодировании, наоборот, чтением из входного потока занимается вероятностный кодировщик, а запись символа идет в выходной поток напрямую, сразу после его декодирования. Все остальное очень похоже на алгоритм кодирования, только вместо функции encode_symbol(), вызывается функция decode_symbol(), а вместо «предварительное кодирование» и «завершение кодирования» стоят, соответственно, «предварительное декодирование» и «завершение декодирования».
Исходя из представленного псевдокода, можно сформулировать требования, предъявляемые к интерфейсу классов, описывающих модели контекстных порядков. Они должны иметь функции инициализации, кодирования, декодирования и обновления модели. ОИМ согласно этому псевдокоду должен иметь функции инициализации, очистки и установки стартового порядка. Последняя функция необходима для реализации механизма LOE. Поскольку ОИМ также вызывается моделями контекстных порядков, то этот список интерфейсных функций неполон. О других функциях ОИМ будет рассказано в соответствующем разделе.
ОИМ – это объект, который взаимодействует с моделями всех контекстных порядков, являясь связующим звеном между ними. Основная задача этого объекта – это сосредоточить в себе все основные вычисления РРМ кодека. Объединение всех вычислений в одном объекте дает возможность подобрать соответствующий ОИМ для конкретных целей. То какой объект исполнительной модели используется для построения кодека, зависит то, какие методы улучшения компрессии в нем будут задействованы, а, следовательно, насколько хорошо этот кодек будет сжимать данные. Наряду с максимальным порядком модели, он является вторым ключевым параметром, характеризующим кодек в РРМtc. ОИМ реализуют следующие механизмы:
В зависимости от варианта поддержки перечисленных выше механизмов библиотека РРМtc предлагает несколько различных реализаций этого объекта.
Все реализации ОИМ, предлагаемые библиотекой PPMtc, поддерживают механизм исключений. Для этой цели объект исполнительной модели содержит три интерфейсные функции:
void exclude(unsigned char c);
bool is_excluded(unsigned char c);
bool excl_occurred(); |
Первая функция исключает указанный символ, вторая проверяет, был ли исключен заданный символ, а третья сообщает, произошло хотя бы одно исключение любого символа в вышестоящих контекстах. Последняя функция применяется для увеличения скорости работы при кодировании/декодировании, поскольку при отсутствии исключений нет необходимости суммировать частоты для нахождения накопленной частоты символа и общей накопленной частоты.
Простейшей реализацией механизма исключений на уровне ОИМ является использование массива байт, где каждый индекс соответствует символу. Вначале массив заполняется нулями, и если требуется исключить символ, то соответствующему элементу массива присваивается ненулевое значение. Проблемой этого подхода является вынужденное обнуление массива исключений для каждого символа, считанного из входного потока, что негативно сказывается на производительности всего алгоритма. Поэтому используется несколько более продвинутый механизм, когда используется внутренний счетчик, а массив исключенных символов содержит двухбайтовые значения (можно использовать и 4 байта, но на это уйдет в два раза больше памяти). Каждый элемент массива хранит не признак исключения соответствующего символа, а текущее значение внутреннего счетчика. Когда вызывается очистка ОИМ вместо обнуления массива исключений, просто увеличивается внутренний счетчик, и только при достижении максимального значения этого счетчика идет обнуление всего массива. При исключении символа в соответствующий элемент массива записывается текущее значение внутреннего счетчика, а проверка на исключение ведется путем сравнения значения элемента массива текущего символа и значения счетчика. Если они равны, то символ исключен. Это позволяет обнулять массив не каждый раз, когда берется новый символ из входного потока, а только после считывания 216-1 символов. Реализация функции проверки возникновения исключения очень простая – она возвращает значение внутренней булевской переменной, которая взводится, если хотя бы один символ был исключен и сбрасывается при очистке ОИМ.
Как уже подчеркивалось, точное вычисление вероятности возникновения кодов ухода является одной из ключевых проблем РРМ, напрямую влияющих на степень компрессии этого алгоритма. В библиотеки PPMtc реализуются следующие методы вычисления кода ухода: метод РРМA (формула 1.1), РРМC (формула 1.3), РРМD (формула 1.4) и РРМD+ (формула 1.5). Метод РРМВ не рассматривается ввиду того, что для него требуется немного другое построение моделей контекстных порядков, чем для других методов, и кроме этого, по степени компрессии этот метод уступает почти всем остальным методам.
Для каждого варианта вычисления кода в библиотеке РРМtc создается свой ОИ. Интерфейс функции вычисления частоты кода ухода для исполняемого объекта выглядит следующим образом:
unsigned long calc_escape(unsigned char sym,
unsigned long cum,
unsigned long excl_cum,
unsigned long def,
unsigned long excl_def); |
Где:
Частота кода ухода, вычисленная с помощью этой функции, используется как при кодировании символа, так и при кодировании кода ухода, поскольку сумма общей накопленной частоты и частоты кода ухода образуют суммарную накопленную частоту, подающуюся на частотный кодировщик.
Таким образом, код ухода с учетом исключений кодируется на каждом контекстном порядке следующим образом:
unsigned long esc = exe.calc_escape(s, cum, excl_cum, def, excl_def);
coder.encode_freq(esc, excl_cum, excl_cum+esc); |
а кодирование символа выглядит так:
unsigned long esc = exe.calc_escape(s, cum, excl_cum, def, excl_def);
coder.encode_freq(symb_freq, symb_cum, excl_cum+esc); |
В библиотеку РРМtc входит набор классов ОИМ, реализующих различные методы вычисления частоты кода ухода. В таблице 2 показывается, как вычисляется частота кода ухода для различных методов и какие ОИМ им соответствуют.
|
Имя класса ОИМ |
Метод |
Метод |
||
|---|---|---|---|---|
|
T_exec_model_PPMА |
PPMA |
|
||
|
T_exec_model_PPMС |
PPMC |
|
||
|
T_exec_model_PPMD |
PPMD |
где
|
||
|
T_exec_model_PPMDp |
PPMD+ |
где
|
Для методов D и D+:
view_count – это общее суммарное число символов, включая повторения, которые пришли на кодирование или декодирование для данного контекстного порядка. Чтобы не хранить эту величину для каждого контекста, тем самым существенно увеличивая расход памяти, данная реализация алгоритма РРМ построена таким образом, что все счетчики частот, включая накопленной частоты, кратны шагу увеличения частоты. Поэтому для подсчета суммарного числа символов будет достаточно разделить суммарную накопленную частоту на установленную величину шага приращения частоты.
f – это целочисленное представление вероятности кода ухода.
calc_factor – это коэффициент округления вероятности кода ухода, который находится эмпирическим путем. Различные эксперименты, проведенные автором, показали, что он может ощутимо влиять на результаты компрессии. Логично было бы принять его кратным степени 2, тогда умножение на этот коэффициент можно было бы заменить операцией сдвига, и тем самым ускорить вычисления, но опыты показали что, например, для тестов Calgary Corpus лучше работают значения, не кратные степени 2.
def – число различных символов, встретившихся с данным контекстом.
Разница между методами D и D+ в том, что для нахождения f в методе D используется число различных символов, встретившихся с данным контекстом def, а в методе D+ к этой величине прибавляется число символов, исключенных на вышестоящих порядках. Эту суммарную величину, обозначенную как def’, можно выразить через параметры функции calc_escape:
def’ = def+(def-excl_def)= 2*def-excl_def |
Таким образом, окончательные выражения для вычисления частоты по методу D+ будут иметь вид:
esc = excl_cump*f/(calc_factor-f); f = (2*def-excl_def) * calc_factor /(2*view_count); |
Тесты показали (см. ниже), что метод вычисления частоты кода ухода по формуле (1.5) при общих равных условиях превосходит по степени сжатия метод D.
Интерфейс ОИМ содержит две функции для поддержки механизма оценки локального порядка. Интерфейс этих функций выглядит следующим образом:
void calc_best_order(int order_ind, // индекс текущего порядка unsigned short freq, // частота символа unsigned long sum); // суммарная накопленная частотаint get_initial_order(); |
Первая функция вызывается при обновлении контекстной модели текущего порядка, только если на этом порядке произошло кодирование символа. Функция по определенному критерию сравнивает текущий порядок с порядками, на которых было произведено кодирование предыдущих символов для выявления наилучшего стартового порядка для последующих символов.
В текущей реализации LOE критерий сравнения определяется как отношение частоты появления символа к общей накопленной частоте по формуле :

где freq – частота появления символа; loe_accuracy – коэффициент округления до целого, находящийся эмпирическим путем; sum – суммарная накопленная частота;
Тот контекстный порядок, который имеет наибольшее значение коэффициента предпочтения, вычисленного по формуле 1.6, устанавливается как стартовый порядок для следующего символа.
Функция get_initial_order() не содержит вычислений, а просто возвращает индекс начального порядка, который наиболее предпочтителен.
Если механизм LOE не используется, то calc_best_order() просто ничего не делает, а get_initial_order() должна возвращать индекс максимального порядка модели.
Описанный выше механизм LOE в библиотеке PPMtc реализован только для объектов исполнительной модели, вычисляющих код ухода по методу РРМD+ – это классы с именами T_exec_model_PPMDp_LOE и T_exec_model_PPMDp_full.
Для поддержки этого метода в ОИМ существует всего одна функция:
unsigned short get_initial_freq(); |
Эта функция при обновлении контекстной модели текущего порядка вызывается, только если символ никогда не встречался с текущим контекстом. Она возвращает начальное значение для частоты нового символа по формуле:
(unsigned short)((float)K/step+step) |
где step – шаг изменения частоты; K – коэффициент предпочтения, вычисленный при подсчете наилучшего стартового порядка в LOE по формуле (1.6).
Если прибавление дополнительного веса к счетчику частоты при его инициализации не используется, функция get_initial_freq() должна возвращать установленный в алгоритме шаг изменения частоты. Этот метод в библиотеке PPMtc поддерживается только классом T_exec_model_PPMDp_full.
Все классы, реализующие различные модели контекстных порядков библиотеки РРМtc, являются шаблонными, а в качестве типов параметров шаблона принимают типы частотного кодировщика и объекта исполнительной модели. Кроме этого, те шаблоны, которые используют связанные списки, имеют еще один шаблонный параметр для определения типа размера указателей списка. Классы моделей контекстных порядков образуют иерархию, которая показана на Рисунке 3.
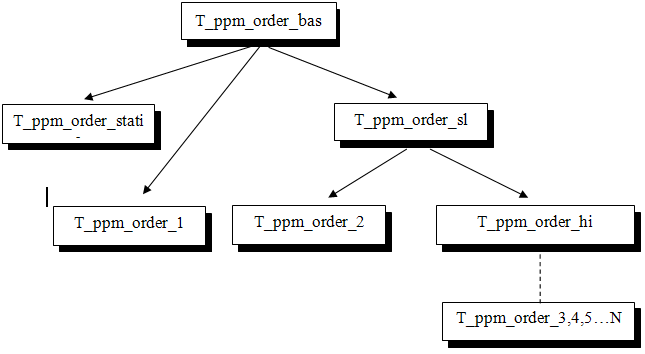
Рисунок 3. Иерархия моделей контекстных порядков в PPMtc
Таким образом, все контекстные порядки являются наследниками базового класса T_ppm_order_base и должны реализовывать его интерфейс, чтобы их можно было использовать в обобщенном алгоритме РРМ. Этот интерфейс выглядит следующим образом:
void init();
bool encode_symbol(unsigned char* bytes,Texec& exe,Tcoder& coder);
bool decode_symbol(unsigned char* bytes,Texec& exe,Tcoder& coder);
void update(unsigned char* bytes,Texec& exe,int order_ind) = 0;
int get_order(); |
Функция инициализации порядка init() должна вызываться только один раз, в начале сеанса кодирования/декодирования перед вызовом любых других методов. Внутри этой функции происходит инициализация всех внутренних переменных соответствующего порядка.
Функции кодировании и декодирования должны возвращать «true», если кодирование текущего символа произошло на данном порядке, и «false» в противном случае. Первым параметром этих двух функций, а также функции update(), идет массив, содержащий текущий контекст. Для каждой модели контекстного порядка гарантируется, что контекст, помещенный в этот массив, не меньше чем сам порядок. Например, на восьмом контекстном порядке гарантируется, что массив содержит восемь символов в данном массиве. Объекты coder и exe – это, соответственно, частотный кодировщик и объект исполнительной модели.
Функция update() отвечает за обновление модели, а функция get_order() возвращает текущий порядок модели.
Каждый порядок (за исключением порядка order_static) хранит информацию обо всех символах, пришедших на этот порядок, а также величину суммарной накопленной частоты и число различных символов. В модели order0 для этих целей используются две переменных, для более высоких порядков это будут массивы или записи. Каждый порядок (за исключением порядка order_static и order0) хранит информацию о тех контекстах, которые ему встретились.
if(были исключения на вышестоящих порядках)
{
Подсчитать суммарную накопленную частоту и число различающихся символов, с
учетом исключений.
}
Вычислить кода ухода и общей накопленной частоты.
Искать, появлялся ли символ с текущим контекстом.
if(символ с текущим контекстом уже встречался)
{
Вычислить накопленную частоту символа.
Кодировать символ с помощью ЧК, используя общую накопленную частоту,
накопленною частоту и частоту символа.
Сообщить о том, что был закодирован символ.
}
else
{
Кодировать с помощью ЧК символ кода ухода, используя вычисленную общую
накопленную частоту, суммарную накопленную частоту и частоту кода ухода.
Исключить все символы, которые встретились с текущим контекстом.
Сообщить о том, что был закодирован код ухода.
} |
if(были исключения на вышестоящих порядках)
{
Подсчитать суммарную накопленную частоту и число различающихся символов, с
учетом исключений.
}
Вычислить кода ухода и общей накопленной частоты.
Получить накопленную частоту от декодера.
if( эта частота меньше суммарной накопленной частоте)
{ // получили от декодера символ
Найти символ по его накопленной частоте.
Обновить декодер, используя частоту найденного символа, его накопленную
частоту и вычисленную общую накопленную частоту.
Сообщить о том, что был декодирован символ.
}
else
{ // получили от декодера код ухода
Обновить декодер, используя частоту код ухода, вычисленную общую суммарную
накопленную частоту.
Исключить все символы, которые встречались с текущим контекстом.
Сообщить о том, что был декодирован код ухода.
} |
Реализация алгоритма обновления модели, которая находится в функции update(), для порядков, использующих связанные списки, отличается от тех, где эти списки не используются.
if(символ еще не встречался)
{
Запросить величину начальной частоты символа.
Установить полученную частоту.
Увеличить суммарную накопленную частоту.
Увеличить общее число символов на единицу.
}
else
{
Вычислить стартовый порядок с помощью LOE.
Увеличить частоту символа и общую накопленную частоту на один шаг.
if(частота символа превышает установленное ограничение)
Масштабировать счетчики частот.
} |
if(данный порядок при кодировании/декодировании не вызывался из-за LOE)
Установить все кэшируемые указатели.
if(контекст еще не встречался)
{
Запросить величину начальной частоты символа.
Создать новый контекст.
Создать новый нод символа, присваивая ему начальную частоту.
if(если памяти для нового контекста или символа нет)
Удалить редкие контексты и связанные с ними коды символов.
Поместить указатель на символ в контекст.
Поместить указатель на новый контекст в хеш-таблицу.
}
еlse
{
if(символ встречался в данном контексте)
{
Вычислить стартовый порядок с помощью LOE.
Увеличить частоту символа и общую накопленную частоту в данном
контексте на один шаг.
if(частота символа превышает установленное ограничение)
Масштабировать счетчики частот.
}
else
{ //контекст присутствует, но с данным символом он еще не встречался
Запросить величину начальной частоты символа.
Создать новый нод символа, присваивая ему начальную частоту.
if(если памяти для нового символа нет)
Удалить редкие контексты и связанные с ними ноды символов.
Поместить указатель на символ в контекст.
}
} |
Для определения того, что символ в текущем контексте уже встречался, можно было бы использовать параметр функции, который бы сообщал, в каком из порядков произошло кодирование. Зная эту информацию, можно было бы легко понять, встречался ли данный символ в текущем контексте. Но это работает только в тех случаях, когда механизм LOE не используется, поскольку при наличии LOE может получиться так, что порядок, для которого производится обновление, мог быть просто не вызван, а, следовательно, не была произведена проверка появления символа в текущем контексте. Для решения этой проблемы вводится специальная переменная статуса, которая может принимать значения «FOUND», «NOTFOUND», говорящие о том, был ли найден символ в текущем контексте. Также вводится дополнительное значение «UNDEFINED», говорящее о том, что поиск появления символа в текущем контексте не выполнялся. После обновления модели порядка переменная статуса должна быть установлена в неопределенное состояние. Для этого используется специальный класс T_status_reset, автоматически выводящий в это состояние переменную статуса при выходе из функции update().
Теперь рассмотрим особенности реализации каждого порядка в отдельности.
Порядок order_static – специальный, так как на нем кодирование и декодирование происходит всегда. На этом порядке любой символ может быть закодирован только один раз, поскольку если символ появился дважды, то он будет закодирован уже на более старшем порядке. Самый простой способ реализации order_static – это задание ему плоского или, другими словами, равномерного распределения для всех символов. В этом случае при кодировании частота любого символа будет равна единице, накопленная частота - самому символу, а общая накопленная частота равна размеру алфавита плюс единица, для символа кода ухода.
Для небольшого увеличения сжатия на этом порядке можно слегка усложнить этот алгоритм, введя массив, эмулирующий интервал накопленных частот, отведенный для кодирования символов. Вначале массив заполняется путем присваивания первому элементу массива величины размера алфавита, а каждому следующему элементу – на единицу меньше от предыдущей величины. В результате в элементе с индексом ноль будет храниться общее число символов, в элементе с индексом, равном значению самого символа, будет храниться его нижняя граница, а в элементе на единицу меньше – верхняя. При обновлении модели все элементы массива, начиная от индекса, равного значению символа, и до нулевого элемента, уменьшаются на единицу. В свою очередь, общее число символов, хранящееся в первом элементе массива, тоже уменьшится. При такой организации порядка order_static во время кодирования частота символа будет равняться единице, накопленная частота будет равняться значению символа плюс единица, а общая накопленная частота будет браться из первого элементе массива.
При декодировании для поиска нужного символа по его частоте, полученной из частотного кодировщика, используется двоичный поиск по символам. Сначала берется символ из середины алфавита, нижняя граница символа, взятая из массива, сравнивается с частотой, полученной от кодировщика. Если она меньше, рассматривается правый интервал, если больше – левый и так далее, пока символ не будет найден.
Этот вариант реализации order_static улучшает компрессию в пределах долей процента, требуя при этом дополнительно 516 байт, и работает чуть медленнее, чем вариант с плоским распределением вероятностей.
Обе реализации контекстного порядка order_static находятся в файле tc_ppm_order_static.h.
На порядке order0 нет контекста, и он оперирует только частотой появления символов. Для этих целей на этом порядке хранится массив частот всех символов, а также один счетчик для суммарной накопленной частоты и один счетчик числа различных уникальных символов. Алгоритм работы функций кодирования, декодирования и обновления для этого порядка был представлен в псевдокоде выше. Кроме этих функций, он содержит дополнительную функцию масштабирования rescale(). Эта функция вызывается при достижении накопленной частотой символа максимально допустимого значения, взятого из настроек кодека. Предлагаемая реализация этой функции уменьшает значения частот символов вдвое. Реализация контекстного порядка order0 находится в файле tc_ppm_order_0.h.
Реализация модели контекстного порядка order1 очень схожа с реализацией порядка order0. Наличие ненулевого контекста на порядке order1 приводит к увеличению размерности переменных, которые использовались на порядке order0. Так, массив частот становится двухмерным, а переменные для хранения числа символов и накопленной частоты – одномерными массивами. Индексируя эти два массива числовым значением контекста, который на этом порядке представлен одним символом, можно получить соответствующую информацию для этого контекста. Первый индекс массива частот относится к контексту, второй – определяет символ. На этом все принципиальные отличия порядков order1 от order0 заканчиваются. Реализация контекстного порядка order1 находится в файле tc_ppm_order_1.h.
Если подняться еще на шаг выше, до контекстного порядка order2, впервые встретится ситуация, когда для хранения информации о символах и контекстах уже нельзя использовать массивы фиксированной длины ввиду резко возрастающих затрат на хранение этих данных. Есть несколько вариантов решения этой проблемы, например, наиболее часто для хранения и поиска данных в РРМ применяются различные типы деревьев, так, например, в [10] для этих целей используется суффиксное дерево. Но в библиотеке PPMtc используется другой подход, в котором применяются связные списки и хеш-таблицы. Использование хеш-таблиц позволяет существенно уменьшить время поиска контекстов, а чтобы эта таблица не занимала очень много места в памяти, в PPMtc используется двухбайтовые хеш-ключи.
Для описания символа создается структура, описывающая символ. Она содержит сам символ, его частоту и дополнительное поле, необходимое для создания связанного списка символов и указывающее на следующий элемент в списке.
template<typename T>
struct T_symbol_node
{
unsigned char byte; //символ
T_freq freq; //его частота
T next; //указатель следующего элемента списка
}; |
В библиотеке PMMtc для создания связных списков не используются указатели в терминах языка C++. Вместо них используются индексы, поскольку все элементы списков хранятся в индексных контейнерах, описание которых будет дано в соответствующем разделе.
Последний элемент списка структур символов в поле next должен хранить константу bad_ptr, характеризующую плохой (не взведенный) указатель. Обычно эту константу принимают равной максимальному допустимому значению используемого типа размера списка.
Структура описания символа является шаблоном, зависящим от типа размера списка. Указатель на следующий элемент списка имеет этот тип. Он может быть как 16-, так и 32-битным, и устанавливается в зависимости от принятого числа допустимых элементов списка.
Создать структуру символа, с заданной начальной частотой.
Добавить структуру символа в контейнер символов.
if (контейнер переполнен)
{
Вызвать функцию очистки контейнеров.
Повторить попытку добавления символа в контейнер.
} |
Структура, описывающая контекст, также является шаблоном типа размера списка и содержит начало списка символов, с которыми встречался данный контекст, их суммарную накопленную частоту и число неодинаковых символов.
template<typename T>
struct T_cntxt_info
{
T symb_list; // указатель на начало списка T_symbol_node
T_cump max_cump; // суммарная накопленная частота
T_def defined_bytes; // число различных символов
}; |
Структура описания контекста может и не использоваться. Пример такого случая – порядок order2. Для более высоких порядков структуры описания контекста объединяются в список, для чего в библиотеке PPMtc используется шаблон T_cntxt_info_hi, добавляющий к структуре описания контекста указатель на следующий элемент списка. Он выглядит следующим образом:
template<typename T,typename O>
struct T_cntxt_info_hi: public T_cntxt_info<T>
{
T next; // индекс следующего элемента списка
O cntxt; // контекст
}; |
Все порядки, которые используют списки символов, являются дочерними классами от базового класса T_ppm_order_sl. От класса T_ppm_order_base этот класс наследует базовый интерфейс контекстных порядков. К списку шаблонных параметров в него добавляется еще тип размера списков. Класс T_ppm_order_sl содержит только одни контейнер – контейнер записей, содержащих связанный список структур описания символов. Он также содержит механизм удаления структур описания.
Связанные списки имеют одну проблему – время поиска элемента списка линейно зависит от размера самого списка. Чтобы не пробегать список повторно при повторном поиске элемента списка, в классе T_ppm_order_sl предусмотрен механизм кэширования результата последнего поиска. Переменная класса m_cached_node_ptr содержит либо указатель на найденную структуру символа, либо на последний элемент списка. Это позволяет избежать повторного чтения списка, а значит, в целом улучшить скорость работы с ним.
Класс T_ppm_order_sl декларирует две новые интерфейсные функции, которые должны реализовать все дочерние классы:
virtual
bool get_context_info(unsigned char* bytes,Texec& exe,
T_cntxt_info<T>& cntxt_info) = 0;
virtualvoid clear_contexts(T excl_cntx) = 0; |
Функция get_context_info() должна осуществить поиск контекста, и если он будет найден, вернуть его запись. Функция clear_contexts() реализует алгоритм освобождения наименее востребованных контекстов.
Установить начальное значение минимально допустимой величины накопленной частоты. while(пока число освобожденных контекстов меньше числа требуемых) { loop (по всем структурам хеш-таблицы) { if(накопленная частота контекста<минимально допустимого) { Удалить символы из контекста. Удалить сам контекст. Увеличить на единицу счетчик удаленных контекстов. } } Увеличить на шаг минимально допустимое значение накопленной частоты. } if(число освобожденных контекстов > ограничение) { Увеличить в полтора раза число требуемых для удаления контекстов для следующего вызова функции удаления контекстов. if(число контекстов для удаления > разрешенных для удаления) Присвоить число контекстов для удаления числу разрешенных для удаления. } |
Увеличение в полтора раза числа удаляемых контекстов для следующего вызова этой функции позволяет улучшить производительность, поскольку существенно уменьшает число вызовов функции очистки контекстов. Параметры, определяющие начальные и максимальные значения, необходимые для освобождения контекстов, подбираются экспериментальным путем. Вместе со структурами описания контекстов удаляются и связанные с ними списки структур описания символов.
Кроме двух интерфейсных функций класс T_ppm_order_sl содержит три утилитарные функции:
T get_ptr(unsigned char* bytes,T symb_list,bool& found); T exclude_symbols(T start,Texec& exe); int remove_symb_nodes(T start); |
Функция get_ptr() пробегает весь связанный список записей символов, сообщает о том, был ли найден символ и возвращает указатель (еще раз следует подчеркнуть, что в данной реализации используются не реальные С++-указатели, а индексы по контейнеру записей) либо на структуру найденного символа, либо на последний элемент связного списка.
Функция exclude_symbols() необходима для поддержки механизма исключения символов, встретившихся на высоких контекстных порядках при кодировании кода ухода. Эта функция исключает все символы заданного связного списка, вызывая ОИМ.
Функция remove_symb_nodes() удаляет заданную структуру символа из списка и восстанавливает корректные указатели в списке. Эта функция необходима при вызове механизма очистки контейнеров.
Полную реализацию шаблона класса T_ppm_order_sl можно найти в файле tc_ppm_order_sl.h.
В модели порядка order2 контексты хранятся в виде массива из 216-1 элементов. Доступ до двухсимвольного контекста осуществляется по хеш-ключу, который есть простая комбинация объединения этих двух символов. Вначале все структуры таблицы заполняются нулями, при поиске контекста проверяется на ноль только одно поле контекста – значение числа различных символов. Если это значение не нулевое, функция get_context_info() заполняет контекстную структуру. Реализация контекстного порядка order2 находится в файле tc_ppm_order_2.h.
Все контекстные порядки, начиная с order3, образуются на базе шаблонного класса T_ppm_order_hi, который является наследником базового класса T_ppm_order_sl. Реализация его находится в файле tc_ppm_order_hi.h. Но кроме связанных списков символов, класс T_ppm_order_hi содержит связанные списки контекстных записей, а указатели на начало этих списков хранятся в хеш-таблице размером 216-1 элементов.
Связанные списки структур описания контекста нужны потому, что для больших контекстов (более двух символов) довольно часто возникает ситуация, когда два различных контекста имеют один и тот же хеш-ключ. В этом случае структуры описания контекстов объединяются в связный список, а поиск нужной контекстной записи будет разделен на две части – быстрый и медленный. Быстрый поиск выполняется путем вычисления хеш-ключа контекста и индексирования этим ключом хеш-таблицы для нахождения начала связанного списка структур описания контекста, имеющих одинаковый хеш-ключ. Вторая часть поиска структуры описания контекста – это посимвольное сравнения контекста с контекстами из структур, объединенных в список. Чем длиннее список структур описания контекстов, тем медленнее поиск. Поэтому важно, чтобы функция создания хеш-ключей имела равномерное распределение, тогда длина связных списков будет приблизительно одинаковой, не будет очень длинных списков, поиск по которым резко замедляет работу всего алгоритма.
Использование хеш-таблицы в сочетании со связными списками позволяет строить на базе класса T_ppm_order_hi модели контекстов сколь угодно большого порядка – главное только определить, как эти контекстные порядки будут вычислять хеш-ключ, величина которого ограничивается в классе T_ppm_order_hi двумя байтами.
Все функции вычисления ключа возлагаются на дополнительный шаблонный параметр класса T_ppm_order_hi. Объект на базе этого типа должен реализовывать следующие функции:
Библиотека РРМtc предлагает все реализации объектов вычисления ключей контекста, начиная с 3-го и заканчивая 10-ым, но можно по тому же принципу создать и другие объекты вычисления ключей более высоких порядков. Эти классы имеют имя T_cN, где N – порядок контекста. В качестве функции вычисления хеш-ключа автором были протестированные несколько популярных функций. Наилучшие результаты по скорости поиска в комбинации «хеш-таблица - связанный список» показал известный алгоритм djb2, который можно найти в [11].
При инициализации хеш-таблицы все указатели на начало списков заполняются значением bad_ptr. При создании нового контекста вызывается функция create_context(), которая формирует структуру описания контекста и записывает ее в контейнер структур, а указатель на эту структуру помещается в соответствующее место в хеш-таблице. Если контейнер структур контекстов переполнен, то вызывается функция clear_contexts(), которая удаляет структуры, имеющие накопленную частоту ниже установленной.
Функция get_context_info() осуществляет поиск контекстной записи по вышеописанному двухступенчатому алгоритму. Во время этого поиска все необходимые значения (хеш-ключ, найденный контекст и его предшественник) кэшируются.
Такие функции, как clear_contexts() и reset_cache(), отличаются от соответствующих функций, реализованных в контекстном порядке order2 и классе T_ppm_order_sl, только наличием дополнительного поиска по связанному списку структур описания контекстов.
Полную реализацию шаблона класса T_ppm_order_hi можно найти в файле tc_ppm_order_hi.h, а реализацию классов вычисления хеш-ключа для контекстных порядков с 3-го по 10-ый – в файле tc_ppm_order_345678910.h.
Для хранения структур описания символов и контекстов в PPMtc применяются специальные индексные контейнеры. Все контейнеры создаются с использованием универсального шаблона (в терминах C++) класса, который имеет два параметра – тип структуры хранения и тип базового размера контейнера. Последний параметр может иметь тип либо unsigned short либо unsigned long. Он задает максимально возможное число записей в контейнере (216-1 и 232-1 соответственно) и определяет тип всех рабочих переменных контейнера. Контейнеры имеют стандартный набор функций: добавление и удаление записи, проверка корректности индекса, возврат текущего размера контейнера и его очистка.
Контейнер обладает емкостью, которая задает число резервируемых в памяти записей для заполнения. Все записи контейнера объединены в один односвязный список. Каждая запись имеет указатель (реализованный как индекс) на следующий элемент. Контейнер содержит переменную, указывающую на индекс начала свободных записей. При удалении какой-либо записи она становится началом списка свободных записей, а ее указателю на следующий элемент присваивается старый указатель первой свободной записи. Связный список позволяет вставлять и удалять записи, не прибегая к перестроению всего контейнера. Такой контейнер работает очень быстро, а наличие у каждой записи добавочного указателя на следующий элемент хоть и требует дополнительных расходов памяти, но отлично подходит для хранения в таком контейнере связанных списков структур описания. Емкость контейнера задается при его создании и может быть как фиксированной, так и динамической.
Для фиксированных контейнеров при достижении заданной емкости контейнер перестает добавлять записи и выдает ошибку в виде недопустимого индекса bad_ptr. Значение этого индекса есть максимально возможное целое число, определяемое базовым типом размера контейнера. Последняя свободная запись содержит в поле указателя на следующий элемент значение bad_ptr. По этому признаку определяется, что контейнер переполнен. Сообщение о переполнении контейнера необходимо, если на использующие его алгоритмы наложены ограничения по памяти. Оно заставляют такие алгоритмы предпринимать действия по удалению части записей из контейнера.
При достижении максимальной емкости контейнера в нефиксированном контейнере происходит динамическое увеличение емкости контейнера путем заказа новой памяти, размером в полтора раза больше текущей, и копированием в нее существующих записей. Поскольку вся работа контейнера ведется с индексами записей, а не с их С++-указателями, никаких проблем с доступом к записям, физически расположенным уже в другой памяти, в этом случае не возникает. Емкость динамического контейнера не может превышать по значению величины bad_ptr.
Очистить контейнер можно двумя способами: либо просто удалив все записи, при этом не меняя его текущую емкость, либо уменьшив ее до заданной величины. Последнее хорошо работает во время тестирования, когда нужно точно определить размер памяти, запрошенной для каждого теста. Реализацию индексного контейнера можно найти в файле tc_entry_cnt.h.
Байтовые потоки поддерживают интерфейс обмена байтовыми данными. Классом, представляющим их в библиотеке PPMtc, является абстрактный класс T_bytestream. Он имеет набор функций для получения байта информации из входного потока, а также функций передачи отдельных байтов в выходной поток. Класс T_bytestream является базовым классом для класса T_file_bytestream, реализующего обмен данными с файлом на жестком диске, и для класса T_buff_bytestream, осуществляющего буферизованный обмен данными, находящимися в памяти. Поскольку функции кодирования и декодирования в библиотеке PPMtc используют T_bytestream-потоки, это позволяет вести обмен данными четырьмя различными способами: память-память, память-файл, файл-файл, файл-память. Реализацию всех потоковых классов можно найти в файле tc_bytestream.h.
В библиотеке PPMtc используются пять параметров настройки кодека:
Последние три параметра напрямую относятся к настройкам описанной выше функции удаления контекстов clear_contexts(). При создании кодека все параметры настройки передаются в структуре T_ppm_settings, а в самом кодеке хранятся в структуре T_ppm_properties, которая является производной от T_ppm_settings. При копировании данных из T_ppm_settings в T_ppm_properties осуществляется контроль значений всех настроек для недопущения ошибочных значений, а также перевод некоторых настроек в удобную для использования форму.
Объединяя описанные выше классы, можно сконструировать шаблон кодека определенного порядка, вычисляющего код ухода по одному из вышеописанных методов и использующему те или иные методы улучшения компрессии. Параметрами шаблона кодека являются:
Рассмотрим пример построения шаблона кодека максимального контекстного порядка, равного четырем. Его можно описать следующим образом:
template<typename T,typename Tcoder,typename Texec >
class T_ppm_codec_order4
{
...
}; |
Обозначим:
typedef T_symbol_node<T> T_node; // тип записи символаtypedef T_entry_cnt<T_node,T> T_symb_cnt; // тип контейнера структурсимволаtypedef T_cntxt_info_hi<T,T_c3> T_info3; // тип контекстной // записи 3-гопорядкаtypedef T_entry_cnt<T_info3,T > T_cntx3_cnt;// тип контейнера контекстных// записей 3-го порядкаtypedef T_cntxt_info_hi<T,T_c4> T_info4; // тип контекстной записи // 4-гопорядкаtypedef T_entry_cnt<T_info4,T> T_cntx4_cnt;// тип контейнера контекстных//записей 4-го порядка |
Теперь перечислим объекты, входящие в этот шаблон:
T_symb_cnt m_symbs_o2; // контейнер записей символов 2-го порядка T_symb_cnt m_symbs_o3; // контейнер записей символов 3-го порядка T_symb_cnt m_symbs_o4; // контейнер записей символов 4-го порядка T_cntx3_cnt m_cntxs_o3; // контейнер записей контекстов 3-го порядка T_cntx4_cnt m_cntxs_o4; // контейнер записей контекстов 4-го порядка T_ppm_generic<Tcoder,Texec> m_algo; // объект обобщенного алгоритма T_ppm_order_base<Tcoder,Texec>* m_orders[E_num_orders];// массив контекстных// порядков Tcoder* m_freq_coder; // указатель на частотный кодировщик Texec* m_exec; // указатель на объект исполнительной модели T_ppm_properties m_props; // настройки кодека |
Конструктор шаблона будет выглядеть так:
T_ppm_codec_order4(T_ppm_settings& s,Tcoder* freq_coder,Texec* exec,int cnt_reserve,bool fixed): m_algo(),m_freq_coder(freq_coder),m_exec(exec), m_symbs_o2(cnt_reserve,fixed),m_symbs_o3(cnt_reserve,fixed), m_symbs_o4(cnt_reserve,fixed), m_cntxs_o3(cnt_reserve,fixed),m_cntxs_o4(cnt_reserve,fixed), m_props(s) { // конструирование контекстных порядков //создаем порядок order_static m_orders[0] = new T_ppm_order_static<Tcoder,Texec>( m_props); //создаем порядок order0 m_orders[1] = new T_ppm_order_0<Tcoder,Texec>( m_props); //создаем порядок order1 m_orders[2] = new T_ppm_order_1<Tcoder,Texec>( m_props); //создаем порядок order2 m_orders[3] = new T_ppm_order_2<T,Tcoder,Texec>( m_props,m_symbs_o2); //создаем порядок order3 m_orders[4] = new T_ppm_order_hi<T,Tcoder,Texec,T_c3>(m_props,m_symbs_o3,m_cntxs_o3); //создаем порядок order4 m_orders[5] = new T_ppm_order_hi<T,Tcoder,Texec,T_c4>(m_props,m_symbs_o4,m_cntxs_o4); //инициализируем обобщенный алгоритм m_algo.init(m_orders,E_num_orders,m_freq_coder,m_exec); } |
Параметрами конструктора являются:
Функции кодирования и декодирования для этого шаблона будут выглядеть очень просто:
int encode(T_bytestream& in,int in_size,T_bytestream& out)
{
m_props.reset();
m_algo.encode(in,in_size,out);
return out.get_pos();
}
int decode(T_bytestream& in,int out_size,T_bytestream& out)
{
m_props.reset();
unsigned int start_out = out.get_pos();
m_algo.decode(in,out_size,out);
return out.get_pos()-start_out;
} |
Аналогичным образом можно построить шаблоны кодеков других порядков. Отличаться они будут только наличием или отсутствием контейнеров для хранения структур описания символов и контекстов, а также числом созданных порядков, помещенных в массив m_orders. При этом функции кодирования и декодирования у всех кодеков должны выглядеть идентично, так, как это показано выше.
В библиотеке PPMtc заранее подготовлены все шаблоны кодеков с 1-го и по 10-ый порядок. Их реализацию можно найти в файле tc_ppm_codecs.h. Чтобы не повторять один и тоже код создания порядков, все шаблоны образуют иерархию. Базовым классом является класс T_ppm_codec_base, который содержит только массив контекстных порядков, обобщенный алгоритм и всего два порядка: order_static и order0. Шаблон кодека T_ppm_codec_order1 наследует все данные от T_ppm_codec_base и добавляет к массиву контекстных порядков порядок order1. Шаблон кодека T_ppm_codec_order2 наследует все данные от T_ppm_codec_order1 и добавляет к массиву контекстных порядков порядок order2, и так далее до шаблона кодека 10-го порядка. Те кодеки, которые используют связанные списки, кроме своего порядка добавляют еще соответствующие им контейнеры для хранения этих списков. При помощи библиотеки PPMtc можно создавать свои кодеки, не используя эти заранее подготовленные шаблоны, по примеру конструирования кодека, который был описан в начале данного раздела.
Создание кодека из шаблона кодека выполняется очень просто. Возьмем для примера описанный выше шаблон кодека порядка 4 и построим кодек, который вычисляет код ухода по методу С, имеющий ограничения по размеру контейнера, равное 32К элементов (максимальная число для типа unsigned short), с шагом частоты 3, с максимальной частотой символа 8000, минимальным и максимальным числом удаленных контекстных записей 8 и 2000 соответственно, и с коэффициентом удаления, равным 4.
Объекты, необходимые для создания кодека:
T_ppm_settings s={3,8000,8,2000,4};// настройки кодека
T_rangecoder range; // интервальный кодировщик
T_exec_model_PPMC exec4_C(4,s); //объект исполнительной модели 4-го// порядка, вычисляющий код ухода по методу С. |
Описываем тип кодека:
typedef T_ppm_codec_order4<unsigned short,
T_rangecoder,
T_exec_model_PPMC> Tppm4_C; |
Создаем кодек:
Tppm4_C* codec = new Tppm4_C(s,&range,&exec4_C, 32768,true); |
Кодек создан, теперь можно с его помощью начать кодировать и декодировать данные:
T_file_bytestream in; //входной поток T_file_bytestream out; //выходной потокint plain_file_size, encoded_size; //размер данных до и после кодирования//открываем файл с исходными данными in.open_to_read("test"); //открываем файл для хранения сжатых данных out.open_to_write("test.ppm4"); //получаем размер файла plain_file_size = in.get_size(); //запишем размеры исходного файла в выходной файл out.put_char((unsigned char)(plain_file_size)); out.put_char((unsigned char)(plain_file_size >> 8)); out.put_char((unsigned char)(plain_file_size >> 16)); out.put_char((unsigned char)(plain_file_size >> 24)); //кодирование encoded_size = codec->encode(in, plain_file_size,out); //закрываем байтовые потоки in.close(); out.close(); //декодирование//открываем файл с сжатыми данными in.open_to_read("test.ppm4"); //открываем файл для исходных данных out.open_to_write("test2"); //извлекаем информацию о размере исходных данных plain_file_size = in.get_char(); plain_file_size |= in.get_char()<<8; plain_file_size |= in.get_char()<<16; plain_file_size |= in.get_char()<<24; //декодируем codec->decode(in, plain_file_size,out); //закрываем байтовые потоки in.close(); out.close(); |
С использованием библиотеки PPMtc были построены следующие кодеки:
В кодеках без фиксации числа элементов для базового размера контейнеров используется тип unsigned long, а значит, максимальное число элементов в контейнере не должно превышать 232-1. У кодеков с фиксированным числом элементов PPMD+mеm1, PPMD+mеm2, PPMD+mеm2 для базового размера контейнеров используется тип unsigned short.
Таким образом, общее число РРМ-кодеков, участвующих в тестировании, равняется 79.
Для сравнения кодеков были созданы еще 6 дополнительных кодеков, построенных уже совсем на другом алгоритме кодирования информации. Эти алгоритмы используют преобразование Барроуза-Уилера (Burrows – Wheeler Transform) [12], сокращенно BWT. Оно модифицирует информацию таким образом, что эффективность сжатия информации после этого преобразования значительно возрастает. Таким образом, BWT не сжимает информацию, а подготавливает ее для последующего сжатия. В качестве сжимающего алгоритма для информации, прошедшей преобразование, BWT, как правило, используют не один какой-то определенный алгоритм, а цепочку алгоритмов сжатия. Наиболее популярна следующая последовательность вызова алгоритмов, использующихся совместно с BWT:
Эта последовательность методов сжатия и используется в BWT-кодеках, участвующих в тестировании. Все эти кодеки были построены автором на базе пакета «Industrial strength BWT compression» [13] и участвуют в тексте как другая известная альтернатива сжатия данных. Этот вариант реализации BWT был выбран для тестирования, поскольку является канонической реализацией кодека на базе этого алгоритма. Проблемой алгоритма на основе BWT является линейная зависимость необходимой памяти от размера обрабатываемой информации. Для практического применения этого алгоритма необходимо зафиксировать максимальную память, которую он может запросить. Чтобы можно было ограничить размеры запрашиваемой памяти, применялось разбиение исходной информации на фиксированные блоки, каждый из которых кодировался независимо от других. Таким методом для тестирования были построены 6 кодеков: BWT 50К, 100K, BWT 200K, BWT 300K, BWT 400K и BWT 500K, каждый из которых имеет ограничения по размеру обрабатываемого блока, соответственно, 50К, 100K, 200K, 300K, 400K, 500K байт. Так же в тесте участвовал алгоритм, не использующий разбиение на блоки, названный BWT full. Таким образом, всего в тесте участвовало 7 алгоритмов на базе BWT.
В качестве базовой тестовой платформы был выбран нетбук на базе процессора Intel Atom N450 1.66GHz, с 2Gbyte оперативной памяти и с операционной системой Windows 7 Starter.
Все кодеки оценивались по следующим критериям:
Степень сжатия информации измеряется двумя способами:
(compressed_length / original_length) * 8 |
100.0*(original_length - compressed_length)/original_length. |
Скорость кодирования и декодирования измеряется в секундах с точностью до третьего знака после запятой.
Каждый вызванный кодек возвращает размер используемой памяти, как для кодирования, так и для декодирования.
Тест кодека представляет собой последовательный вызов для каждого файла, участвующего в тестировании сначала алгоритма компрессии, а затем – декомпрессии. Для каждого файла выдается полная диагностика по всем описанным выше критериям, а при окончании работы кодека выдается полная диагностика по всему текстовому пакету в целом. По завершении тестирования всех кодеков выдается таблица, содержащая кодеки, попавшие в следующие категории:
Для тестирования всех кодеков были использованы пакеты тестов из сайта Archive Comparison Test (A.C.T.) [15]. Как основной пакет для тестов был выбран набор Calgary Corpus (вариант Large), один из наиболее популярных пакетов для тестирования новых кодеков. Этот пакет включает в себя текстовые, графические и бинарные файлы. Всего файлов 18, общим размером 3251493 байта.
В качестве вспомогательных были использованы тестовые наборы из A.C.T:
На рисунках 4, 5, 6, 7, 8 показаны графики зависимости компрессии от порядка модели РРМ при тестировании всех заявленных кодеков на всех вышеописанных тестовых наборах.
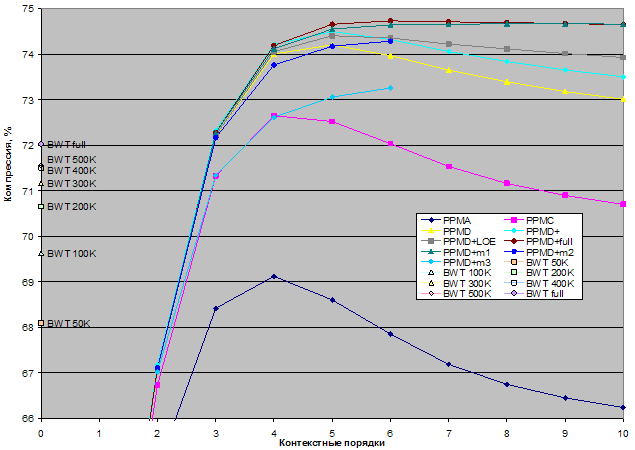
Рисунок 4. Зависимость компрессии от порядка модели РРМ на примере Calgary Corpus
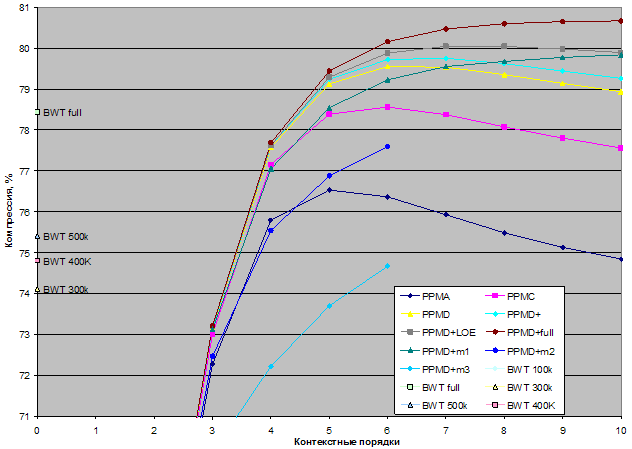
Рисунок 5. Зависимость компрессии от порядка модели РРМ на примере ACT TEXT
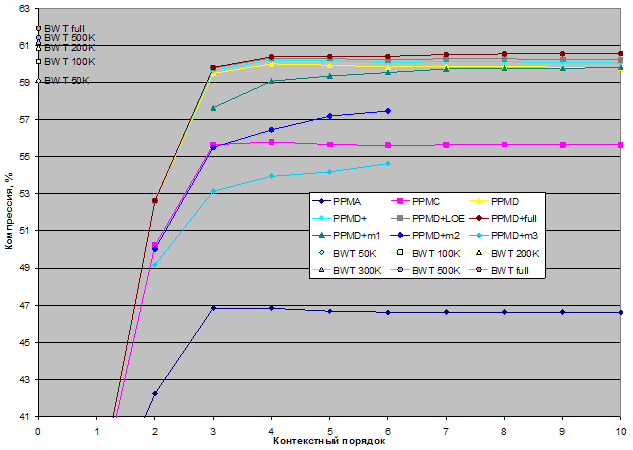
Рисунок 6. Зависимость компрессии от порядка модели РРМ на примере ACT GRAPHICS
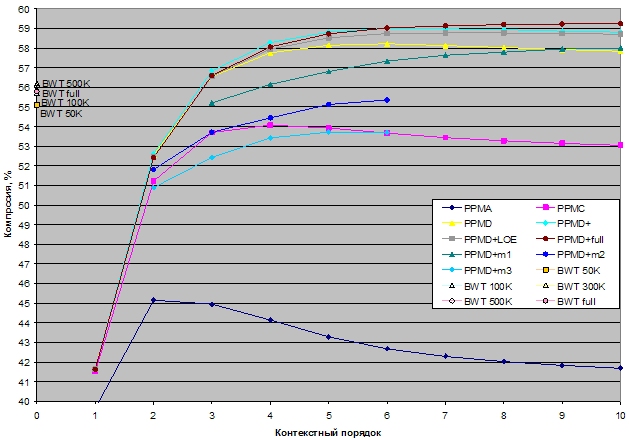
Рисунок 7. Зависимость компрессии от порядка модели РРМ на примере ACT Executable
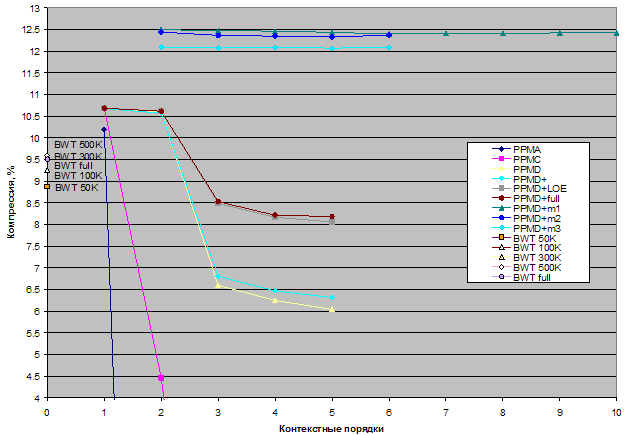
Рисунок 8. Зависимость компрессии от порядка модели РРМ на примере ACT Wav
Графики зависимости компрессии от порядка модели РРМ на первых четырех рисунках имеют схожее поведение. Вначале при увеличении порядка степень компрессии резко возрастает. При достижении определенного порядка, значение которого зависит от типа компрессируемых данных, происходит резкое замедление роста, либо вообще падение компрессии (Calgary Corpus) при увеличении порядка модели.
Совсем другое поведение этого графика можно наблюдать на рисунке 8 при сжатии звуковых файлов. Максимальная степень компрессии достигается на порядке 2 для РРМ-кодеков с ограничениями на размеры памяти, а для кодеков без ограничений – на контекстных моделях 1-го порядка. Далее, при увеличении порядка модели, идет резкое падение компрессии. В этом тесте хорошо видна проблема кодеков на базе алгоритма РРМ – плохое сжатие избыточных данных.
На всех рисунках видно, что наилучшую компрессию для алгоритма РРМ, среди всех тестируемых, на всех порядках показывает компрессия на базе предлагаемого нового метода вычисления кода ухода РРМD+. Среди остальных методов наихудшим является РРМА, значительно лучше его работает метод РРМС, который уступает методу РРМD. Использование механизма LOE и метода добавления дополнительного веса при инициализации могут ощутимо улучшить компрессию, особенно при использовании больших порядков модели.
Предлагаемые методы ограничения памяти, используемые в кодеках PPМD+m1, PPМD+m2 и PPМD+m3, показали очень хорошие результаты компрессии. При сжатии не избыточных данных они работают на уровне кодеков РРМС и РРМD, но при сжатии звуковых файлов они показали лучшие результаты среди всех протестированных кодеков.
Согласно приведенным тестам, кодеки на базе алгоритма РРМ хорошо сжимают текстовую информацию, бинарную, а также смешанную, опережая кодеки на базе классического BWT, которые показали результанты компрессии на уровне 3-5 порядка модели РРМ. Но при сжатии изображений, согласно рисунку 6, кодеки на базе алгоритма BWT работают немного лучше, чем РРМ. В таблице 1.3 приводятся лучшие кодеки по степени сжатия для различных тестовых пакетов.
|
Тестовый пакет |
Кодек |
Затраченная память |
Результат bpb |
|---|---|---|---|
|
Calgary Corpus Large |
PPMD+full o6 |
15361 KB |
2.021 (74.734%) |
|
ACT ТЕХТ |
PPMD+full o10 |
131103 KB |
1.546 (80.672%) |
|
ACT GRAPHICS |
BWT full |
43436 KB |
3.046 (61.919%) |
|
ACT EXECUTABLE |
PPMD+full o10 |
374393 KB |
3.260 (59.247%) |
|
ACT SOUND |
PPMD+full o3 mem1 |
2114 KB |
7.002 (12.471%) |
Ближайшим лучшим кодеком на базе алгоритма РРМ для теста ACT GRAPHICS является PPMD+full o10 с результатом 3.156 (60.548%), что ненамного хуже, чем BWT full.
На рисунке 9 показана зависимость запрашиваемой памяти алгоритма РРМ от величины его контекстного порядка.
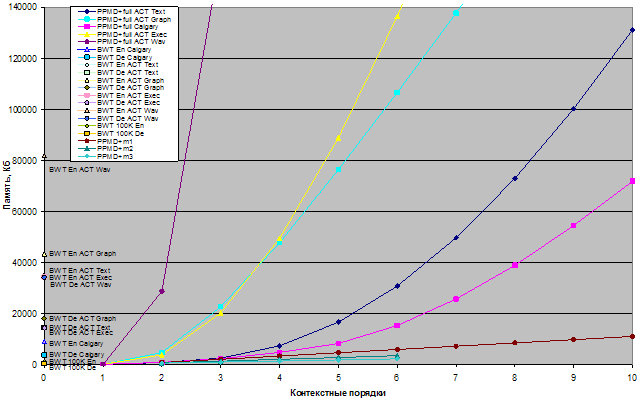
Рисунок 9. Зависимость расхода памяти от порядка модели РРМ для различных данных
По рисунку видно, что для РРМ-кодеков размеры заказываемой памяти существенно зависят как от типа сжимаемой информации, так и от порядка контекстной модели. Использование РРМ-кодеков с ограничениями размеров памяти решает эту проблему. Кодеки PPМD+mem1, PPМD+mem2 и PPМD+mem3 требуют гораздо меньше памяти для компрессии и декомпрессии, чем другие РРМ-кодеки, а их потребности в памяти не зависят от типа кодируемой информации. Кроме этого, заказ памяти у них увеличивается линейно с увеличением порядка модели, а не экспоненциально, как у других РРМ-кодеков.
В случае кодеков на базе алгоритма BWT без ограничений на размер блока, величина заказываемой памяти также зависит от типа компрессируемой информации и достаточно велика. Фиксирование размера блока в BWT позволяет существенно снизить потребности в памяти. В этом случае размер запрашиваемой памяти сравним с заказом памяти на 2-4 порядке для РРМ-кодеков, имеющих ресурсные ограничения. В отличие от кодеков на базе РРМ, у кодеков на базе BWT заказ памяти при компрессии и декомпрессии неодинаков. Как правило, при декомпрессии требуется гораздо меньше ресурсов, чем при компрессии. Это выгодно отличает эти кодеки от кодеков на базе алгоритма РРМ.
На рисунке 10 представлена зависимость времени кодирования и декодирования от порядка контекстной модели РРМ. Тестирование скорости работы кодеков проходило на пяти платформах:
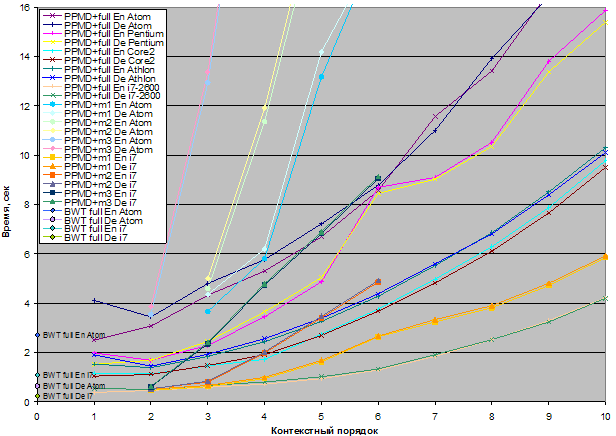
Рисунок 10. Время кодирования и декодирования на примере Calgary Corpus
Согласно графикам, представленным на этом рисунке, время обработки информации кодеками РРМ стремительно возрастает при увеличении порядка контекстной модели. На графиках хорошо заметно, что скорость декомпрессии для кодеков на базе РРМ уступает скорости компрессии от 5 до 20%. Время работы кодеков PPMD+mem1, PPMD+mem2 и PPMD+mem3, использующих контейнеры с фиксированным числом записей, больше, чем у кодеков без таких ограничений. Особенно это заметно на больших порядках, когда время обработки данных этими кодеками возрастает линейно. Такое поведение этих кодеков связано с работой механизма удаления записей, который включается при переполнении контейнеров.
Алгоритмы на базе BWT по скорости компрессии и декомпрессии опережают алгоритмы на базе РРМ. Только порядки 1, 2 и 3 контекстных моделей РРМ могут с ними сравниться по этому показателю. Скорость декомпрессии данных для алгоритмов на базе BWT в несколько раз превышает скорость компрессии.
В Таблице 4 представлены лучшие результаты компрессии для кодеков библиотеки PPMtc по каждому файлу из пакета Calgary Corpus Classic.
|
Файл |
Pазмер |
Лучший PPMtc |
Результат bpb (%), разы |
|---|---|---|---|
|
bib |
25196 |
PPMD+full o6, PPMD+full o6 mem1 |
1.812 (77.354%), 4.42 |
|
book1 |
216396 |
PPMD+full o5 |
2.252 (71.852%), 3.55 |
|
book2 |
147182 |
PPMD+full o7 |
1.928 (75.906%), 4.15 |
|
geo |
57732 |
PPMD+full o6 mem2 |
4.510 (43.621%), 1.77 |
|
news |
110308 |
PPMD+full o9 |
2.340 (70.749%), 3.42 |
|
obj1 |
10220 |
PPMD+full o5, PPMD+full o5 mem1 |
3.802 (52.474%), 2.10 |
|
obj2 |
73366 |
PPMD+ full o10 mem1 |
2.378 (70.275%), 3.36 |
|
paper1 |
15399 |
PPMD+full o7, PPMD+full o8 mem1 |
2.317 (71.033%), 3.45 |
|
paper2 |
23419 |
PPMD+full o5, PPMD+full o5 mem1 |
2.279 (71.509%), 3.51 |
|
pic |
50327 |
PPMD+ full o5 mem2 |
0.784 (90.194%), 10.19 |
|
progc |
11717 |
PPMD+full o10, PPMD+full o10 mem1 |
2.366 (70.420%), 3.38 |
|
progl |
14045 |
PPMD+full o10, PPMD+full o10 mem1 |
1.595 (80.066%), 5.10 |
|
progp |
10041 |
PPMD+full o10, PPMD+full o10 mem1 |
1.627 (79.665%), 4.92 |
|
trans |
15973 |
PPMD+full o10, PPMD+full o10 mem1 |
1.364 (82.952%), 5.87 |
Приведенные в таблице 4 результаты сжатия лучше всех результатов сжатия для различных компрессоров на базе алгоритма LZ, приведенных в Таблице 3.5 из [6]. Согласно Таблице 3.12 из того же источника, приведенные выше результаты уступают результатам, показанным компрессорами ACE, RAR, CABARC, 7-Zip только на файлах "pic", "obj1", "obj2", при этом опережая компрессоры ARJ, PKZIP на всех файлах из набора Calgary Corpus Classic. Что касается компрессоров, реализующий алгоритм РРМ, то согласно Таблице 4.9 из [6], кодеки, построенные с помощью библиотеки РРМtc, показали наилучшие результаты сжатия среди всех кодеков, реализующих РРМ-алгоритм, за исключением PPMII. В целом, кодек PPMD+full o6 уступает самому мощному из всех кодеков на базе РРМ, кодеку PPMd [8], не больше одного процента.
Если сравнивать лучшие кодеки библиотеки PPMtc по степени сжатия из Таблицы 3 с рейтингом лучших кодеков, использующих любые типы алгоритмов сжатия, представленных на сайте проекта Archive Comparison Test [15], то можно определить:
В этой работе была представлена библиотека, с помощью которой можно создавать кодеки на базе алгоритма РРМ. Она поддерживает различные алгоритмы вычисления кода ухода и методы улучшения компрессии. Библиотека разделена на функциональные модули, каждый из которых выполняет строго определенную функцию. Большинство модулей реализовано в виде шаблонов языка С++. Разделение функциональности и использование шаблонов позволяет подключать к библиотеке любые другие реализации задействованных в библиотеке алгоритмов.
Предложенный в работе метод вычисления кода ухода PPMD+ показал наилучшие результаты компрессии среди всех протестированных методов, при этом он не требует ни дополнительной памяти, ни сложных вычислений. Использование простой реализации LOE и метода прибавления дополнительного веса при инициализации ощутимо улучшили степень сжатия. Лучшие по степени сжатия кодеки, построенные с помощью библиотеки РРМtc, уступают всего 1% самой лучшей на сегодняшний день реализации алгоритма РРМ [8], а согласно тесту компрессии текста АСT ТЕХТ, входят в тридцатку лучших среди всех кодеков.
Размер памяти, используемой кодеками РРМ, зависит от типа исходных данных, что может привести к недостатку памяти при кодировании. Методы ограничения размера запрашиваемой памяти с использованием фиксированных по числу записей контейнеров, предложенные в данной работе, решают эту проблему. При этом они несильно ухудшают степени сжатия и увеличивают время компрессии/декомпрессии. Кроме этого, кодеки, использующие ресурсные ограничения, хорошо проявили себя при сжатии избыточных данных. Время их работы и степень сжатия были даже лучше, чем у кодеков без таких ограничений.
Из недостатков библиотеки можно отметить использование виртуальных функций для возможности конструирования кодеков различных контекстных порядков. Вызов виртуальных функций требует больше времени по сравнению с вызовами обычных функций, а число их вызовов в РРМtc достаточно большое. Но если принято решение использовать кодек какого-то определенного порядка, то от них можно отказаться. Это позволит увеличить скорость работы на 5-10%. Реализация LOE и механизма удаления записей из контейнеров также требуют дальнейшего совершенствования. Одним из перспективным методов для улучшения степени сжатия для библиотеки РРМtc является поддержка методов наследования информации, и в частности SEE, которые отсутствуют в данной реализации.
| Оценка 220 Оценить
|
