 Оценка 55
Оценка 55 
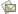 Оценить
Оценить 



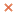


| Оценка 55 Оценить
|
| Хеширование |  |
Выше мы вывели ряд списковых структур, позволяющих программе-клиенту осуществлять поиск и выборку данных. В каждой такой структуре метод Find выполняет обход списка и ищет элемент данных, совпадающий с ключом. При этом эффективность поиска зависит от структуры списка. В случае последовательного списка метод Find гарантированно просматривает O(n) элементов, в то время как в случае бинарных поисковых деревьев и при бинарном поиске обеспечивается более высокая эффективность O(log2n).
В идеале нам хотелось бы выбирать данные за время O(1). В этом случае число необходимых сравнений не зависит от количества элементов данных. Выборка элемента осуществляется за время O(1) при использовании в качестве индекса в массиве некоторого ключа. Например, блюда из меню в закусочной в целях упрощения бухгалтерского учета обозначаются номерами. Какой-нибудь деликатес типа «бастурма, маринованная в водке» в базе данных обозначается просто №2. Владельцу закусочной остается лишь сопоставить ключ 2 с записью в списке (рисунок 25).

Рис. 25.
Мы знаем и другие примеры. Файл клиентов пункта проката видеокассет содержит семизначные номера телефонов. Номер телефона используется в качестве ключа для доступа к конкретной записи файла клиентов.
![]()
Рис. 26.
Ключи не обязательно должны быть числовыми. Например, формируемая компилятором таблица символов (symbol table) содержит все используемые в программе идентификаторы вместе с сопутствующей каждому из них информацией. Ключом для доступа к конкретной записи является сам идентификатор.
В общем случае ключи не настолько просты, как в примере с закусочной. Несмотря на то, что они обеспечивают доступ к данным, ключи, как правило, не являются непосредственными индексами в массиве записей. Например, телефонный номер может идентифицировать клиента, но вряд ли пункт проката хранит десятимиллионный массив.
В большинстве приложений ключ обеспечивает косвенную ссылку на данные. Ключ отображается во множество целых чисел посредством хеш-функции (hash function). Полученное в результате значение затем используется для доступа к данным. Давайте исследуем эту идею. Предположим, есть множество записей с целочисленными ключами. Хеш-функция HF отображает ключ в целочисленный индекс из диапазона 0...n-1. С хеш-функцией связана так называемая хеш-таблица (hash table), ячейки которой пронумерованы от 0 до n-1 и хранят сами данные или ссылки на данные.
Рис. 27.
Предположим, Key – положительное целое, а HF(Key) – значение младшей цифры числа Key. Тогда диапазон индексов равен 0-9. Например, если Key = 49, HF(Key) = HF(49) = 9. Эта хеш-функция в качестве возвращаемого значение использует остаток от деления на 10.
// Хеш-функция, возвращающая младшую цифру ключа int HF(int key) { return key % 10; } |
Часто отображение, осуществляемое хеш-функцией, является отображением «многие к одному» и приводит к коллизиям (collisions). Например, выше мы видим HF(49) = HF(29) = 9. При возникновении коллизии два или более ключа ассоциируются с одной и той же ячейкой хеш-таблицы. Поскольку два ключа не могут занимать одну и ту же ячейку в таблице, мы должны разработать стратегию разрешения коллизий.
Схемы разрешения коллизий обсуждаются после знакомства с некоторыми типами хеш-функций.
Рис. 28.
Хеш-функция должна отображать ключ в целое число из диапазона 0...n-1. При этом количество коллизий должно быть ограниченным, а вычисление самой хеш-функции – очень быстрым. Некоторые методы удовлетворяют этим требованиям.
Наиболее часто используется метод деления (division method), требующий двух шагов. Сперва ключ должен быть преобразован в целое число, а затем полученное значение вписывается в диапазон 0...n-1 с помощью оператора получения остатка. На практике метод деления используется в большинстве приложений, работающих с хешированием.
Предположим, что ключ – пятизначное число. Хеш-функция извлекает две младшие цифры. Например, если это число равно 56389, то HF(56389) = 89. Две младшие цифры являются остатком от деления на 100.
int HF(int key) { return key % 100; // метод деления на 100 } |
Эффективность хеш-функции зависит от того, обеспечивает ли она равномерное распределение ключей в диапазоне 0...n-1. Если две последние цифры соответствуют году рождения, то будет слишком много коллизий при идентификации подростков, играющих в юношеской бейсбольной лиге.
Другой пример – ключ-символьная строка С++. Хеш-функция отображает эту строку в целое число посредством суммирования первого и последнего символов и последующего вычисления остатка от деления на 101 (размер таблицы).
// хеш-функция для символьной строки. // Возвращает значение в диапазоне от 0 до 100 int HF(char *key) { int len = strlen(key), hashf = 0; // если длина ключа равна 0 или 1, возвратить key[0]. // иначе сложить первый и последний символ if (len <= 1) hashf = key[0]; else hashf = key[0] + key[len-1]; return hashf % 101; } |
Эта хеш-функция приводит к коллизии при одинаковых первом и последнем символах строки. Например, строки «start» и «slant» будут отображаться в индекс 29. Так же ведет себя хеш-функция, суммирующая все символы строки.
int HF(char *key) { int hashf = 0; // просуммировать все символы строки и разделить на 101 while (*key) hashf += *key++; return hashf % 101; } |
Строки «bad» и «dab» преобразуются в один и тот же индекс. Лучшие результаты дает хеш-функция, производящая перемешивание битов в символах.
В общем случае при больших n индексы имеют больший разброс. Кроме того, математическая теория утверждает, что распределение будет более равномерным, если n – простое число.
Метод середины квадрата (midsquare technique) предусматривает преобразование ключа в целое число, возведение его в квадрат и возвращение в качестве значения функции последовательности битов, извлеченных из середины полученного числа. Предположим, что ключ есть целое 32-битное число. Тогда следующая хеш-функция извлекает средние 10 бит возведенного в квадрат ключа.
// возвратить средние 10 бит произведения key*key int HF(int key); { key *= key; // возвести ключ в квадрат key >>= 11; // отбросить 11 младших бит return key % 1024 // возвратить 10 младших бит } |
При мультипликативном методе (multiplicative method) используется случайное действительное число f в диапазоне от 0<f<1. Дробная часть произведения f * key лежит в диапазоне от 0 до 1. Если это произведение умножить на n (размер хеш-таблицы), то целая часть полученного произведения даст значение хеш-функции в диапазоне 0...n-1.
// хеш-функция, использующая мультипликативный метод; // возвращает значение в диапазоне 0...700 int HF(int key); { static RandomNumber rnd; float f; // умножить ключ на случайное число из диапазона 0...1 f = key * rnd.fRandom(); // взять дробную часть f = f - int(f); // возвратить число в диапазоне 0...n-1 return 701*f; } |
Несмотря на то, что два или более ключей могут хешироваться одинаково, они не могут занимать в хеш-таблице одну и ту же ячейку. Нам остаются два пути: либо найти для нового ключа другую позицию в таблице, либо создать для каждого значения хеш-функции отдельный список, в котором будут все ключи, отображающиеся при хешировании в это значение. Оба варианта представляют собой две классические стратегии разрешения коллизий – открытую адресацию с линейным перебором и метод цепочек. Мы проиллюстрируем на примере открытую адресацию, а сосредоточимся главным образом на втором методе, поскольку эта стратегия является доминирующей.
Эта методика предполагает, что каждая ячейка таблицы помечена как незанятая. Поэтому при добавлении нового ключа всегда можно определить, занята ли данная ячейка таблицы или нет. Если да, алгоритм осуществляет перебор по кругу, пока не встретится «открытый адрес» (свободное место). Отсюда и название метода. Если размер таблицы велик относительно числа хранимых там ключей, метод работает хорошо, поскольку хеш-функция будет равномерно распределять ключи по всему диапазону и число коллизий будет минимальным. По мере того как коэффициент заполнения таблицы приближается к 1, эффективность процесса заметно падает.
Проиллюстрируем линейный перебор на примере семи записей.
Предположим, что данные имеют тип DataRecord и хранятся в 11-элементной таблице.
struct DataRecord { int key; int data; }; |
В качестве хеш-функции HF используется остаток от деления на 11, принимающий значения в диапазоне 0-10.
HF(item) = item.key % 11 |
В таблице хранятся следующие данные. Каждый элемент помечен числом проб, необходимых для его размещения в таблице.
Список: {54,1}, {77,3}, {94,5}, {89,7}, {14,8}, {45,2}, {76,9} |
Хеширование первых пяти ключей дает пять различных индексов, по которым эти ключи запоминаются в таблице. Например, HF({54,1}) = 10, и этот элемент попадает в Table[10]. Первая коллизия возникает между ключами 89 и 45, так как оба они отображаются в индекс 1.
Элемент данных {89,7} идет первым в списке и занимает позицию Table[1]. При попытке записать {45,2} оказывается, что место Table[1] уже занято. Тогда начинается последовательный перебор ячеек таблицы с целью нахождения свободного места. В данном случае это Table[2]. На ключе 76 эффективность алгоритма сильно падает. Этот ключ хешируется в индекс 10 – место, уже занятое. В процессе перебора осуществляется просмотр еще пяти ячеек, прежде чем будет найдено свободное место в Table[4]. Общее число проб для размещения в таблице всех элементов списка равно 13, т.е. в среднем 1,9 проб на элемент.
При другом подходе к хешированию таблица рассматривается как массив связанных списков или деревьев. Каждый такой список называется блоком (bucket) и содержит записи, отображаемые хеш-функцией в один и тот же табличный адрес. Эта стратегия разрешения коллизий называется методом цепочек (chaining with separate lists).
Если таблица является массивом связанных списков, то элемент данных просто вставляется в соответствующий список в качестве нового узла. Чтобы обнаружить элемент данных, нужно применить хеш-функцию для определения нужного связанного списка и выполнить там последовательный поиск.
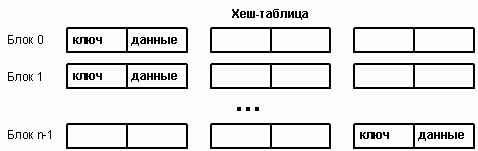
Рис. 29.
Проиллюстрируем метод цепочек на семи записях типа DataRecord и хеш-функции HF.
Список: {54,1}, {77,3}, {94,5}, {89,7}, {14,8}, {45,2}, {76,9}
HF(item) = item.key % 11 |
Каждый новый элемент данных вставляется в хвост соответствующего связанного списка. На рисунке 30 каждое значение данных сопровождается (в скобках) числом проб, требуемых для запоминания этого значения в таблице.
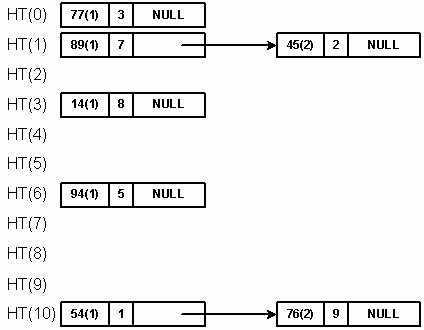
Рис. 30.
Заметьте, что если считать пробой вставку нового узла, то их общее число при вставке семи элементов равно 9, т.е. в среднем 1,3 пробы на элемент данных.
В общем случае метод цепочек быстрее открытой адресации, так как просматривает только те ключи, которые попадают в один и тот же табличный адрес. Кроме того, открытая адресация предполагает наличие таблицы фиксированного размера, в то время как в методе цепочек элементы таблицы создаются динамически, а длина списка ограничена лишь количеством памяти. Основным недостатком метода цепочек являются дополнительные затраты памяти на поля указателей. В общем случае динамическая структура метода цепочек более предпочтительна для хеширования.
В этом разделе определяется общий класс HashTable, осуществляющий хеширование методом цепочек. Этот класс образуется от базового абстрактного класса List и обеспечивает механизм хранения с очень эффективными методами доступа. Допускаются данные любого типа с тем лишь ограничением, что для этого типа данных должен быть определен оператор «==». Чтобы сравнить ключевые поля двух элементов данных, прикладная программа должна перегрузить оператор «==».
Мы также рассмотрим класс HashTableIterator, облегчающий обработку данных в хеш-таблице. Объект типа HashTableIterator находит важное применение при сортировке и доступе к данным.
Но сначала приведем листинги классов Array и LinkedList, используемых в классе HashTable. Особо пояснять мы их не будем, поскольку их обсуждение не входит в задачи этой статьи.
Объявление
enum ErrorType {invalidArraySize, memoryAllocationError, indexOutOfRange}; char *errorMsg[] = { "Неверный размер массива", "Ошибка при выделении памяти", "Неверный индекс: " }; template <class T> class Array { private: // Динамически занимаемый массив. T* alist; // Размер массива. int size; // Обработчик ошибок. void Error(ErrorType error,int badIndex=0) const; public: // Конструкторы и деструктор. Array(int sz = 50); Array(const Array<T>& A); ~Array(void); // Оператор присвоения Array<T>& operator= (const Array<T>& rhs); // Оператор индексации T& operator[](int i); // Оператор приведения к void operator T* (void) const; int ListSize(void) const; // считать размер void Resize(int sz); // изменить размер }; |
Реализация
// печатает сообщение, соответствующее ошибке template <class T> void Array<T>::Error(ErrorType error, int badIndex) const { cerr << errorMsg[error]; if (error == indexOutOfRange) cerr << badIndex; cerr << endl; exit(1); } // конструктор template <class T> Array<T>::Array(int sz) { // проверка правильности заданного размера if (sz <= 0) Error(invalidArraySize); // запоминаем размер и выделяем память под массив size = sz; alist = new T[size]; // проверяем, что система выделила запрошенную память if (alist == NULL) Error(memoryAllocationError); } // деструктор template <class T> Array<T>::~Array(void) { delete [] alist; } // конструктор копирования template <class T> Array<T>::Array(const Array<T>& X) { // присвоить размер объекта X текущему объекту int n = X.size; size = n; // выделить память под массив и проверить, что она выделена alist = new T[n]; // allocate dynamic array if (alist == NULL) Error(memoryAllocationError); // скопировать элементы массива из Х T* srcptr = X.alist; // начальный адрес X.alist T* destptr = alist; // начальный адрес alist // копируем элементы массива while (n--) *destptr++ = *srcptr++; } // оператор присвоения. Присвоить rhs текущему объекту template <class T> Array<T>& Array<T>::operator= (const Array<T>& rhs) { // запоминаем размер rhs int n = rhs.size; // если размеры не совпадают, перезанимаем память if (size != n) { delete [] alist; // освобождаем ранее занятую память alist = new T[n]; // занимаем память под новый массив if (alist == NULL) Error(memoryAllocationError); size = n; } // Копируем элементы массива из rhs в текущий объект T* destptr = alist; T* srcptr = rhs.alist; while (n--) *destptr++ = *srcptr++; // возвращаем ссылку на текущий объект return *this; } // оператор индексирования template <class T> T& Array<T>::operator[] (int n) { // проверяем границы массива if (n < 0 || n > size-1) Error(indexOutOfRange,n); // возвращаем ссылку на запрошенный элемент массива return alist[n]; } // оператор приведения указателя template <class T> Array<T>::operator T* (void) const { // возвращаем значение скрытого поля alist return alist; } template <class T> int Array<T>::ListSize(void) const { return size; } // оператор изменения размеров массива template <class T> void Array<T>::Resize(int sz) { // Проверяем заданный размер if (sz <= 0) Error(invalidArraySize); // ничего не делать, если размер не изменился if (sz == size) return; // занимаем память T* newlist = new T[sz]; if (newlist == NULL) Error(memoryAllocationError); // Рассчитываем количество элементов, // копируемых из старого массива в новый. // Запоминаем в n значение sz (обрезаем массив), если sz <= size // иначе запоминаем size int n = (sz <= size) ? sz : size; // копируем n элементов из старого массива в новый T* srcptr = alist; // начальный адрес старого массива T* destptr = newlist; // начальный адрес нового массива // Копируем элементы массива. while (n--) *destptr++ = *srcptr++; // Уничтожаем старый массив. delete[] alist; // Изменяем значение alist так, чтобы оно указывало на новый массив alist = newlist; // Запоминаем новый размер массива. size = sz; } |
Класс LinkedList использует класс Node для хранения элементов списка.
template <class T> class Node { private: Node<T> *next; // указатель на следующий элемент public: T data; // конструктор Node (const T& item, Node<T>* ptrnext = NULL); // Методы модификации списка void InsertAfter(Node<T> *p); Node<T> *DeleteAfter(void); // возвращает адрес следующего элемента Node<T> *NextNode(void) const; }; // Конструктор. Инициализирует data и next. template <class T> Node<T>::Node(const T& item, Node<T>* ptrnext) : data(item), next(ptrnext) {} // Возвращает значение next template <class T> Node<T> *Node<T>::NextNode(void) const { return next; } // Вставит ветку после текущей // p - элемент, подключаемый к текущему элементу template <class T> void Node<T>::InsertAfter(Node<T> *p) { p->next = next; next = p; } // Отсоединяет элемент, подключенный к текущему и возвращает // адрес отключенного элемента. template <class T> Node<T> *Node<T>::DeleteAfter(void) { Node<T> *tempPtr = next; // запоминаем отключаемый элемент // Если подключенного элемента нет, возвращаем NULL. if (next == NULL) return NULL; // Восстанавливает целостность цепочки. next = tempPtr->next; // возвращаем указатель на отключенный элемент. return tempPtr; } |
Объявление
// Предобъявление класса SeqListIterator template <class T> class SeqListIterator; template <class T> class LinkedList { private: // указатели для доступа к началу и концу списка Node<T> *front, *rear; // используются для получения, вставки и удаления данных Node<T> *prevPtr, *currPtr; // число элементов списка int size; // позиция в списке. Используется методом Reset int position; // скрытые методы создания и уничтожения элементов Node<T> *GetNode(const T& item,Node<T> *ptrNext=NULL); void FreeNode(Node<T> *p); // копирует список L в текущий список void CopyList(const LinkedList<T>& L); public: // конструкторы LinkedList(void); LinkedList(const LinkedList<T>& L); // деструктор ~LinkedList(void); // оператор присвоения LinkedList<T>& operator= (const LinkedList<T>& L); // методы проверки состояния списка int ListSize(void) const; int ListEmpty(void) const; // Методы прохождения void Reset(int pos = 0); void Next(void); int EndOfList(void) const; int CurrentPosition(void) const; // Методы вставки void InsertFront(const T& item); void InsertRear(const T& item); void InsertAt(const T& item); void InsertAfter(const T& item); // Методы удаления T DeleteFront(void); void DeleteAt(void); // Получение/изменение данных T& Data(void); // Метод очистки списка void ClearList(void); // Класс SeqListIterator нуждается в доступе к этому классу friend class SeqListIterator<T>; }; |
Реализация
template <class T> Node<T> *LinkedList<T>::GetNode(const T& item, Node<T>* ptrNext) { Node<T> *p; p = new Node<T>(item,ptrNext); if (p == NULL) { cout << "Ошибка при выделении памяти!\n"; exit(1); } return p; } template <class T> void LinkedList<T>::FreeNode(Node<T> *p) { delete p; } // копируем L в текущий список, который считаем пустым template <class T> void LinkedList<T>::CopyList(const LinkedList<T>& L) { // Используем p для пробегания по списку L Node<T> *p = L.front; int pos; // Перебираем элементы в списке L и вставляем каждый элемент // в конец текущего списка. while (p != NULL) { InsertRear(p->data); p = p->NextNode(); } // Если список пуст, заканчиваем работу. if (position == -1) return; // Перезагрузка prevPtr и currPtr в новом списке prevPtr = NULL; currPtr = front; for (pos = 0; pos != position; pos++) { prevPtr = currPtr; currPtr = currPtr->NextNode(); } } // Создает новый список. Устанавливает указатели в NULL, размер в 0, // и позицию в списке -1 template <class T> LinkedList<T>::LinkedList(void): front(NULL), rear(NULL), prevPtr(NULL),currPtr(NULL), size(0), position(-1) {} template <class T> LinkedList<T>::LinkedList(const LinkedList<T>& L) { front = rear = NULL; prevPtr = currPtr = NULL; size = 0; position = -1; CopyList(L); } template <class T> void LinkedList<T>::ClearList(void) { Node<T> *currPosition, *nextPosition; currPosition = front; while(currPosition != NULL) { // Получаем адрес следующего элемента и удаляем текущий. nextPosition = currPosition->NextNode(); FreeNode(currPosition); currPosition = nextPosition; // Переходим к следующему элементу. } front = rear = NULL; prevPtr = currPtr = NULL; size = 0; position = -1; } template <class T> LinkedList<T>::~LinkedList(void) { ClearList(); } template <class T> LinkedList<T>& LinkedList<T>::operator= (const LinkedList<T>& L) { if (this == &L) // Нельзя копировать себя в себя же. return *this; ClearList(); CopyList(L); return *this; } template <class T> int LinkedList<T>::ListSize(void) const { return size; } template <class T> int LinkedList<T>::ListEmpty(void) const { return size == 0; } // Передвигает prevPtr и currPtr вперед на одну позицию template <class T> void LinkedList<T>::Next(void) { // если перебирать нечего, заканчиваем if (currPtr != NULL) { // Передвигаем указатели вперед на одну позицию. prevPtr = currPtr; currPtr = currPtr->NextNode(); position++; } } // Возвращает TRUE если достигнут конец списка. template <class T> int LinkedList<T>::EndOfList(void) const { return currPtr == NULL; } // Возвращает позицию текущего элемента template <class T> int LinkedList<T>::CurrentPosition(void) const { return position; } // Сбросить текущую позицию в pos template <class T> void LinkedList<T>::Reset(int pos) { int startPos; // Если список пуст, заканчиваем if (front == NULL) return; // В случае неверной позиции завершаем выполнение. if (pos < 0 || pos > size-1) { cerr << "Reset: Неверная позиция: " << pos << endl; return; } if(pos == 0) { // Сбрасываем механизм прохождения в начальное положение prevPtr = NULL; currPtr = front; position = 0; } else { // Устанавливаем механизм прохождения в pos. currPtr = front->NextNode(); prevPtr = front; startPos = 1; // Пробегаем по списку до достижения pos for(position=startPos; position != pos; position++) { prevPtr = currPtr; currPtr = currPtr->NextNode(); } } } // Возвращаем ссылку на элемент данных. template <class T> T& LinkedList<T>::Data(void) { // Ошибка если список пуст или прохождение завершено. if (size == 0 || currPtr == NULL) { cerr << "Data: неверная ссылка!" << endl; exit(1); } return currPtr->data; } // Вставить элемент в начало списка. template <class T> void LinkedList<T>::InsertFront(const T& item) { // Вызвать Reset если список не пуст. if (front != NULL) Reset(); InsertAt(item); } // Вставить элемент в конец списка. template <class T> void LinkedList<T>::InsertRear(const T& item) { Node<T> *newNode; prevPtr = rear; newNode = GetNode(item); // создать новый элемент if (rear == NULL) // Если список пуст, вставить в начало front = rear = newNode; else { rear->InsertAfter(newNode); rear = newNode; } currPtr = rear; position = size; size++; } // Вставить элемент в текущую позицию в списке. template <class T> void LinkedList<T>::InsertAt(const T& item) { Node<T> *newNode; // Два случая: вставка в начало или в середину списка. if (prevPtr == NULL) { // Вставка элемента в начало списка. Также позволяет // поместить элемент в пустой список. newNode = GetNode(item,front); front = newNode; } else { // Вставка элемента внутрь списка. Помещает элемент после prevPtr newNode = GetNode(item); prevPtr->InsertAfter(newNode); } // Если prevPtr == rear, мы вставляем в пустой список // или в конец непустого списка; обновить rear и position if (prevPtr == rear) { rear = newNode; position = size; } // Обновить currPtr currPtr = newNode; size++; // увеличиваем размер списка } // Вставляет элемент за текущей позицией. template <class T> void LinkedList<T>::InsertAfter(const T& item) { Node<T> *p; p = GetNode(item); if (front == NULL) // вставляем в пустой список { front = currPtr = rear = p; position = 0; } else { // Вставляем в конец списка. if (currPtr == NULL) currPtr = prevPtr; currPtr->InsertAfter(p); if (currPtr == rear) { rear = p; position = size; } else position++; prevPtr = currPtr; currPtr = p; } size++; // увеличиваем размер списка } // Удаляет первый элемент списка. template <class T> T LinkedList<T>::DeleteFront(void) { T item; Reset(); if (front == NULL) { cerr << "Ошибка - удаление в пустом списке!" << endl; exit(1); } item = currPtr->data; DeleteAt(); return item; } // Удаляет текущий элемент template <class T> void LinkedList<T>::DeleteAt(void) { Node<T> *p; // Ошибка если список пуст или прохождение завершено. if (currPtr == NULL) { cerr << "Ошибка удаления - отсутствует текущий элемент!" << endl; exit(1); } // Если удаление производится в начале или внутри списка if (prevPtr == NULL) { // Сохраняем указатель на первый элемент и отключаем его. Если это // последний элемент, front становится равным NULL p = front; front = front->NextNode(); } else p = prevPtr->DeleteAfter(); // если удален последний элемент, новым последним элементом становится // prevPtr и позиция уменьшается на 1; иначе, позиция остается той же. // Если p - последний элемент, rear = NULL и position = -1 if (p == rear) { rear = prevPtr; position--; } // Переключить currPtr на следующий за удаляемым элемент. Если p - последний // элемент в списке, currPtr принимает значение NULL. currPtr = p->NextNode(); // Освободить память, занимаемую элементом, и уменьшить размер списка. FreeNode(p); size--; } |
Объявление
template <class T> class List { protected: // Число элементов списка. Изменяется производными классами. int size; public: // Конструктор List(void); // Делаем деструктор виртуальным, чтобы производные классы // могли использовать динамически занимаемую память. virtual ~List(void); // Методы доступа к списку virtual int ListSize(void) const; virtual int ListEmpty(void) const; virtual int Find (T& item) = 0; // Методы изменения списка virtual void Insert(const T& item) = 0; virtual void Delete(const T& item) = 0; virtual void ClearList(void) = 0; }; // Конструктор устанавливает размер в 0 template <class T> List<T>::List(void): size(0) {} // Виртуальный деструктор ничего не делает template <class T> List<T>::~List(void) {} // Возвращает размер списка template <class T> int List<T>::ListSize(void) const { return size; } // Проверка на отсутствие элементов template <class T> int List<T>::ListEmpty(void) const { return size == 0; } |
Объявление
#include "array.h" #include "list.h" #include "link.h" #include "iterator.h" template <class T> class HashTableIterator; template <class T> class HashTable: public List<T> { protected: // число блоков; представляет размер таблицы int numBuckets; // хеш-таблица есть массив связанных списков Array< LinkedList<T> > buckets; // хеш-функция unsigned long (*hf)(T key); // адрес элемента данных, к которому обращались последний раз T *current; public: // конструктор с параметрами, включающими // размер таблицы и хеш-функцию HashTable(int nbuckets, unsigned long hashf(T key)); // методы обработки списков virtual void Insert(const T& key); virtual int Find(T& key); virtual void Delete(const T& key); virtual void ClearList(void); void Update(const T& key); // дружественный итератор, имеющий доступ к // данным-членам friend class HashTableIterator<T> } |
Описание
Объект типа HashTable есть список элементов типа T. В нем реализованы все методы, которые требует абстрактный базовый класс List. Прикладная программа должна задать размер таблицы и хеш-функцию, преобразующую элемент типа T в длинное целое без знака. Описание параметра функции с помощью типа, заданного в шаблоне, позволяет использовать данный класс для хеширования данных любого типа.
Методы Insert, Find, Delete и ClearList являются базовыми методами обработки списков. Отдельный метод Update служит для обновления элемента, уже имеющегося в таблице.
Методы ListSize и ListEmpty реализованы в базовом классе. Элемент данных current всегда указывает на последнее доступное значение данных. Он используется методом Update и производными классами, которые должны возвращать ссылки.
Пример
Предположим, что NameRecord есть запись, содержащая поле наименования и поле счетчика.
struct NameRecord { String name; int count; }; // 101-элементная таблица, содержащая данные типа NameRecord // и имеющая хеш-функцию hash HashTable<NameRecord> HF(101,hash); // вставить запись {"Betsy",1} в таблицу NameRecord rec; rec.name = "Betsy"; rec.count = 1; HF.Insert(rec); cout << HF.ListSize(); // распечатать размер таблицы // Найти значение данных, соответствующее ключу "Betsy", // увеличить поле счетчика на 1 и обновить запись. rec.name = "Betsy"; if (HF.Find(rec) // найти "Betsy" { rec.cout += 1; // обновить поле данных HF.Update(rec); // обновить запись в таблице } else cerr << "Ошибка: \"Ключ Betsy должен быть в таблице.\"\n; |
Класс HashTableIterator образован из абстрактного класса Iterator и содержит методы для просмотра данных в таблице.
Объявление
template <class T> class HashTableIterator: public Iterator<T> { private: // указатель таблицы, подлежащей обходу HashTable<T> *HashTable; // индекс текущего просматриваемого блока и указатель на связанный список int currentBucket; LinkedList<T> *currBucketPtr; // рабочая функция для реализации метода Next void SearchNextNode(int cb); public: // конструктор HashTableIterator (HashTable<T>& ht); // базовые методы итератора virtual void Next(void); virtual void Reset(void); virtual T& Data(void); // подключение к итератору другой хэш-таблицы void SetList(HashTable<T>& lst); }; |
Описание
Метод Next выполняет обход таблицы список (блок) за списком, проходя узлы каждого списка. Значения данных, выдаваемые итератором, никак не упорядочены. Для обнаружения очередного списка, подлежащего обходу, метод Next использует функцию SearchNextNode.
Пример
// объявить итератор для объекта HF типа HashTable HashTableIterator<NameRecord> hiter(HF); // сканировать все элементы базы данных for (hiter.Reset(); !hiter.EndOfList; hiter.Next()) { rec = hiter.Data(); cout << rec.name << ": " << rec.count << endl; } |
Данный класс образован от абстрактного класса List, предоставляющего методы ListSize и ListEmpty. Мы обсудим элементы данных класса HashTable и операции, реализующие виртуальные функции Insert, Find, Delete и ClearList. Ключевым элементом класса является объект buckets типа Array, который определяет массив связанных списков, образующих хеш-таблицу. В поле hf помещается указатель на хеш-функцию, а numBuckets является размером таблицы. Указатель current идентифицирует последний элемент данных, к которому осуществлялся доступ тем или иным методом класса. Его значение задается методами Find и Insert и используется методом Update для обновления данных в таблице.
Метод Insert вычисляет значение хеш-функции и ищет объект типа LinkedList, чтобы проверить, есть ли уже такой элемент данных в таблице или нет. Если есть, то Insert обновляет этот элемент данных, устанавливает на него указатель current и возвращает управление. Если такого элемента в таблице нет, Insert добавляет его в хвост списка, устанавливает на него указатель current и увеличивает размер списка.
template <class T> void HashTable<T>::Insert(const T& key) { // hashval - индекс блока (связанного списка) int hashval = int(hf(key) % numBuckets); // lst -- псевдоним для buckets[hashval]. Помогает обойтись без индексов LinkedList<T>& lst = buckets[hashval]; for (lst.Reset(); !lst.EndOfList(); lst.Next()) // если ключ найден, обновить данные и выйти if (lst.Data() == key) { lst.Data() = key; current = &lst.Data(); return; } // данные, соответствующие этому ключу, не найдены. // вставить элемент в список lst.InsertRear(key); current = &lst.Data(); size++; } |
Метод Find применяет хеш-функцию и просматривает указанный в результате список на предмет совпадения с входным параметром. Если совпадение обнаружено, метод копирует данные в key, устанавливает указатель current на соответствующий узел и возвращает True. В противном случае метод возвращает False.
template <class T> int HashTable<T>::Find(T& key) { // вычислить значение хеш-функции и установить lst // на начало соответствующего связанного списка int hashval = int(hf(key) % NumBuckets); LinkedList<T>& lst = buckets[hashval]; // просмотреть узлы связанного списка в поисках key for (lst.Reset(); !lst.EndOfList(); lst.Next()) if (lst.Data() == key) { // если ключ совпал, получить данные, установить current и выйти key = lst.Data(); current = &lst.Data(); return 1; // вернуть TRUE } return 0; // иначе вернуть FALSE } |
Метод Delete просматривает указанный список и удаляет узел, если совпадение произошло.
Этот класс должен просматривать данные, разбросанные по хеш-таблице. Поэтому он более интересен и более сложен с точки зрения реализации, чем класс HashTable. Обход элементов таблицы начинается с поиска непустого блока в массиве списков. Обнаружив непустой блок, мы просматриваем все узлы этого списка, а затем продолжаем процесс, взяв другой непустой блок. Итератор заканчивает обход, когда просмотрен последний непустой блок. Итератор должен быть привязан к списку. В данном случае переменной hashTable присваивается адрес конкретного экземпляра класса HashTable. Поскольку класс HashTableIterator является дружественным по отношению к HashTable, он имеет доступ ко всем скрытым данным-членам последнего, включая массив buckets и его размер numBuckets.
Переменная currentBucket является индексом связанного списка, который просматривается в данный момент, а currBucketPtr – указателем этого списка. Обход каждого блока осуществляется итератором, встроенным в класс LinkedList. На рисунке 31 показано, как итератор обходит таблицу с четырьмя элементами.
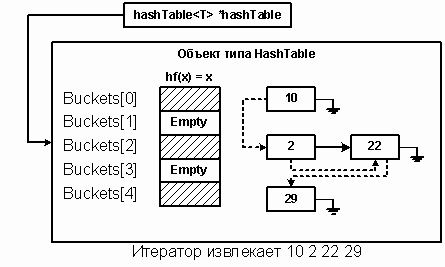
Рис. 31.
Метод SearchNextNode вызывается для обнаружения очередного списка, подлежащего обходу. Просматриваются все блоки, начиная с cb, пока не встретится непустой список. Переменной currentBucket присваивается индекс этого списка, а переменной currBucketPtr – его адрес. Если непустых списков нет, происходит возврат с currentBucket = -1.
// начиная с cb, искать следующий непустой список для просмотра template <class t> void HashTableIterator<T>::SearchNextNode(int cb) { currentBucket = -1; // если индекс cb больше размера таблицы, прекратить поиск if (cb > hashTable->numBuckets) return; // иначе искать, начиная с текущего списка до конца таблицы, // непустой блок и обновить скрытые элементы данных for (int i=cb; i<hashTable->numBuckets; i++) if (!hashTable->buckets[i].ListEmpty()) { // перед тем как вернуться, установить currentBucket равным i // и в currBucketPtr поместить адрес нового непустого списка currBucketPtr = &hashTable->buckets[i]; currBucketPtr ->Reset(); currentBucket = i; return; } } |
Конструктор инициализирует базовый класс Iterator и присваивает скрытому указателю hashTable адрес хэш-таблицы. Непустой список обнаруживается с помощью вызова SearchNextNode с нулевым параметром.
// конструктор. инициализирует базовый класс и класс HashTable // SearchNextNode идентифицирует первый непустой блок в таблице template <class T> HashTableIterator<T>::HashTableIterator(HashTable<T>& hf): Iterator<T>(hf), HashTable(&hf) { SearchNextNode(0); } |
С помощью метода Next осуществляется продвижение вперед по текущему списку на один элемент. По достижении конца списка функция SearchNextNode настраивает итератор на следующий непустой блок.
// перейти к следующему элементу данных в таблице template <class T> void HashTableIterator<T>::Next(void) { // продвинуться к следующему узлу текущего списка currBucketPtr->Next(); // по достижении конца списка вызвать SearchNextNode // для поиска следующего непустого блока в таблице if (currBucketPtr->EndOfList()) SearchNextNode(++currentBucket); // установить флаг iterationComplete, если непустых списков // больше нет iterationComplete = currentBucket == -1; } |
| Оценка 55 Оценить
|