 Оценка 20
[+0/-4]
Оценка 20
[+0/-4]

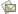 Оценить
Оценить 





| Оценка 20
[+0/-4]
Оценить
|
Структуры данных во время работы базы изменяются довольно редко. Однако существует два типа систем, в которых схема базы перестраивается постоянно:
Подобные системы можно реализовать с помощью виртуальных баз данных со следующими свойствами:
Впервые базы данных с такими свойствами были предложены в 1980-ых годах для работы с медицинскими данными [1; 2]. Из-за разнообразия медицинских данных в реляционной базе их необходимо размещать в разных таблицах, причем при появлении новых видов анализов количество этих таблиц может увеличиваться. В подобных базах можно просмотреть все возможные виды данных по одному пациенту. Естественно, ускоряются только запросы, ориентированные на получение полной информации по пациенту.
Из-за недостаточной известности подобных работ и очевидности идеи построения виртуальной базы это направление несколько раз открывалась повторно в 2000-ых годах [3; 4; 5 и другие]. Заметим, что в большинстве этих работ [3; 4] базы данных с описанными свойствами предлагались как альтернатива обычной базе со словарем, а не как средство реализации изменяющихся частей базы. На наш взгляд, это малоперспективный подход, поскольку, решая основную задачу получения инвариантной структуры, в которой хранятся данные, мы резко увеличиваем сложность запросов, значительно (в разы) уменьшаем скорость их исполнения и порождаем целый ряд проблем, связанных с представлением ограничений целостности, индексов и других хранимых объектов.
Базы с описанными свойствами называют универсальными (УБД), говорят об универсальной модели данных (УМД).
Реализация УМД может быть выполнена в двух основных вариантах:
Выбор предпочтительного варианта зависит от того, насколько удается использовать возможность включающей СУБД. Современные реляционные базы данных редко имеют мощные средства для работы с XML. Для реализации УМД на основе XML необходимо, чтобы данные хранились в уже разобранном виде, а не цельным текстом. Кроме того, необходима поддержка языков для работы с XML: XPath, XQuery и т.п. Также необходимо, чтобы СУБД предоставляла средства для вставки и изменения в середине документа. Далеко не все современные СУБД располагают всеми перечисленными возможностями.
В настоящей работе рассматриваются только УБД на основе баз данных реляционного типа.
УМД состоит из фиксированного набора таблиц. Она может хранить в себе и данные, и метаданные нескольких виртуальных схем базы. В простейшем варианте УМД представляет собой набор из четырех таблиц изображённый на рис.1.

Рис. 1. Типичная схема УМД
Этот набор таблиц остаётся неизменным. Для добавления имени таблицы в виртуальную схему необходимо добавить одну строку в таблицу “Таблица”, а для добавления столбца – добавить одну строку в таблицу “Столбец”. Количество строк в таблице “Данные”, определяющих одну строку таблицы, равно числу столбцов у этой таблицы. Заметим, что тип столбца может быть описан в колонке «Описание» таблицы «Столбец», но может быть добавлен в дополнительном столбце.
В изображенном варианте не создаются суррогатные ключи, в слабые сущности мигрируют ключевые атрибуты, содержащие метаданные виртуальных таблиц. Это позволяет при запросах к виртуальным таблицам обращаться только к таблице «Данные», что сокращает количество соединений таблиц. Но при этом одной команде DML (не select) или DDL для работы с виртуальными таблицами соответствует набор из нескольких однотипных команд записи, обновления или удаления данных для реальных таблиц УМД, объединяемый в транзакцию.
Уже упоминалось, что базы рассматриваемого класса обладают следующими недостатками:
Сосредоточимся на путях устранения этих недостатков и расширении класса виртуальных моделей, которые могут быть реализованы в УМД.
Проблема сложности запросов была решена созданием претрансляторов из языка Query-by-Example (QBE) для виртуальной базы в запросы к реальным таблицам для СУБД Oracle и Caché. Запросы всегда пишутся в виртуальной базе, и имеется возможность проконтролировать исполняемый запрос. Заметим, что можно было бы использовать претранслятор из языка SQL и транслировать запрос в любой язык, принятый во вмещающей СУБД. Важно лишь, чтобы пользователь обращался только к виртуальной базе.
На рис. 2 представлен пример запроса на языке QBE к виртуальным таблицам УМД в реализованном варианте транслятора в Oracle. Имена с двумя знаками подчеркивания в первой и последней позиции обозначают переменные.

Рис. 2. Пример QBE-запроса к виртуальным таблицам УМД.
В листинге 1 представлен промежуточный результат работы реализованного транслятора – запрос к виртуальным таблицам УМД на языке SQL.
SELECT emp.ename, emp.job, emp.sal, emp.deptno, dept.dname
FROM emp, dept
WHERE emp.deptno=dept.deptno; |
Запрос в листинге 1 к виртуальным таблицам УМД транслируется в запрос к реальным таблицам УМД, представленный в листинге 2. Схема, в которой выполняется этот запрос, соответствует схеме, представленной на рис.1, но с другими названиями таблиц и столбцов. В частности, таблица «Данные» носит название «TC». Из-за использования многократных соединений таблицы данных с собой в дальнейшем будем говорить о методе соединений.
SELECT T1.VAL,T2.VAL,T3.VAL,T4.VAL,T5.VAL
FROM TC T1, TC T2, TC T3, TC T4, TC T5, TC T6, TC T7, TC T8
WHERE T1.COLUMN_NAME='ENAME' AND T1.TABLE_NAME='EMP' AND T1.SCHEME_NAME='SCOTT'
AND T2.COLUMN_NAME='JOB' AND T2.TABLE_NAME='EMP' AND T2.SCHEME_NAME='SCOTT'
AND T3.COLUMN_NAME='SAL' AND T3.TABLE_NAME='EMP' AND T3.SCHEME_NAME='SCOTT'
AND T4.COLUMN_NAME='DEPTNO' AND T4.TABLE_NAME='EMP' AND T4.SCHEME_NAME='SCOTT'
AND T5.COLUMN_NAME='DNAME' AND T5.TABLE_NAME='DEPT' AND T5.SCHEME_NAME='SCOTT'
AND T6.COLUMN_NAME='DEPTNO' AND T6.TABLE_NAME='EMP' AND T6.SCHEME_NAME='SCOTT'
AND T7.COLUMN_NAME='DEPTNO' AND T7.TABLE_NAME='DEPT' AND T7.SCHEME_NAME='SCOTT'
AND T8.COLUMN_NAME='SAL' AND T8.TABLE_NAME='EMP' AND T8.SCHEME_NAME='SCOTT'
AND T1.STRING_NUMBER=T2.STRING_NUMBER AND T1.STRING_NUMBER=T3.STRING_NUMBER AND T1.STRING_NUMBER=T4.STRING_NUMBER AND T1.STRING_NUMBER=T6.STRING_NUMBER
AND T1.STRING_NUMBER=T8.STRING_NUMBER AND T2.STRING_NUMBER=T3.STRING_NUMBER AND T2.STRING_NUMBER=T4.STRING_NUMBER AND T2.STRING_NUMBER=T6.STRING_NUMBER
AND T2.STRING_NUMBER=T8.STRING_NUMBER AND T3.STRING_NUMBER=T4.STRING_NUMBER AND T3.STRING_NUMBER=T6.STRING_NUMBER AND T3.STRING_NUMBER=T8.STRING_NUMBER
AND T4.STRING_NUMBER=T6.STRING_NUMBER AND T4.STRING_NUMBER=T8.STRING_NUMBER AND T5.STRING_NUMBER=T7.STRING_NUMBER AND T6.STRING_NUMBER=T8.STRING_NUMBER
AND (T6.VAL=T7.VAL AND TO_NUMBER(T8.VAL)>10000); |
Конечно, такого рода запросы выполняются гораздо медленнее традиционных. Заметим, что писать вручную подобные запросы было бы крайне неудобно, но ещё труднее выполнять их проверку.
Второй способ обращения к реальным таблицам УМД – использование метода Т. Кайта для транспонирования строк в столбцы, описанный в [5]. Запрос, представленный в листинге 1, после трансляции в запрос к реальным таблицам УМД будет иметь следующий вид (листинг 3):
SELECT T1.ENAME, T1.JOB, T1.SAL, T1.DEPTNO, T2.DNAME
FROM (SELECT STRING_NUMBER,
MIN(DECODE(COLUMN_NAME,'ENAME',VAL)) ENAME,
MIN(DECODE(COLUMN_NAME,'JOB',VAL)) JOB,
MIN(DECODE(COLUMN_NAME,'SAL',VAL)) SAL,
MIN(DECODE(COLUMN_NAME,'DEPTNO',VAL)) DEPTNO
FROM TC
WHERE TABLE_NAME='EMP' AND SCHEME_NAME='SCOTT'
GROUPBY STRING_NUMBER) T1,
(SELECT STRING_NUMBER,
MIN(DECODE(COLUMN_NAME,'DNAME',VAL)) DNAME,
MIN(DECODE(COLUMN_NAME,'DEPTNO',VAL)) DEPTNO
FROM TC
WHERE TABLE_NAME='DEPT' AND SCHEME_NAME='SCOTT'
GROUPBY STRING_NUMBER) T2
WHERE T1.DEPTNO=T2.DEPTNO AND T1.SAL>10000; |
Такой запрос в СУБД Oracle выполняется гораздо быстрее, чем составленный по первому методу. Кроме того, можно повысить быстродействие путем добавления индексов на таблицу данных. По результатам измерений производительности системы с различными индексами [7] для работы по методу Т. Кайта был выбран неуникальный индекс на столбцы таблицы «Данные» (TC): «Имя_схемы» (SCHEME_NAME), «Имя_таблицы» (TABLE_NAME), «Номер_строки» (STRING_NUMBER). При использовании метода соединения таблицы данных с собой при выполнении запроса рекомендуется использовать индекс, созданный для первичного ключа (столбцы «Имя_схемы» (SCHEME_NAME), «Имя_таблицы» (TABLE_NAME), «Имя_столбца» (COLUMN_NAME), «Номер_строки» (STRING_NUMBER)).
Конечно, это частичное решение проблемы быстродействия, и рекомендация по использованию УБД остаётся прежней: только инструментальные средства и часть базы с постоянно меняющимися структурами данных.
В разработанных претрансляторах имеется возможность экспорта и импорта виртуальной базы в реальную. В связи с этим, процесс расширения возможностей УМД, не реализованных ранее, и включающих, по крайней мере, ограничения целостности (декларативные и процедурные), представления, индексы, пользователей и роли удобно представлять в виде следующей схемы:
В качестве примера введем в УМД декларативные ограничения целостности. В соответствии с представленной схемой были рассмотрены таблицы словаря, на основании которых были созданы дополнительные таблицы в схеме УМД (рис. 3).
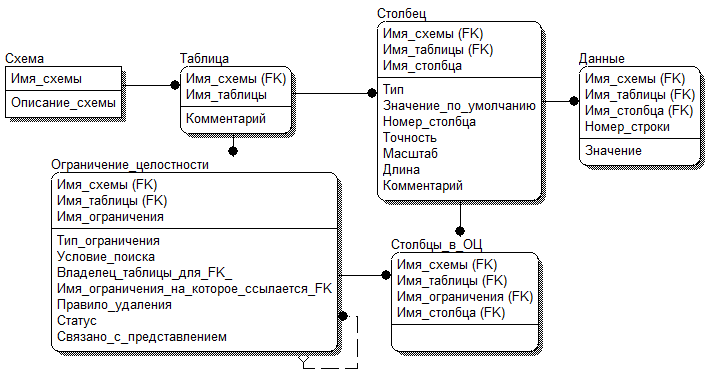
Рис. 3. Схема УМД с добавленными таблицами «Ограничение_целостности» и «Столбцы_в_ОЦ»
Поскольку процедурная часть СУБД, предназначенная для реализации декларативных ОЦ, не может использоваться в УМД, необходимо для каждого типа ОЦ создать хранимую процедуру, реализующую это ограничение. Для таблиц «Столбец» и «Данные» следует добавить DML-триггеры и, с помощью них и хранимых процедур, реализовать поддержку ОЦ. Каждый триггер будет иметь условие на имя таблицы, схемы, столбца, чтобы гарантировать выполнение ограничения целостности только для указанной виртуальной таблицы. Таким образом, в зависимости от типа ОЦ будет запускаться определенный триггер.
Предложенный подход позволяет реализовать виртуальные триггеры, пользователей, представления и секционирование виртуальных таблиц. Для каждого из этих объектов к схеме УМД добавляется свой набор таблиц.
В упрощенном варианте схема УМД с описанными дополнениями представлена на рис. 4.
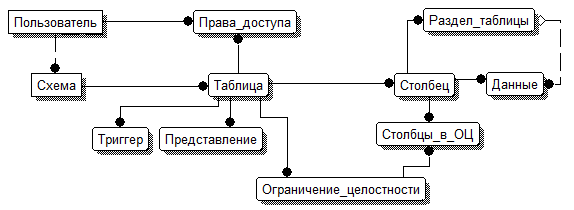
Рис. 4. Расширенная схема УМД.
Заметим, что пакет аудита DBMS_RLS в СУБД Oracle можно использовать для создания виртуальной частной базы данных, с помощью которой можно реализовать в УМД пользователей. Однако этот пакет позволяет добавлять предикаты только в конец исходного запроса, а для реализации представлений и секционированных таблиц необходимо изменять фразу from внутри исходного запроса. Пакет DBMS_RLS не обладает такой возможностью, поэтому мы используем претранслятор, который заменяет исходный запрос к представлению на синтезированный запрос, учитывающий определение представления. Для реализации виртуальных триггеров используются триггеры вмещающей базы с условиями, определяющими область действия триггера – в данном случае виртуальную таблицу.
Некоторые хранимые объекты при их эмуляции в УМД теряют свое изначальное предназначение и функциональность. Примером таких структур являются индексы. При рассматриваемом подходе создается подсхема для хранения метаданных индексов в УМД, но самих индексов нет. Создание индексов в схеме УМД, скорее затормозит выполнение запросов, так как все индексы относятся к единственной таблице «Данные» (рис.1). Для ускорения доступа к данным, хранимым в УМД, также можно использовать секционирование виртуальных таблиц и один индекс.
Вообще, для инструментальных средств проблема быстродействия в определенных границах некритична. При работе с меняющимися структурами данных с замедлением исполнения запросов придется смириться.
Таким образом, желательный перечень реализуемых хранимых объектов виртуальной базы определяется необходимостью экспорта/импорта из УМД в обычную СУБД, а эффективность их реализации зависит от того, насколько удается использовать возможности, заложенные во вмещающей СУБД.
В УМД можно реализовывать модели данных, которых нет во вмещающей СУБД реляционного типа.
По описанной выше схеме можно реализовывать модели данных, отличные от моделей реляционного типа. Рассмотрим расширение УМД для объектно-реляционных моделей. У пользователя должна появиться возможность определять свои типы данных и использовать их в качестве типов столбцов и таблиц. Объект может иметь атрибуты и методы. При этом атрибут также может иметь объектный тип. Объектный тип может быть присвоен столбцу или целой таблице. На основе таблиц словаря к УМД добавляется набор таблиц и связей для реализации описанных свойств. Тело метода может быть выполнено посредством динамического SQL. Таблица «Таблица» переименована в «Таблица или тип» и хранит метаданные виртуальных таблиц и объектных типов. Схема УМД для объектно-реляционной модели представлена на рис.5.
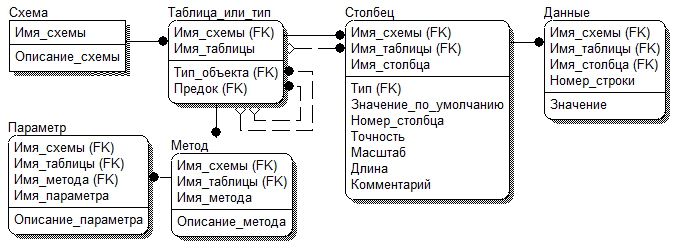
Рис.5. Схема УМД для объектно-реляционной модели
Объектная модель отличается от объектно-реляционной, в частности, тем, что для некоторых полей объектов могут быть заданы уровни доступа, отличные от public, которые имеют все поля объектно-реляционной модели. Для этого можно добавить к таблицам «Столбец» и «Метод» поля, значениями которых будут уровени доступа public и private. Для работы с такими столбцами и методами придется изменить интерпретацию и позволить пользователям обращаться непосредственно только к тем полям, которые имеют уровень доступа public.
Во втором способе реализации уровней доступа добавляются таблицы «Столбец_private», «Метод_private», а существующие таблицы «Столбец» и «Метод» переименовываются в «Столбец_public» и «Метод_public» соответственно. Необходимо добавить методы видов get и set для полей и методов с уровнем доступа «private».
Атрибуты в обычных БД все одного сорта – обязательные, то есть должны использоваться всегда. Полуструктурированные данные отличаются тем, что некоторые атрибуты присутствуют только в отдельных экземплярах сущностей. Атрибуты этого сорта называются необязательными. Набор обязательных атрибутов определяет так называемый минимальный DataGuide. Он играет ту же роль, что и схемы обычных таблиц. Набор обязательных и необязательных атрибутов составляет максимальный DataGuide [8]. Он позволяет определить, используется ли столбец в первый раз, или же фигурировал раньше.
Для реализации полуструктурированной модели существуют два метода. Первый основан не на расширении схемы УМД, а на ее новой интерпретации и изменении логики работы транслятора. Будем считать, что столбцы, описанные в таблице «Столбец» являются обязательными, то есть входят в минимальный DataGuide. Чтобы дать пользователю возможность вставлять в значения в виртуальные поля таблицы «Данные», не входящие в минимальный DataGuide, необходимо отключить проверку существования столбцов в таблице. Можно добавить в таблицу «Данные» столбец «Тип_данных», в который записывается тип данных необязательных атрибутов, который определяется транслятором (простейшим образом – number, varchar2, date). Также можно предлагать пользователю после вставки или наряду с ней определять тип вставляемых значений необязательных столбцов.
Второй способ – добавить в таблицу «Столбец» столбец «Входит в DataGuide» («In_DG»), значениями которого будет «1» – если столбец является обязательным, «0» – необязательным. Поведение относительно типа данных аналогично предыдущему подходу, только тип данных записывается в таблице «Таблица». При этом достаточно менять не логику работы транслятора, а только логику процедур, определяющих словарь виртуальной схемы, которые будут возвращать только те атрибуты, у которых в поле «In_DG» стоит «1».
Для хранения иерархий предлагается дополнить схему УМД таблицей «Иерархия», в которой будет храниться структура отношений предков и потомков (рис.6).

Рис.6. Часть схемы УМД дополненная таблицей «Иерархия»
Реализация иерархии, представленная на рис.6, аналогична предложенной в [9]. Строка виртуальной таблицы является узлом дерева. Таблица «Данные» содержит узлы дерева, а таблица «Иерархия» – его ребра.
Как известно, сеть отличается от иерархии тем, что в ней не важно, является ли узел листом; нет уровней, как в иерархии; у одного узла может быть несколько предков и потомков (для ориентированного графа).
Для реализации сетей в УМД предлагается дополнить схему таблицей «Сеть», которая будет содержать связи между узлами (рис.7).

Рис.7. Часть схемы УМД, дополненная таблицей «Сеть»
Представлен усовершенствованный вариант УМД, предназначенный для создания подсхем с данными, структуры которых невозможно предусмотреть заранее и для использования в инструментальных средствах разработки ИС. Устранены три основных недостатка УМД:
Предложены варианты, позволяющие расширить применение УМД на объектно-реляционную, полуструктурированную, иерархическую и сетевую модели данных.
Разработан прототип системы, в котором имеется возможность экспорта и импорта базы данных реляционного типа.
Было обнаружено, что не все хранимые объекты СУБД можно эффективно эмулировать в УМД, например, индексы.
| Оценка 20
[+0/-4]
Оценить
|