 Оценка 355
[+1/-0]
Оценка 355
[+1/-0]

 Оценить
Оценить 





| Оценка 355
[+1/-0]
Оценить
|
| Введение Блокировки Хинты Взаимоблокировки Заключение Литература |  |
Обычно блокировки рассматривают совместно с транзакциями. В данной статье упор делается в основном на механизм блокировок, его внутреннее устройство и использование в СУБД MS SQL Server 2000. Предполагается, что читатель хорошо знаком с транзакциями и их свойствами. Давайте вспомним вкратце, какими свойствами должны обладать транзакции в современных СУБД (эти требования носят название ACID – Atomicity, Consistency, Isolation и Durability):
В данной статье рассматриваются механизмы реализации уровней изолированности транзакции. Стандартом ANSI были определены четыре уровня изоляции транзакций. Первый – это нулевой уровень изоляции, второй – первый уровень и так далее. Эти уровни помогают решать различные проблемы, которые будут рассматриваться подробно далее в процессе написания демонстрационной программы на С++. Определения уровней будут даны в конце раздела.
Итак, чтобы лучше понять проблемы изоляции транзакций, рассмотрим их сначала с точки зрения программирования на С++. Так как наша программа будет оперировать простыми данными (значение типа int), будем считать, что требования атомарности выполняются автоматически. Кроме того, мы не будем налагать каких-либо логических ограничений на значение переменной и не будем использовать вложенных транзакций, так что требования согласованности и устойчивости также будут опущены.
Наша программа содержит всего два класса: CObject и CProxy. Класс CObject - это объект-одиночка (singleton), который содержит переменную value (доступ к этой переменной мы и будем защищать), и некоторый набор служебных функций. Класс CProxy представляет собой посредника для объекта CObject; именно с ним будет работать клиент. Вот первоначальный набросок (в классе CProxy используется нестандартная конструкция __declspec(property), поддерживаемая только компиляторами от Microsoft):
class CObject;
class CProxy
{
friendclass CObject;
public:
__declspec(property(get=get_Value,put=put_Value)) int value;
int get_Value(int level = -1) const;
void put_Value(int i);
void Commit();
void Rollback();
private:
int _level;
int _value;
bool fUpd;
CProxy(CObject* par,int level)
{
fUpd = false;
parent = par;
_level = level;
}
CObject* parent;
};
class CObject
{
friendclass CProxy;
public:
static CProxy& GetObject(int level = -1);
~CObject()
{
if (hMutex) CloseHandle(hMutex);
}
protected:
CProxy& BeginTran(int level)
{
return *(new CProxy(this,level));
}
void RequestExclusive(int level)
{
}
void RequestShared(int level)
{
}
void RemoveShared(int level)
{
}
void RemoveLocks()
{
}
private:
CObject()
{
value = 0;
}
int value;
static HANDLE hMutex;
};
__declspec(selectany) HANDLE CObject::hMutex = NULL;
CProxy& CObject::GetObject(int level)
{
HANDLE hLocMutex = CreateMutex(NULL,TRUE,_T("Guard-Lock-Mutex"));
bool flg = GetLastError() == ERROR_ALREADY_EXISTS;
if (flg) WaitForSingleObject(hLocMutex,INFINITE);
else CObject::hMutex = hLocMutex;
static CObject obj;
ReleaseMutex(hLocMutex);
if (flg) CloseHandle(hLocMutex);
return obj.BeginTran(level);
}
void CProxy::Commit()
{
parent->RemoveLocks();
deletethis;
}
void CProxy::Rollback()
{
if (fUpd)
parent->value = _value;
parent->RemoveLocks();
deletethis;
}
void CProxy::put_Value(int i)
{
parent->RequestExclusive(_level);
if (!fUpd)
_value = parent->value;
parent->value = i;
fUpd = true;
}
int CProxy::get_Value(int level) const
{
if (level == -1)
level = _level;
parent->RequestShared(level);
int v = parent->value;
parent->RemoveShared(level);
return v;
}
|
Клиент никогда не имеет дела непосредственно с экземпляром класса CObject. Экземпляры класса CProxy – представляют копию данных объекта CObject и делегируют запросы на чтение и запись переменной value. Код получился несколько громоздким: к чему такие сложности? Я заранее определил довольно широкий интерфейс, чтобы потом меньше исправлять. :)
Прошу обратить внимание на довольно сложный механизм создания экземпляра CObject в функции GetObject. Обычно в программах используется более простой код, типа:
CProxy& CObject::GetObject(int level) { static CObject obj; return obj.BeginTran(level); } |
Чем он плох? Дело в том, что если несколько потоков попытаются одновременно вызвать функцию GetObject, конструктор класса CObject может быть вызван более одного раза, так как компилятор (возможно, это его ошибка) не генерирует безопасный код проверки с использованием ассемблерной инструкции cmpxchg. Хотя вероятность возникновения такой ситуации довольно низка, я рекомендую все же не игнорировать ее. Самое простое решение проблемы заключается в использовании недорогого ресурса критической секции, например, так:
CProxy& CObject::GetObject(int level) { ::EnterCriticalSection(&g_cs); static CObject obj; ::LeaveCriticalSection(&g_cs); return obj.BeginTran(level); } |
Однако встает вопрос: где ее инициализировать? Можно в конструкторе глобального объекта, но если у нас будет такой же глобальный клиент, мы не сможем гарантировать, что инициализация критической секции произойдет раньше вызова функции GetObject. Нам нужно что-то, что создается, инициализируется и захватывает ресурс непосредственно в функции GetObject. В качестве этого «чего-то» я выбрал объект исполнительной системы «Мьютекс». Его использование вы и можете наблюдать в первоначальном коде.
Теперь рассмотрим пример с использованием этих классов, который сразу вскрывает первую проблему.
unsigned
__stdcall thread_proc(void*)
{
// Начало транзакции
CProxy& prx = CObject::GetObject();
prx.value = 20;
prx.Commit();
return 0;
}
int main(int argc, char* argv[])
{
// Начало транзакции
CProxy& prx = CObject::GetObject();
prx.value = 10;
// Начало новой сессии
_beginthreadex(0,0,thread_proc,0,0,0);
// Эмулируем работу// Sleep(1000);
printf("%d\n",prx.value);
prx.Commit();
return 0;
}
|
Здесь я в двух параллельных потоках изменяю значение переменной value объекта CObject: в одном – на 10, во втором – на 20. Что выведется на консоль? Определенно сказать нельзя: если раскомментировать строчку Sleep(1000), выведется 20. С закомментированной строчкой выводится 10. Эта проблема носит название «проблема потери последнего изменения» (lost update problem) или проблема «грязной» записи. Она заключается в том, что при одновременном выполнении транзакций, в которых производится изменение данных, невозможно сказать заранее, какое конечное значение примут данные после фиксирования обеих транзакций. В случае «грязной» записи только одна из всех параллельно выполняющихся транзакций будет работать с действительными данными, остальные – нет. Другими словами, хотя данные и будут находиться в согласованном состоянии, логическая их целостность будет нарушена.
Для того чтобы наш объект удовлетворял первому уровню изоляции транзакций, на котором запрещается «загрязнение» данных, перепишем его следующим образом (изменения касаются только класса CObject):
class CObject
{
friendclass CProxy;
public:
enum {READ_UNCOMMITTED};
static CProxy& GetObject(int level = -1);
~CObject()
{
DeleteCriticalSection(&exclusive);
if (hMutex) CloseHandle(hMutex);
}
protected:
CProxy& BeginTran(int level)
{
return *(new CProxy(this,level));
}
void RequestExclusive(int level)
{
if (level >= READ_UNCOMMITTED)
TestExclusive();
}
void RequestShared(int level)
{
}
void RemoveShared(int level)
{
}
void RemoveLocks()
{
RemoveAllLocks();
}
private:
CObject()
{
value = 0;
InitializeCriticalSection(&exclusive);
}
void TestExclusive()
{
//Проверка на монопольную блокировку
EnterCriticalSection(&exclusive);
//Вошли больше одного раза
if (exclusive.RecursionCount > 1)
LeaveCriticalSection(&exclusive);
}
void RemoveAllLocks()
{
//Если была установлена монопольная блокировка - снимаем
if (exclusive.OwningThread == (HANDLE)GetCurrentThreadId())
LeaveCriticalSection(&exclusive);
}
int value;
CRITICAL_SECTION exclusive;
static HANDLE hMutex;
};
|
Добавленный код выделен. Хочется пояснить одну деталь: так как изменять значение переменной value можно несколько раз, а Commit (или Rollback) вызывать только раз, налицо тот факт, что функция EnterCriticalSection вызывается бОльшее количество раз, нежели LeaveCriticalSection. Это ошибка – в соответствии с документацией количество вызовов функций EnterCriticalSection и LeaveCriticalSection должно совпадать. Поэтому после входа в критическую секцию я проверяю поле RecursionCount, которое устанавливает количество повторных входов потока в критическую секцию.
| ПРИМЕЧАНИЕ При работе под ОС семейства Windows 9x это поле не используется и всегда содержит 0, так что приводимый здесь и далее код будет работать только на операционных системах семейства NT. |
Теперь можно определенно сказать, что выведется на консоль в следующем примере:
unsigned
__stdcall thread_proc(void*)
{
// Начало второй транзакции
CProxy& prx = CObject::GetObject(CObject::READ_UNCOMMITTED);
// Здесь поток будет ожидать примерно 1 сек. До тех пор, пока// в главном потоке не будет выполнена строчка prx.Commit();
prx.value = 20;
prx.Commit();
return 0;
}
int main(int argc, char* argv[])
{
//Начало транзакции с 0 уровнем изоляции
CProxy& prx = CObject::GetObject(CObject::READ_UNCOMMITTED);
//Изменение данных
prx.value = 10;
//Открываем новую сессию
_beginthreadex(0,0,thread_proc,0,0,0);
//Print CObject::value variable
printf("%d\n",prx.value);
prx.Commit();
return 0;
}
|
На экран будет выведено число 10, а второй поток изменит данные только после фиксирования транзакции в главном потоке.
Хорошо, мы избавились от проблемы последнего обновления, но взгляните на следующий код:
unsigned
__stdcall thread_proc(void*)
{
CProxy& prx = CObject::GetObject(CObject::READ_UNCOMMITTED);
prx.value = 20;
// Эмулируем работу
Sleep(1000);
prx.value = 40;
prx.Commit();
// Закрытие сессииreturn 0;
}
int main(int argc, char* argv[])
{
// Открытие сессии
_beginthreadex(0,0,thread_proc,0,0,0);
// Эмулируем работу
Sleep(100);
CProxy& fake = CObject::GetObject(CObject::READ_UNCOMMITTED);
// В этой строчке происходит чтение «грязных данных»// fake.get_Value() возвращает 20int* pAr = newint[fake.get_Value()];
// Эмулируем работу
Sleep(1000);
// fake.value = 40for(int i = 0;i < fake.value;i++)
pAr[i] = 0;
if (pAr) delete[] pAr;
fake.Commit();
return 0;
}
|
Если откомпилировать и запустить этот код, он гарантированно приведет к ошибке во время исполнения, так как будет осуществлен выход за границу массива в цикле. Почему? Потому что при создании массива используется значение незафиксированных данных, а в цикле – зафиксированных. Эта проблема известна как проблема «грязного чтения». Она возникает, когда одна транзакция пытается прочитать данные, с которыми работает другая параллельная транзакция. В таком случае временные, неподтвержденные данные могут не удовлетворять ограничениям целостности или правилам. И, хотя к моменту фиксации транзакции они могут быть приведены в «порядок», другая транзакция уже может воспользоваться этими неверными данными, что приведет к нарушению ее работы.
Для решения этой проблемы вводится новый уровень изоляции, на котором запрещается «грязное» чтение. Вот такие изменения нужно внести в реализацию классов CProxy и CObject для того, чтобы программа удовлетворяла второму уровню изоляции:
class CObject
{
friendclass CProxy;
public:
enum {READ_UNCOMMITTED,READ_COMMITTED};
static CProxy& GetObject(int level = -1);
~CObject()
{
DeleteCriticalSection(&exclusive);
if (hShared) CloseHandle(hShared);
if (hMutex) CloseHandle(hMutex);
}
protected:
CProxy& BeginTran(int level)
{
return *(new CProxy(this,level));
}
void RequestExclusive(int level)
{
if (level >= READ_UNCOMMITTED)
TestExclusive();
}
void RequestShared(int level)
{
if (level > READ_UNCOMMITTED)
TestShared(level);
}
void RemoveShared(int level)
{
if (level == READ_COMMITTED){
RemoveSharedLock();
}
}
void RemoveLocks()
{
RemoveAllLocks();
}
private:
CObject()
{
value = 0;
InitializeCriticalSection(&exclusive);
hShared = CreateEvent(NULL,FALSE,TRUE,NULL);
}
void TestShared(int level)
{
//Проверка на монопольную блокировку
EnterCriticalSection(&exclusive);
//Устанавливаем разделяемую блокировку
//только если не была установлена монопольная блокировка
if (exclusive.RecursionCount == 1)
ResetEvent(hShared);
//Снимаем монопольную блокировку
LeaveCriticalSection(&exclusive);
}
void TestExclusive()
{
//Проверка на разделяемую блокировку
WaitForSingleObject(hShared,INFINITE);
// Проверка на монопольную блокировку
EnterCriticalSection(&exclusive);
// Вошли больше одного разаif (exclusive.RecursionCount > 1)
LeaveCriticalSection(&exclusive);
}
void RemoveSharedLock()
{
SetEvent(hShared);
}
void RemoveAllLocks()
{
RemoveSharedLock();
// Если была установлена монопольная блокировка - снимаемif (exclusive.OwningThread == (HANDLE)GetCurrentThreadId())
LeaveCriticalSection(&exclusive);
}
int value;
CRITICAL_SECTION exclusive;
HANDLE hShared;
static HANDLE hMutex;
};
|
Теперь, если изменить константу READ_UNCOMMITTED в предыдущем примере на READ_COMMITTED в качестве параметра GetObject, все станет на свои места. При инициализации массива главный поток перейдет в состояние ожидания до тех пор, пока второй поток не выполнит строчку prx.Commit(); Размер массива в главном потоке будет равен 40 элементам.
Хорошо, прекрасно! Где там следующий уровень? :) Чтобы понять, зачем нужен следующий уровень изоляции транзакций «повторяющееся чтение», рассмотрим такой пример:
unsigned
__stdcall thread_proc(void*)
{
{
// Начало транзакции
CProxy& prx = CObject::GetObject(CObject::READ_COMMITTED);
prx.value = 20;
prx.Commit();
}
// Эмулируем работу
Sleep(500);
{
// Начало транзакции
CProxy& prx = CObject::GetObject(CObject::READ_COMMITTED);
prx.value = 40;
prx.Commit();
}
return 0;
}
int main(int argc, char* argv[])
{
// Начало сессии
_beginthreadex(0,0,thread_proc,0,0,0);
// Эмулируем работу
Sleep(100);
CProxy& fake = CObject::GetObject(CObject::READ_COMMITTED);
// Создание массиваint* pAr = newint[fake.get_Value()];
// Эмулируем работу
Sleep(1000);
// Инициализация массиваfor(int i = 0;i < fake.value;i++)
pAr[i] = 0;
if (pAr) delete[] pAr;
fake.Commit();
return 0;
}
|
Если запустить этот пример, он, как и предыдущий, приведет к ошибке доступа к памяти. Дело в том, что изначально создается массив размером в 20 элементов, а в цикле инициализации используется значение 40, и на 21 элементе мы получим ошибку доступа.
Проблема повторного чтения состоит в том, что между операциями чтения в одной транзакции другие транзакции могут беспрепятственно вносить любые изменения, так что повторное чтение тех же данные приведет к другому результату.
Для поддержки третьего уровня изоляции в код изменений вносить не надо! :) Необходимо лишь не снимать разделяемые блокировки до конца транзакции. Так как метод, приведенный ниже, снимает блокировку только на уровне READ_COMMITTED:
void RemoveShared(int level)
{
if (level == READ_COMMITTED){
RemoveSharedLock();
}
}
|
нам нужно лишь добавить новую константу в перечисление типов блокировок.
enum {READ_UNCOMMITTED,READ_COMMITTED,REPEATABLE_READ};
|
Теперь, если в приведенном выше примере изменить константу READ_COMMITTED на REPEATABLE_READ в качестве параметра GetObject, код заработает правильно и без ошибок.
| ПРИМЕЧАНИЕ Совершенно не обязательно менять уровень изоляции транзакций в потоке thread_proc, работа примера не изменится, даже если изменить уровень изоляции на READ_UNCOMMITTED. |
Здесь мы ставим блокировку обновления, если транзакция читает данные с уровнем изоляции REPEATABLE_READ.
В заключение, перед тем как привести полностью код с поддержкой первых трех уровней изоляции, давайте поговорим вот о чем. Созданный код реализует блокирующую модель, которая характерна для СУБД MS SQL Server 2000. Существует также версионная модель реализации блокировок, которую поддерживает такая известная СУБД, как Oracle. Чем отличаются эти модели? Рассмотрим такой код:
unsigned
__stdcall thread_proc(void*)
{
// Print CObject::value variable
CProxy& fake = CObject::GetObject();
printf("in second session: %d\n",fake.value);
fake.Commit();
return 0;
}
int main(int argc, char* argv[])
{
// Начало транзакции
CProxy& prx = CObject::GetObject();
prx.value = 10;
// Начало новой сессии
_beginthreadex(0,0,thread_proc,0,0,0);
// Эмулируем работу
Sleep(100);
printf("in primary session: %d\n",prx.value);
prx.Commit();
return 0;
}
|
Здесь во второй сессии (выполняемой в отдельном потоке) мы просто читаем данные и выводим их на консоль. Так как значение переменной value мы изменили перед стартом второй сессии, совершенно очевидно, что на экран будет выведено
in second session: 10 in primary session: 10 |
Однако при использовании версионной модели мы должны получить
in second session: 0 in primary session: 10 |
Причина в том, что для каждой транзакции хранится своя копия данных (snap-shot), которая синхронизируется с основными данными только в момент фиксирования транзакции.
| ПРИМЕЧАНИЕ Oracle хранит эти копии данных в специальном хранилище, который называется rollback segment. |
Версионная модель характеризуется тем, что в ней отсутствует нулевой уровень изоляции транзакций (READ UNCOMMITTED), и вместо него вводится новый уровень, который в приведенном далее коде я назвал SNAP_SHOT. Он отличается от стандартного тем, что позволяет читать действительные зафиксированные данные, даже при наличии незавершенных транзакций обновления.
Вот конечный вариант классов CProxy и CObject, который реализует обе модели и, вдобавок к этому, поддерживает два «хинта»: UPDLOCK и XLOCK. Они предназначены для изменения уровня изоляции непосредственно при работе со значением переменной, а их смысл я поясню в следующих разделах.
#define MSSQL
// #define ORACLEclass CObject;
class CProxy
{
friendclass CObject;
public:
__declspec(property(get=get_Value,put=put_Value)) int value;
int get_Value(int level = -1) const;
void put_Value(int i);
void Commit();
void Rollback();
private:
int _level;
int _value;
bool fUpd;
CProxy(CObject* par,int level)
{
fUpd = false;
parent = par;
_level = level;
}
CObject* parent;
};
class CObject
{
friendclass CProxy;
public:
enum {
#ifdef MSSQL
READ_UNCOMMITTED,
#elif defined ORACLE
SNAP_SHOT,
#endif
READ_COMMITTED,REPEATABLE_READ,UPDLOCK,XLOCK};
static CProxy& GetObject(int level = -1);
~CObject()
{
DeleteCriticalSection(&exclusive);
DeleteCriticalSection(&update);
if (hShared) CloseHandle(hShared);
if (hMutex) CloseHandle(hMutex);
}
protected:
CProxy& BeginTran(int level)
{
return *(new CProxy(this,level));
}
void RequestExclusive(int level)
{
ATLASSERT(level <= REPEATABLE_READ);
#ifdef MSSQL
if (level >= READ_UNCOMMITTED)
#elif defined ORACLE
if (level >= SNAP_SHOT)
#endif
TestExclusive();
}
void RequestShared(int level)
{
#ifdef MSSQL
if (level > READ_UNCOMMITTED)
#elif defined ORACLE
if (level > SNAP_SHOT)
#endif
TestShared(level);
}
void RemoveShared(int level)
{
if (level == READ_COMMITTED){
RemoveSharedLock();
}
}
void RemoveLocks()
{
RemoveAllLocks();
}
private:
CObject()
{
value = 0;
InitializeCriticalSection(&update);
InitializeCriticalSection(&exclusive);
hShared = CreateEvent(NULL,FALSE,TRUE,NULL);
}
void TestShared(int level)
{
// Проверка на монопольную блокировку
EnterCriticalSection(&exclusive);
// Устанавливаем блокировку обновленияif (level == UPDLOCK){
EnterCriticalSection(&update);
// Вошли больше одного разаif (update.RecursionCount > 1)
LeaveCriticalSection(&update);
}
elseif (level != XLOCK){
// Устанавливаем разделяемую блокировку// только если не была установлена блокировка обновления или// монопольная блокировкаif (update.OwningThread != (HANDLE)GetCurrentThreadId() &&
exclusive.RecursionCount == 1)
ResetEvent(hShared);
// Снимаем монопольную блокировку
LeaveCriticalSection(&exclusive);
}
// Если указан XLOCK монопольная блокировка остается
}
void TestExclusive()
{
// Проверка на разделяемую блокировку
WaitForSingleObject(hShared,INFINITE);
// Проверка на блокировку обновления
EnterCriticalSection(&update);
// Проверка на монопольную блокировку
EnterCriticalSection(&exclusive);
// Снимаем блокировку обновления
LeaveCriticalSection(&update);
// Вошли больше одного разаif (exclusive.RecursionCount > 1)
LeaveCriticalSection(&exclusive);
}
void RemoveSharedLock()
{
SetEvent(hShared);
}
void RemoveAllLocks()
{
RemoveSharedLock();
// Если была установлена блокировка обновления - снимаемif (update.OwningThread == (HANDLE)GetCurrentThreadId())
LeaveCriticalSection(&update);
// Если была установлена монопольная блокировка - снимаемif (exclusive.OwningThread == (HANDLE)GetCurrentThreadId())
LeaveCriticalSection(&exclusive);
}
int value;
CRITICAL_SECTION update;
CRITICAL_SECTION exclusive;
HANDLE hShared;
static HANDLE hMutex;
};
__declspec(selectany) HANDLE CObject::hMutex = NULL;
CProxy& CObject::GetObject(int level)
{
HANDLE hLocMutex = CreateMutex(NULL,TRUE,_T("Guard-Lock-Mutex"));
bool flg = GetLastError() == ERROR_ALREADY_EXISTS;
if (flg) WaitForSingleObject(hLocMutex,INFINITE);
else CObject::hMutex = hLocMutex;
static CObject obj;
ReleaseMutex(hLocMutex);
if (flg) CloseHandle(hLocMutex);
return obj.BeginTran(level);
}
void CProxy::Commit()
{
#ifdef ORACLE
parent->value = _value;
#endif
parent->RemoveLocks();
deletethis;
}
void CProxy::Rollback()
{
#ifdef MSSQL
if (fUpd)
parent->value = _value;
#endif
parent->RemoveLocks();
deletethis;
}
void CProxy::put_Value(int i)
{
parent->RequestExclusive(_level);
#ifdef MSSQL
if (!fUpd)
_value = parent->value;
parent->value = i;
#elif defined ORACLE
_value = i;
#endif
fUpd = true;
}
int CProxy::get_Value(int level) const
{
if (level == -1)
level = _level;
parent->RequestShared(level);
#ifdef MSSQL
int v = parent->value;
parent->RemoveShared(level);
return v;
#elif defined ORACLE
return _value;
#endif
}
|
Из этих примеров должно быть понятно, что блокировки – дело серьезное. :) Но, прежде чем перейти к рассмотрению их реализации в MS SQL Server 2000, я приведу обещанные в начале уровни определения изоляции транзакций. Каждый уровень включает в себя предыдущий с предъявлением более жестких требований к изоляции.
Если вы не совсем поняли суть последнего уровня изоляции, не расстраивайтесь. Я специально оставил его на потом, так как в данный момент нет возможности рассмотреть примеры, описывающие проблему и механизмы ее избежания.
В таблице 1 подводится итог этого раздела и изучения уровней изоляции.
| Уровни изоляции | Загрязнение данных | Грязное чтение | Неповторяемое чтение | Фантомы |
|---|---|---|---|---|
| READ UNCOMMITTED | - | + | + | + |
| READ COMMITTED | - | - | + | + |
| REPEATABLE READ | - | - | - | + |
| SERIALIZABLE | - | - | - | - |
Блокировки в MS SQL Server 2000 (в дальнейшем просто сервер) – это механизм реализации требования изолированности транзакций. Вся последующая информация специфична только для указанного сервера.
Существует три основных типа блокировок и множество специфичных. Сервер устанавливает блокировки автоматически в зависимости от текущего уровня изоляции транзакции, однако при желании вы можете изменить тип с помощью специальных подсказок – хинтов.
При открытии новой сессии по умолчанию выбирается уровень изоляции READ COMMITTED. Вы можете изменить этот уровень для данного соединения с помощью команды:
SET
TRANSACTION ISOLATION LEVEL
|
Более подробно эту команду и хинты для операторов T-SQL мы рассмотрим в следующем разделе. Пока же я хочу подробно остановиться на типах блокировок.
Блокировки применяются для защиты совместно используемых ресурсов сервера. В качестве объектов блокировок могут выступать следующие сущности:
| ПРИМЕЧАНИЕ Экстент – это группа из 8 страниц. Страница – минимальная единица хранения данных в файле базы данных. Размер страницы составляет 8 Кб. |
SQL Server сам выбирает наиболее оптимальный объект для блокировки, однако пользователь может изменить это поведение с помощью тех же хинтов. При автоматическом определении объекта блокировки сервер должен выбрать наиболее подходящий с точки зрения производительности и параллельной работы пользователей. Чем меньше детализация блокировки (строка – самая высокая степень детализации), тем ниже ее стоимость, но ниже и возможность параллельной работы пользователей. Если выбирать минимальную степень детализации, запросы на выборку и обновление данных будут исполняться очень быстро, но другие пользователи при этом должны будут ожидать завершения транзакции. Степень параллелизма можно увеличить путем повышения уровня детализации, однако блокировка – вполне конкретный ресурс SQL Server’а, для ее создания, поддержания и удаления требуется время и память.
| ПРИМЕЧАНИЕ Блокировка занимает 96 байт. [1] Общее количество блокировок может варьироваться от 5000 до 2 147 483 647. Конкретное значение можно задать с помощью хранимой процедуры sp_configure с параметром locks. |
SQL Server может принимать решение об уменьшении степени детализации, когда количество блокированных ресурсов увеличивается. Этот процесс называется эскалацией блокировок.
Вообще говоря, существует два метода управления конкуренцией для обеспечения параллельной работы множества пользователей – оптимистический и пессимистический. SQL Server использует оптимистическую конкуренцию только при использовании курсоров (cursors). Для обычных запросов на выборку и обновление используется пессимистическая конкуренция. Рассмотрим подробнее, что они собой представляют:
Блокировки – чрезвычайно важный и неотъемлемый механизм функционирования сервера. Они применяются для каждого запроса на чтение или обновления данных, а также во многих других случаях (например, при создании новой сессии). Работой с блокировками занимается специальный модуль SQL Server’а – менеджер блокировок (Lock Manager). В его задачи входит:
Когда пользователь делает запрос на обновление или чтение данных, менеджер транзакций передает управление менеджеру блокировок для того, чтобы выяснить были ли блокированы запрашиваемые ресурсы, и, если да, совместима ли запрашиваемая блокировка с текущей. Если блокировки несовместимы, выполнение текущей транзакции откладывается до тех пор, пока данные не будут разблокированы. Как только данные становятся доступны, менеджер блокировок накладывает запрашиваемую блокировку, и возвращает управление менеджеру транзакций.
Момент снятия блокировки сильно зависит от текущего уровня изоляции и типа запроса. Например, при выполнении запроса на выборку данных при уровне изоляции ниже REPEATABLE READ менеджер блокировок снимает блокировку сразу же после извлечения всех данных с текущей страницы. При этом происходит установка блокировки на следующую страницу.
SQL Server поддерживает три основных типа блокировок:
Прежде чем идти дальше, давайте рассмотрим небольшой пример. Для просмотра текущих блокировок существует системная хранимая функция sp_lock. Она возвращает информацию о блокировках в формате, описанном в таблице 2.
| Имя колонки | Описание |
|---|---|
| spid | Идентификатор процесса SQL Server. |
| dbid | Идентификатор базы данных. |
| ObjId | Идентификатор объекта, на который установлена блокировка. |
| IndId | Идентификатор индекса. |
| Type | Тип объекта. Может принимать значения: DB, EXT, TAB, PAG, RID, KEY. |
| Resource | Содержимое колонки syslocksinfo.restext. Обычно это идентификатор строки (для типа RID) или идентификатор страницы (для типа PAG). |
| Mode | Тип блокировки. Может принимать значения: Sch-S, Sch-M, S, U, X, IS, IU, IX, SIU, SIX, UIX, BU, RangeS-S, RangeS-U, RangeIn-Null, RangeIn-S, RangeIn-U, RangeIn-X, RangeX-S, RangeX-U, RangeX-X. Об этих значениях будет сказано ниже. |
| Status | Статус процесса SQL Server. Может принимать значения: GRANT, WAIT, CNVRT. |
Эта процедура возвращает данные о блокировках из системной таблицы syslockinfo, которая находится в базе данных master.
| ПРИМЕЧАНИЕ Информация именно из этой таблицы используется менеджером блокировок для определения совместимости блокировок при запросе ресурсов транзакциями. |
Во всех примерах используется таблица test, которая создается следующим скриптом:
create
table test(i int, n varchar(20))
insertinto test values(1,’alex’)
insertinto test values(2,’rosa’)
insertinto test values(3,’dima’)
|
Во-первых, давайте действительно убедимся, что при чтении данных с уровнем изоляции ниже REPEATABLE READ разделяемые блокировки снимаются сразу же после извлечения данных:
print @@spid
begintranselect * from test
|
Мы начали транзакцию, но оставили ее открытой. Для того чтобы посмотреть, какие блокировки наложены предыдущим скриптом, вызовем процедуру sp_lock (в другой сессии) с параметром, выведенным print @@spid (у меня это 54).
| СОВЕТ Текущее значение идентификатора процесса сервера можно увидеть в строке состояния программы Query Analizer. |
sp_lock 54 |
Результат приведен в таблице 3.
| spdi | dbid | ObjId | IndId | Type | Resource | Mode | Status |
|---|---|---|---|---|---|---|---|
| 54 | 8 | 0 | 0 | DB | S | GRANT |
Мы видим стандартную блокировку, которая создается для каждого соединения с базой данных. Никакой дополнительной блокировки установлено не было.
Другим способом проверки того, что блокировка снимается сразу после извлечения данных, является использование трассировки. Попробуйте выполнить следующую команду:
dbcc
traceon(3604,1200)
select * from test
dbcctraceoff(3604,1200)
|
Флаг трассировки 3604 заставляет сервер передавать отладочную информацию в текущее соединение непосредственно клиенту, а 1200 – выводить информацию о блокировках. В результате мы получим следующее:
Process 54 acquiring S lock on DB: 8 (class bit0 ref1) result: OK Process 54 acquiring IS lock on TAB: 8:1993058136 [] (class bit0 ref1) result: OK Process 54 acquiring IS lock on PAG: 8:1:31 (class bit0 ref1) result: OK i n ----------- -------------------- 1 alex 2 rosa 3 dima (3 row(s) affected) Process 54 releasing lock on PAG: 8:1:31 Process 54 releasing lock on TAB: 8:1993058136 [] |
Хорошо. В первой сессии зафиксируйте транзакцию:
--print @@spid
--begin tran select * from test
commit
|
Повторный вызов sp_lock приводит к тем же результатам. Это подтверждает, что предыдущим запросом никаких блокировок не устанавливалось. Теперь попробуем наложить блокировку обновления. Делается это с помощью хинта updlock (хинты подробно будут рассмотрены далее):
begin
tran
select * from test with (updlock)
|
Теперь вызов sp_lock 54 дает более интересный результат (таблица 4):
| spdi | dbid | ObjId | IndId | Type | Resource | Mode | Status |
|---|---|---|---|---|---|---|---|
| 54 | 8 | 0 | 0 | DB | S | GRANT | |
| 54 | 8 | 1993058136 | 0 | RID | 1:29:2 | U | GRANT |
| 54 | 8 | 1993058136 | 0 | RID | 1:29:0 | U | GRANT |
| 54 | 8 | 1993058136 | 0 | PAG | 1:29 | IU | GRANT |
| 54 | 8 | 1993058136 | 0 | TAB | IX | GRANT | |
| 54 | 8 | 1993058136 | 0 | RID | 1:29:1 | U | GRANT |
Как видно, на три строки была наложена блокировка обновления, что означает невозможность обновления этих строк другими транзакциями. Кроме этого, были наложены еще две блокировки, которые относятся к типу блокировок намерения (intent locks) – блокировка на страницу и на таблицу. Пусть вас не смущает колонка Resource – ее содержание я опишу позже. Поле ObjId представляет собой идентификатор объекта, имя которого можно получить с помощью функции object_name. IndId – идентификатор индекса, в данном примере всегда равен 0, так как в таблице test индексов не используется.
Блокировки намерений всегда устанавливаются на таблицу или страницу, но никогда – на строку. Для чего они нужны? Блокировки намерений относятся к специальным типам блокировок и предназначены для повышения производительности работы менеджера блокировок.
Предположим, некая транзакция пытается изменить какую-либо строку в таблице test. Чтобы определить, что эту транзакцию необходимо заблокировать, менеджеру транзакций (в отсутствие блокировок намерения) пришлось бы сканировать всю таблицу syslockinfo для проверки всех строк таблицы test. Чтобы избежать этой неблагодарной работы, менеджер блокировок сразу устанавливает на страницу и таблицу блокировку намерения обновления (Intent Update) и монопольную блокировку намерения (Intent Exclusive) соответственно, и проверяет уже только их. Таким образом, блокировки намерений – это хинт менеджеру блокировок, который дает значительный выигрыш в производительности при проверке совместимости блокировок.
Рассмотрим блокировки намерений более подробно:
Чтобы уяснить работу этого типа блокировок, продолжим наш пример. Создайте новую сессию (у меня ее идентификатор равен 55) и выполните следующий скрипт:
begin
tran
insert
into test values(4,'other')
|
На удивление многих она прекрасно отработает и не выдаст никаких предупреждений. Как же так? Посмотрим, что скажет нам sp_lock
sp_lock 54,55 |
Результат приведен в таблице 5:
| spid | dbid | ObjId | IndId | Type | Resource | Mode | Status |
|---|---|---|---|---|---|---|---|
| 54 | 8 | 0 | 0 | DB | S | GRANT | |
| 54 | 8 | 1993058136 | 0 | RID | 1:29:02 | U | GRANT |
| 54 | 8 | 1993058136 | 0 | RID | 1:29:00 | U | GRANT |
| 54 | 8 | 1993058136 | 0 | PAG | 1:29 | IU | GRANT |
| 54 | 8 | 1993058136 | 0 | TAB | IX | GRANT | |
| 54 | 8 | 1993058136 | 0 | RID | 1:29:01 | U | GRANT |
| 55 | 8 | 0 | 0 | DB | S | GRANT | |
| 55 | 8 | 1993058136 | 0 | PAG | 1:29 | IX | GRANT |
| 55 | 8 | 1993058136 | 0 | TAB | IX | GRANT | |
| 55 | 8 | 1993058136 | 0 | RID | 1:29:03 | X | GRANT |
Как видно, предыдущие блокировки остались (еще бы! мы же не зафиксировали транзакцию), и добавились четыре новых: одна блокировка базы, не имеющая никакого значения, две блокировки намерений (на таблицу и страницу) и монопольная блокировка на новую строку (идентификатор 1:29:03).
Пока все более-менее ясно. Однако если выполнить в первой сессии обновление данных, ради которых, собственно, и была наложена блокировка обновления, ничего не выйдет! При выполнении следующей команды сессия заблокируется:
--begin tran select * from test with (updlock)
update test set n = 'other1'where i = 1
|
Если посмотреть на содержимое таблицы syslockinfo с помощью хранимой процедуры sp_lock, можно увидеть, что добавилась еще одна строка (таблица 6).
| spid | dbid | ObjId | IndId | Type | Resource | Mode | Status |
|---|---|---|---|---|---|---|---|
| 54 | 8 | 1993058136 | 0 | RID | 1:29:03 | U | WAIT |
Так как на строку 1:29:03 уже наложена монопольная блокировка, никакие другие блокировки на этот же ресурс наложены быть не могут. Но каким образом наш безобидный update на первую строчку привел к наложению блокировки обновления на четвертую строчку? Дело в том, что при отсутствии индекса менеджер блокировок не может определить, какой именно строке соответствует заданное логическое условие, поэтому производится сканирование и установка монопольной блокировки на каждую строчку таблицы. При наличии индекса SQL Server использует другой метод, основанный на блокировках диапазона индекса. Чтобы перейти к их рассмотрению, вернитесь в сессию с идентификатором 55 и выполните команду отката транзакции:
--begin tran insert into test values(4,'other')
rollback
|
После этого нужно откатиться и в первой сессии:
--begin tran select * from test with (updlock)
--update test set n = 'other1' where i = 1
rollback
|
Блокировка диапазона ключа или индекса позволяет заблокировать данные на основе логического значения, такого, как выражение в разделе where. Кроме всего прочего, только этот тип блокировок позволяет эффективно решить проблему чтения фантомов. Эта проблема связана с тем, что даже при наличии уровня изоляции REPEATABLE READ вы можете получить разное количество строк, соответствующих определенному логическому условию в течение одной транзакции (кстати, логическое условие может и отсутствовать). Это может произойти из-за того, что не существует никаких ограничений на вставку новых строк, несмотря на то, что обновление выбранных строк заблокировано разделяемой блокировкой. Новые строки могут содержать значения, удовлетворяющие логическому запросу в разделе where, так что при следующем запросе количество строк в результирующей выборке изменится.
SQL Server поддерживает уровень SERIALIZABLE и для таблиц, не имеющих индекса. Однако в этом случае на всю таблицу целиком накладывается разделяемая блокировка до конца транзакции, что очень сильно снижает эффективность параллельной работы пользователей.
| ПРИМЕЧАНИЕ До выхода MS SQL Server 7.0 менеджер блокировок поступал таким образом (блокировал всю таблицу) с любыми таблицами, работа с которыми велась с уровнем изоляции SERIALIZABLE. |
Существует два вида блокировки индекса: блокировка самой записи индекса (index entry) и блокировка диапазона. Блокировка записи индекса эквивалентна блокировке строки, т.е. менеджер блокировок будет блокировать строку, если в таблице отсутствует индекс, или же будет блокировать запись индекса, которая соответствует данной строке. Поскольку индекс может быть построен по неуникальному полю, блокируемая запись не может быть идентифицирована только записью индекса, поэтому для вычисления локатора ресурса применяется алгоритм хеширования идентификатора строки (RID) и записи индекса.
Если бы в нашей таблице существовал индекс по полю i, то в предыдущей таблице блокировок в колонке Resource фигурировали бы хеш-значения записей индекса, а тип ресурса был – KEY.
Блокировка диапазона ключа существенно отличается от всего сказанного выше. Она позволяет наложить блокировку не на конкретные строки или записи индекса, а на диапазон строк, что позволяет блокировать записи по некоторому логическому условию. Естественно, что SQL Server не понимает логических выражений в том виде, каком понимает их автор запроса, и не может абсолютно точно наложить требуемую блокировку. Рассмотрим теоретические аспекты реализации блокировки по логическому условию.
Допустим, у нас есть диапазон значений от A до B. Если мы хотим прочитать какое-либо значение С, которое находится между A и B, но не равно им, возможны следующие варианты:
Если мы хотим вставить значение С, которое находится между A и B, то:
При удалении значения С, которое находится между A и B, возможны следующие ситуации:
При блокировании диапазона индекса SQL Server накладывает блокировку как на саму запись индекса, так и на диапазон значений от текущего значения ключа до ближайшего следующего. Диапазон может блокироваться только двумя способами: разделяемая блокировка и монопольная блокировка. Кроме этого, есть специальный тип блокировки диапазона, который применяется только для тестирования наличия других блокировок индекса и, соответственно, не совместим с ними. Не бывает блокировок диапазона без блокировки записи индекса, за исключением блокировки тестирования. Блокировка диапазона и блокировка записи индекса объединяются, формируя, таким образом, новые типы блокировок. Рассмотрим их (таблица 7).
| Диапазон | Запись индекса | Тип | Описание |
|---|---|---|---|
| RangeS | S | RangeS_S | Разделяемая блокировка диапазона, разделяемая блокировка записи индекса. |
| RangeS | U | RangeS_U | Разделяемая блокировка диапазона, блокировка обновления записи индекса. |
| RangeX | X | RangeX_X | Монопольная блокировка на диапазон и запись индекса. |
| RangeI | нет | RangeI_N | Блокировка тестирования. Применяется перед вставкой нового значения в диапазон. |
Блокировка диапазона накладывается на диапазон значений от текущего ключа до ближайшего следующего. Если следующего ключа не существует, блокировка накладывается на все значения, начиная с текущего. Так как один диапазон соответствует двум записям индекса, количество диапазонов должно быть меньше количества выбранных (или изменяемых) строк на 1. Но для того, чтобы защитить граничные значения записей индекса (например, от вставки такого же значения) накладывается еще две дополнительные блокировки индекса, расширяющие общий диапазон справа и слева. Таким образом, при выборе N’ого количества строк, количество блокировок диапазона будет всегда равно N+1.
В таблице 8 приведена матрица совместимости блокировок диапазона индекса.
| Тип | RangeS_S | RangeS_U | RangeX_X | RangeI_N |
|---|---|---|---|---|
| RangeS_S | + | + | - | - |
| RangeS_U | + | - | - | - |
| RangeX_X | - | - | - | + |
| RangeI_N | - | - | + | - |
| ПРИМЕЧАНИЕ Блокировка RangeI_N совместима с любым простым типом блокировки (даже с монопольной блокировкой) исключая Sch-M. |
Давайте рассмотрим несколько примеров, использующих блокировки диапазона. Для этого потребуется новая таблица, создать которую можно следующим образом:
create
table test_key(i int)
insertinto test_key values(3)
insertinto test_key values(5)
insertinto test_key values(7)
insertinto test_key values(9)
createnonclusteredindex _i_test_key on test_key(i)
|
Чтобы не напрягаться и не писать каждый раз begin tran, все соединения переключим в режим неявной транзакции, при котором SQL Server не выполняет автоматического фиксирования транзакции после успешного выполнения каждой команды. Новая транзакция начинается сразу же после ручного фиксирования текущей. Режимы переключаются с помощью следующей команды:
SET
IMPLICIT_TRANSACTIONS { ON | OFF }
|
Текущее состояние этой переменной можно определить следующим способом:
select
case
when (@@options & 2) = 2 then'IMPLICIT'else'NOT IMPLICIT'end |
В дальнейшем все примеры, если явно не оговорено другое, выполняются в режиме неявной транзакции.
Для начала посмотрим, что такое разделяемая блокировка диапазона:
set
implicit_transactions
on
select * from test_key with (serializable)
|
Если сейчас заглянуть в табличку syslockinfo или вызвать хранимую процедуру sp_lock, можно увидеть 5 блокировок типа RangeS_S. Значение в строке Resource однозначно идентифицирует запись индекса, однако для одной строки значение равно (ffffffffffff). Это говорит о том, что весь диапазон чисел от -INF до +INF (где INF - бесконечности) заблокирован. Если вы попытаетесь вставить в таблицу test_key значение, например, 68, у вас ничего не выйдет. Рассмотрим результаты вызова процедуры sp_lock (приведены сокращенно в таблице 9):
| spid | dbid | ObjId | IndId | Type | Resource | Mode | Status |
|---|---|---|---|---|---|---|---|
| 55 | 8 | 2009058193 | 2 | KEY | (ffffffffffff) | RangeS-S | GRANT |
| 56 | 8 | 2009058193 | 0 | RID | 1:29:04 | X | GRANT |
| 56 | 8 | 0 | 0 | PAG | 1:29 | IX | GRANT |
| 56 | 8 | 2009058193 | 2 | PAG | 1:34 | IX | GRANT |
| 56 | 8 | 2009058193 | 2 | KEY | (ffffffffffff) | RangeIn | WAIT |
| 56 | 8 | 2009058193 | 0 | TAB | IX | GRANT |
Так как тип блокировки RangeIn (aka RangeI) несовместим ни с каким другим типом блокировки диапазона, сессия за номером 56 блокируется. Примечательный факт – само значение все-таки было вставлено в таблицу, о чем свидетельствует выделенная строка, и только в момент обновления индекса возникла проблема совместимости блокировок. Чтобы убедится, что значение действительно было вставлено, можно воспользоваться командой dbcc page, которая подробно описана в следующем разделе. Кроме этого видно, что установлены блокировки намерений на таблицу и две страницы: страницу с данными и страницу, на которой располагается индекс.
| ПРИМЕЧАНИЕ Индекс располагается на другой странице вследствие того, что он является некластерным. |
Теперь отменим транзакцию и выполним такой код:
--set implicit_transactions on
--select * from test_key with (serializable)
delete
from test_key with (serializable) where i = 4
--rollback |
Здесь мы пытаемся удалить несуществующую строчку. В соответствии с тем, что наш запрос должен выдавать всегда один и тот же результат, менеджер блокировок должен обеспечить, что никакие другие транзакции не смогут вставить какое-либо значение в диапазон от 3 до 5, а также изменить граничные значения ключей на 4. Это достигается за счет установки разделяемой блокировки обновления диапазона.
| spid | dbid | ObjId | IndId | Type | Resource | Mode | Status |
|---|---|---|---|---|---|---|---|
| 55 | 8 | 2009058193 | 2 | KEY | (23005e3c905a) | RangeS-U | GRANT |
| 55 | 8 | 2009058193 | 2 | PAG | 1:34 | IU | GRANT |
Если бы удаляемое значение было равно, например, 40, догадайтесь, какой диапазон был бы заблокирован менеджером блокировок. :) Он бы заблокировал весь диапазон от 9 до положительной бесконечности. А что если бы граничные значения ключа составляли бы не 3 и 5, а 9 и 500? Был бы заблокирован диапазон от 9 до 500. Таковы требования высшего уровня изоляции транзакций!
Чтобы еще лучше усвоить правила блокировки диапазонов, попробуйте выполнить такой запрос:
--set implicit_transactions on
select * from test_key with (serializable) where i = 10
--delete from test_key with (serializable) where i = 4--rollback |
Он приведет к установлению разделяемой блокировки на диапазон от 9 до +INF, так что никакие операции вставки для этого диапазона не смогут быть выполнены.
Последний тип блокировок, рассматриваемых в этой статье, связан с командами DDL и схемой данных (Schema). Блокировка схемы (Schema lock) предназначена для блокирования метаданных объектов базы данных. Типичной командой изменения таких данных может служить команда ALTER. Эта команда приводит к изменению системных таблиц метаданных, таких, как syscolumns, sysobjects, sysforeignkeys и других. Чтобы запретить другим транзакциям обращаться к модифицируемым ресурсам и их метаданным, введены блокировки схемы. Блокировки схемы бывают всего двух типов:
Рассмотрим пример. В первой сессии выполните следующий код:
begin
tran
alter
table test add another_field int |
В таблице 11 приведено содержимое таблицы syslockinfo для данной сессии.
| spid | dbid | ObjId | IndId | Type | Resource | Mode | Status |
|---|---|---|---|---|---|---|---|
| 55 | 8 | 0 | 0 | DB | S | GRANT | |
| 55 | 8 | 1 | 0 | TAB | IX | GRANT | |
| 55 | 8 | 3 | 0 | TAB | IX | GRANT | |
| 55 | 8 | 3 | 2 | KEY | (31038b3afd68) | X | GRANT |
| 55 | 8 | 1993058136 | 0 | TAB | Sch-M | GRANT | |
| 55 | 8 | 1 | 1 | KEY | (5800c7965d9d) | X | GRANT |
| 55 | 8 | 3 | 1 | KEY | (5b00f3711a81) | X | GRANT |
| 55 | 8 | 0 | 0 | DB | S | GRANT |
Давайте проанализируем четыре выделенные строчки:
select * from sysindexes where id = 3 and indid = 2
|
select * from sysindexes where id = 1 and indid = 1
|
select * from sysindexes where id = 3 and indid = 1
|
Еще один тип блокировки – Bulk Update – используется совместно с операциями массивного обновления. Он совместим только с блокировкой стабильности схемы и с самим собой.
Блокировки могут преобразовываться друг в друга по следующей схеме (рисунок 1).
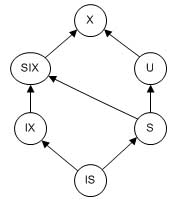
Рисунок 1.
Таблица 12 показывает совместимость описанных типов блокировок друг с другом.
| Тип | IS | S | U | IX | SIX | X | Sch-S | Sch-M | BU |
|---|---|---|---|---|---|---|---|---|---|
| IS | + | + | + | + | + | - | + | - | - |
| S | + | + | + | - | + | - | + | - | - |
| U | + | + | - | - | - | - | + | - | - |
| IX | + | + | - | + | - | - | + | - | - |
| SIX | + | + | - | - | - | - | + | - | - |
| X | - | - | - | - | - | - | + | - | - |
| Sch-S | + | + | + | + | + | + | + | - | + |
| Sch-M | - | - | - | - | - | - | - | - | - |
| BU | - | - | - | - | - | - | + | - | + |
Как уже говорилось ранее, для каждой сессии может быть выбран используемый по умолчанию уровень изоляции, действующий при выполнении любых команд T-SQL. Ниже я покажу, как это сделать.
Рассмотрим синтаксис команды установки уровня изоляции по умолчанию для текущего соединения.
SET
TRANSACTION
ISOLATION
LEVEL
{ READCOMMITTED
| READUNCOMMITTED
| REPEATABLEREAD
| SERIALIZABLE
}
|
Установка какого-либо значения остается действительной до конца сессии, или до тех пор, пока пользователь явно не изменит уровень изоляции транзакций.
Существует документированный способ просмотра текущего уровня изоляции с помощью команды DBCC USEROPTIONS, но лично я всегда пользуюсь более мощным, хотя и не документированным, средством. Чтобы узнать текущее значение изоляции, нужно воспользоваться таким скриптом:
dbcc traceon (3604)
dbcc pss(1,53)
dbcc traceoff (3604)
|
Команда dbcc pss предназначена для вывода текущих настроек указанного в параметре соединения. Вот ее синтаксис:
DBCC pss( suid, spid, printopt = { 1 | 0 } )
|
Эта команда выводит много интересной информации, но для нас главное – выяснить текущий уровень изоляции. Для этого нужно среди выведенных многочисленных переменных найти одну с названием isolation_level. В моем случае она оказалась равна 0. Это говорит о том, что для данного соединения используется уровень изоляции по умолчанию, который, как я уже говорил, равен READ COMMITTED. Вот все значения, которые может принимать эта переменная:
Теперь рассмотрим, каким образом управлять уровнем изоляции транзакций на уровне отдельных команд. Вот синтаксис раздела FROM, который относится к нашей теме (все сказанное ниже относится не только к запросам, но и к командам изменения данных DELETE и UPDATE):
FROM { < table_source > }
<table_source> ::=
table_name [ [ AS ] table_alias ] [ WITH ( < table_hint > [ ,...n ] ) ]
< table_hint > ::=
{ INDEX ( index_val [ ,...n ] )
| FASTFIRSTROW
| HOLDLOCK
| NOLOCK
| PAGLOCK
| READCOMMITTED
| READPAST
| READUNCOMMITTED
| REPEATABLEREAD
| ROWLOCK
| SERIALIZABLE
| TABLOCK
| TABLOCKX
| UPDLOCK
| XLOCK
}
|
Уровни READUNCOMMITTED и READCOMMITTED соответствуют одноименным уровням изоляции транзакций, только пишутся слитно. Блокировки при использовании этих уровней снимаются сразу после выполнения команды. В случае хинтов REPEATABLEREAD и SERIALIZABLE блокировки остаются до конца транзакции. Далее приводится подробное описание всех остальных хинтов.
select * from test with(tablock,holdlock)
|
Теперь давайте рассмотрим примеры их использования. Итак, у нас имеется таблица test следующего содержания (таблица 13).
| i | n |
|---|---|
| 1 | alex |
| 2 | rosa |
| 3 | dima |
Начнем с монопольных блокировок. В первой сессии выполните команду:
update test set n = 'other'where i = 2
|
К тому же результату (наложение монопольной блокировки на строку) привела бы команда
select * from test with(xlock) where i = 2
|
Теперь, во второй сессии:
select * from test with (nolock)
|
Вторая сессия не заблокировалась и выдала три строчки, включая измененную. Если бы мы не указали хинта nolock, сессия заблокировалась бы, так как по умолчанию установлен режим изоляции READ COMMITTED. Этому режиму необходима разделяемая блокировка, но так как монопольная блокировка не совместима ни с какой другой, менеджер блокировок заблокировал бы сессию.
Еще один интересный результат можно получить с помощью следующей команды (во второй сессии):
select * from test with (readpast)
|
Результаты ее выполнения зависят от того, какую команду мы выполнили в первой сессии. Если выполнялся запрос с хинтом xlock, результирующий набор будет содержать все строки таблицы. Однако если была выполнена команда UPDATE, SQL Server выдаст нам всего две строчки: 1 и 3. Такое поведение, признаться, для меня явилось неожиданностью, так как блокировки, накладываемые этими командами, полностью совпадают. У меня возникло предположение, что сервер каким-то образом помечает действительно измененные строки или вообще не вносит их в файл базы данных. Чтобы получить больше информации по этому поводу, воспользуемся очередной недокументированной возможностью, позволяющей просматривать физическое содержимое данных.
Но сначала я бы хотел рассмотреть содержимое колонки Resources, которую возвращает хранимая процедура sp_lock. Значение это состоит из трех цифр, разделенных двоеточием, первое из которых означает номер файла в базе данных, второе – номер страницы и третье – номер строки. Таким образом, запись 1:31:2 означает вторую строку на странице 31 в первом файле базы данных.
Вот синтаксис команды, с помощью которой можно получить физическое содержимое таблицы:
DBCC PAGE ({dbid|dbname}, filenum, pagenum [,printoption] [,cache])
|
| Значение | Описание |
|---|---|
| 0 | Установлен по умолчанию. Выводится только заголовок страницы. |
| 1 | Выводится заголовок страницы и содержимое каждой строчки. |
| 2 | Выводится заголовок страницы и полный дамп памяти. |
| 3 | Относительно новый флаг, который аналогичен флагу 1, с той разницей, что значения форматируются в удобочитаемый вид для каждой колонки. |
Откроем новую сессию и выполним следующий набор команд (у меня база, в которой содержится таблица test, имеет идентификатор 8):
dbcc traceon (3604)
dbcc page(8,1,31,3,1)
dbcc traceoff (3604)
|
Приведу результат, выводимый данной командой:
PAGE: (1:31) ------------ BUFFER: ------- BUF @0x00D88500 --------------- bpage = 0x19548000 bhash = 0x00000000 bpageno = (1:31) bdbid = 8 breferences = 1 bstat = 0xb bspin = 0 bnext = 0x00000000 PAGE HEADER: ------------ Page @0x19548000 ---------------- m_pageId = (1:31) m_headerVersion = 1 m_type = 1 m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x0 m_objId = 1993058136 m_indexId = 0 m_prevPage = (0:0) m_nextPage = (0:0) pminlen = 8 m_slotCnt = 3 m_freeCnt = 8026 m_freeData = 247 m_reservedCnt = 0 m_lsn = (6:181:2) m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 m_tornBits = 0 Allocation Status ----------------- GAM (1:2) = ALLOCATED SGAM (1:3) = ALLOCATED PFS (1:1) = 0x61 MIXED_EXT ALLOCATED 50_PCT_FULL DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED Slot 0 Offset 0x60 ------------------ Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 19548060: 00080030 00000001 02000002 15001100 0............... 19548070: 656c6100 78 .alex i = 1 n = alex Slot 1 Offset 0xe1 ------------------ Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 195480E1: 00080030 00000002 02000002 16001100 0............... 195480F1: 68746f00 7265 .other i = 2 n = other Slot 2 Offset 0x8a ------------------ Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS 1954808A: 00080030 00000003 02000002 15001100 0............... 1954809A: 6d696400 61 .dima i = 3 n = dima |
Отсюда можно сделать вывод, что данные обновляются непосредственно, а менеджер блокировок следует какому-то специальному алгоритму, проверяющему лог транзакций (transaction log), при использовании хинта readpast.
На будущее хочу заметить, что тип страницы (выделен) может принимать несколько значений, из которых для нас важны два: 1 – для страниц данных, 2 – для страниц индексов.
Давайте продвигаться дальше. Так как в данный момент у нас заблокирована одна строка (вторая), попытаемся во второй сессии выполнить такой запрос:
--select * from test with (readpast)
select * from test where i = 1
|
Ура! Наконец-то она заблокировалась! :) Это произошло потому, что в отсутствии индекса на таблице оптимизатор выполняет полное сканирование таблицы для поиска строк, удовлетворяющих заданному логическому условию. При этом он неизбежно натыкается на заблокированную строчку, что приводит к блокировке транзакции. Вот какие блокировки установлены на текущий момент (сокращенно, таблица 15):
| ObjId | IndId | Type | Resource | Mode | Status |
|---|---|---|---|---|---|
| 1993058136 | 0 | PAG | 1:31 | IS | GRANT |
| 1993058136 | 0 | PAG | 1:31 | IX | GRANT |
| 1993058136 | 0 | TAB | IS | GRANT | |
| 1993058136 | 0 | TAB | IX | GRANT | |
| 1993058136 | 0 | RID | 1:31:01 | X | GRANT |
| 1993058136 | 0 | RID | 1:31:01 | S | WAIT |
| 1993058136 | 0 | PAG | 1:31 | IS | GRANT |
| 1993058136 | 0 | PAG | 1:31 | IX | GRANT |
| 1993058136 | 0 | TAB | IS | GRANT | |
| 1993058136 | 0 | TAB | IX | GRANT |
Мы видим, что на первую строку наложена монопольная блокировка и какой-то процесс (а точнее, наша вторая сессия) хочет получить на эту же строку разделяемую блокировку. Чтобы решить эту проблему, нужен индекс. Но прежде нужно разобраться с текущей ситуацией.
Предположим, вы не имеете доступа к сессиям 54 и 55, которые в данный момент конкурируют в получении доступа к ресурсам, и не можете выполнить команды фиксации транзакции или отката. Единственным возможным выходом из сложившейся ситуации является убиение одного из процессов. Для получения подробной информации о процессе можно воспользоваться хранимой процедурой sp_who и ее недокументированным аналогом sp_who2. Последняя возвращает значительно больше информации, однако результаты выполнения обеих содержат колонку cmd, в которой хранится тип выполняющейся команды, если процесс заблокирован, или AWAITING COMMAND – если все нормально.
Для получения более подробной информации о выполняющейся команде можно использовать следующую команду:
DBCC INPUTBUFFER (55)
|
Эта команда возвращает такой результат:
EventType Parameters EventInfo -------------- ---------- ----------------------------------------------- Language Event 0 --SET IMPLICIT_TRANSACTIONS on --select * from test where i = 1 |
Эта команда может использоваться для просмотра первых 255 символов команд для заданной сессии.
После того, как выяснится жертва, можно вызывать команду KILL.
Однако все это не про нас, вернемся к первой сессии (с номером 54) и отменим транзакцию:
--SET IMPLICIT_TRANSACTIONS on
--update test set n = 'other' where i = 2
rollback
|
Вторая сессия моментально разблокируется, после чего в ней также нужно откатить транзакцию:
--SET IMPLICIT_TRANSACTIONS on
--select * from test with (readpast)
--select * from test where i = 1
rollback
|
Давайте создадим некластерный индекс и выполним те же самые действия. Откройте новую сессию и выполните следующую команду:
create
nonclustered
index _i_idx on test(i)
|
Теперь в первой сессии выполним обновление записи:
--SET IMPLICIT_TRANSACTIONS on
update test set n = 'other'where i = 2
--rollback |
А во второй – запрос:
--SET IMPLICIT_TRANSACTIONS on
--select * from test with (readpast)
select * from test with (xlock) where i = 1
--rollback |
Чтобы увидеть блокировки второй сессии, я поставил хинт xlock. Запрос не заблокируется, давайте посмотрим содержимое syslockinfo (таблица 16).
| spid | dbid | ObjId | IndId | Type | Resource | Mode | Status |
|---|---|---|---|---|---|---|---|
| 55 | 8 | 1993058136 | 0 | RID | 1:31:00 | X | GRANT |
| 55 | 8 | 1993058136 | 0 | PAG | 1:31 | IX | GRANT |
| 54 | 8 | 1993058136 | 0 | PAG | 1:31 | IX | GRANT |
| 55 | 8 | 1993058136 | 3 | PAG | 1:29 | IX | GRANT |
| 55 | 8 | 1993058136 | 0 | TAB | IX | GRANT | |
| 54 | 8 | 1993058136 | 0 | TAB | IX | GRANT | |
| 54 | 8 | 1993058136 | 0 | RID | 1:31:01 | X | GRANT |
| 55 | 8 | 1993058136 | 3 | KEY | (21001d31a802) | X | GRANT |
Как видим, первая сессия наложила монопольную блокировку на первую строку 1:31:01, а вторая – на нулевую 1:31:00. Кроме этого, вторая сессия наложила монопольную блокировку на ключ (последняя строка) и монопольную блокировку намерений на страницу, где располагается индекс (1:29).
Чтобы действительно убедиться, что индекс создан именно на этой странице, нужно выполнить очередную недокументированную команду:
extentinfo [({'database_name'| dbid} [, {'table_name' | table_id} [, {'index_name' | index_id}]])]
|
| ПРИМЕЧАНИЕ Для получения полного списка команд DBCC (Database Console Commands) можно воспользоваться такой командой: dbcc traceon (2520) dbcc help('?') dbcc traceoff (2520) Чтобы получить синтаксис конкретной команды, например, page, выполните такую последовательность: dbcc traceon (2520) dbcc help('page') dbcc traceoff (2520) |
В нашем случае следующий набор команд покажет все страницы таблицы test:
dbcc traceon (3604)
dbcc extentinfo(8,'test')
dbcc traceoff (3604)
|
В колонке page_id указаны идентификаторы страниц, а в колонке index_id – идентификаторы индекса. Просмотрим содержимое страницы индекса:
dbcc traceon (3604)
dbcc page(8,1,29,1,1)
dbcc traceoff (3604)
|
Вот результат работы данной команды:
PAGE: (1:29) ------------ BUFFER: ------- BUF @0x00DA2740 --------------- bpage = 0x1A25A000 bhash = 0x00000000 bpageno = (1:29) bdbid = 8 breferences = 1 bstat = 0x9 bspin = 0 bnext = 0x00000000 PAGE HEADER: ------------ Page @0x1A25A000 ---------------- m_pageId = (1:29) m_headerVersion = 1 m_type = 2 m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x4 m_objId = 1993058136 m_indexId = 3 m_prevPage = (0:0) m_nextPage = (0:0) pminlen = 13 m_slotCnt = 3 m_freeCnt = 8042 m_freeData = 144 m_reservedCnt = 0 m_lsn = (6:181:20) m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 m_tornBits = 839385609 Allocation Status ----------------- GAM (1:2) = ALLOCATED SGAM (1:3) = ALLOCATED PFS (1:1) = 0x60 MIXED_EXT ALLOCATED 0_PCT_FULL DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED DATA: ----- Slot 0, Offset 0x60 ------------------- Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP 1A25A060: 00000116 00001f00 00000100 00000300 ................ Slot 1, Offset 0x70 ------------------- Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP 1A25A070: 00000216 00001f00 01000100 00000300 ................ Slot 2, Offset 0x80 ------------------- Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP 1A25A080: 00000316 00001f00 02000100 00000300 ................ |
Так как тип страницы, указанный в заголовке, равен 2, данная страница является индексной. Кроме этого, значение m_indexId равно идентификатору индекса.
| ПРИМЕЧАНИЕ Информацию обо всех индексах данной таблицы можно получить с помощью такого запроса: select * from sysindexes where id = object_id('test') |
На этом я закончу рассматривать хинты SQL Server’а и блокировки и перейду к проблеме взаимоблокировок (deadlocks). Не забудьте завершать транзакции в 54 и 55 сессиях.
| СОВЕТ Для определения текущего количества незавершенных транзакций можно воспользоваться функцией @@trancount. |
В процессе работы параллельных транзакций, обращающихся к одним и тем же ресурсам, возможно возникновение проблемы взаимоблокировок (deadlock), которые также называют тупиковыми блокировками. Если транзакции обращаются к ресурсам последовательно, вероятность возникновения взаимоблокировки очень мала, однако если порядок обращения транзакций к общим ресурсам разный, возможность возникновения мертвой блокировки повышается многократно.
Рассмотрим суть взаимоблокировки на двух транзакциях (t1 и t2), обращающихся к двум ресурсам (A и B). Предположим, что транзакция t1 блокирует ресурс A, после чего транзакция t2 блокирует ресурс B. Если теперь транзакция t1 попытается получить доступ к ресурсу B, а транзакция t2 – к ресурсу А, возникнет взаимоблокировка. В таком состоянии транзакции не могут разрешить конфликт и переходят в состояние ожидания на неопределенно долгий срок. Чтобы изменить время ожидания ресурса для текущего соединения, используется следующая команда:
SET
LOCK_TIMEOUT timeout_period
|
timeout_period задается в миллисекундах. Если указывается значение –1, менеджер транзакций будет ждать освобождения ресурса неопределенно долгое время.
В SQL Server’е предусмотрен механизм автоматического определения взаимоблокировок и разрешения конфликтов. Для этого предназначен специальный серверный процесс LOCK MONITOR, который просыпается каждые 5 секунд [2]. Он проверяет наличие двух и более ожидающих транзакции и вычисляет зависимости между ними. Если оказывается, что транзакции зависят друг от друга, т.е. для получения блокировки одной из них необходимо снять блокировку другой транзакции, фиксируется факт возникновения взаимоблокировки. Единственный способ устранения проблемы заключается в отмене одной из транзакций. Но какой? Для каждой транзакции вводится понятие цены или приоритета. Это значение задается на уровне соединения следующей командой:
SET
DEADLOCK_PRIORITY { LOW | NORMAL | @deadlock_var }
|
Задание меньшего приоритета для соединения приводит к откату транзакций при возникновении взаимоблокировок с кодом ошибки 1205.
Давайте рассмотрим простой пример взаимоблокировки. Для большей наглядности я продемонстрирую его на одной таблице из трех (!) строк.
Итак, мы продолжаем работать с нашей таблицей test, на поле i которой создан некластерный индекс.
В первой сессии выполним такой запрос:
SET
IMPLICIT_TRANSACTIONS
on
select * from test with(updlock) where i = 2
|
Здесь мы наложили блокировку обновления на вторую строку таблицы. Теперь во второй сессии введем следующий код:
SET
IMPLICIT_TRANSACTIONS
on
select * from test with (updlock) where i = 1
|
Та же блокировка обновления накладывается на первую строчку. Перейдем снова к первой сессии:
--SET IMPLICIT_TRANSACTIONS on
--select * from test with(updlock) where i = 2
update test set n = (select n from test where i = 2) where i = 1
|
Так как мы пытаемся получить на первую строку монопольную блокировку, которая несовместима с текущей блокировкой обновления, сессия блокируется.
Теперь во второй сессии введем похожую команду:
--SET IMPLICIT_TRANSACTIONS on
--select * from test with (updlock) where i = 1
update test set n = (select n from test where i = 1) where i = 2
|
Вот она, взаимоблокировка! Обе сессии заблокированы. Однако наше ликование будет недолгим: примерно через 5 секунд менеджер блокировок сообразит, что возникла взаимоблокировка и откатит первую транзакцию.
Server: Msg 1205, Level 13, State 50, Line 3 Transaction (Process ID 58) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction. |
Конечно, пример несколько надуманный, зато он хорошо иллюстрирует проблему: на пустом месте можно получить взаимоблокировку даже на табличке из двух строк.
При написании хранимых процедур, которые и являются основным источником взаимных блокировок, необходимо руководствоваться следующим простым правилом: если две и более транзакций используют совместные ресурсы, порядок наложения однотипных блокировок на эти ресурсы должен быть одинаковым.
Это правило помогает, но не во всех случаях. Рассмотрим такой пример. В первой сессии выполняем команду:
set
implicit_transactions
on
select * from test with (repeatableread)
|
Это приводит к наложению разделяемых блокировок на все строки таблицы test. Во второй сессии выполняем тот же запрос:
set
implicit_transactions
on
select * from test with (repeatableread)
|
Так как разделяемая блокировка совместима сама с собой, запрос выполняется нормально.
Блокировки для первой строки приведены в таблице 17.
| spid | dbid | ObjId | IndId | Type | Resource | Mode | Status |
|---|---|---|---|---|---|---|---|
| 55 | 8 | 1993058136 | 0 | RID | 1:31:00 | S | GRANT |
| 57 | 8 | 1993058136 | 0 | RID | 1:31:00 | S | GRANT |
Нас интересует именно первая строка, так как сейчас мы попытаемся в первой сессии изменить данные:
--set implicit_transactions on
--select * from test with (repeatableread)
update test set n = 'other'where i = 1
|
Сессия блокируется, так как монопольная блокировка, необходимая для выполнения изменения, не совместима с разделяемой. Теперь блокировки выглядят так, как показано в таблице 18.
| spid | dbid | ObjId | IndId | Type | Resource | Mode | Status |
|---|---|---|---|---|---|---|---|
| 55 | 8 | 1993058136 | 0 | RID | 1:31:00 | S | GRANT |
| 57 | 8 | 1993058136 | 0 | RID | 1:31:00 | U | GRANT |
| 57 | 8 | 1993058136 | 0 | RID | 1:31:00 | X | CNVT |
Обнаружив нужную строчку, сервер пытается преобразовать текущую разделяемую блокировку в блокировку обновления, что ему удается. Это делается для того, чтобы после нахождения нужного ресурса в процессе подготовительных операций перед обновлением никакая другая транзакция не смогла получить блокировку на изменение (блокировку обновления или монопольную блокировку). Затем, непосредственно перед обновлением, сервер пытается преобразовать текущую блокировку обновления в монопольную, что ему, естественно, не удается.
Если теперь выполнить во второй сессии ту же команду:
--set implicit_transactions on
--select * from test with (repeatableread)
update test set n = 'other'where i = 1
|
мы получим мертвую блокировку. Причем во второй сессии транзакция даже не сможет преобразовать разделяемую блокировку в блокировку обновления, так как блокировка обновления не совместима сама с собой.
Чтобы избавиться от подобных ситуаций, нужно устанавливать при запросе данных вместо разделяемой блокировки сразу блокировку обновления. В этом случае вторая сессия будет заблокирована на команде выборки данных до завершения транзакции в первой сессии. Однако и при установке блокировки обновления нельзя быть уверенным, что не произойдет взаимного блокирования транзакций. Если во второй сессии просто выполнить запрос с уровнем изоляции REPEATABLE READ, на все строки опять будет установлена разделяемая блокировка, и при попытке обновления записи в первой сессии, транзакция будет заблокирована. Единственным выходом из ситуации, когда происходит выполнение транзакций с разными уровнями изоляции, будет наложение монопольных блокировок на все строки при запросе данных в первой сессии. Хотя такой метод строго не рекомендуется, он возможен, благодаря наличию хинта xlock. Если вносимые транзакцией изменения будут затрагивать более 70% таблицы, есть смысл вместо xlock установить хинт tablockx, хотя менеджер блокировок достаточно умен, чтобы самостоятельно выполнить эскалацию блокировок.
В заключение я хочу рассмотреть вопросы, которые не были затронуты в данной статье, но могут иметь определенный интерес.
Возможно, вы не задумывались над этим вопросом, или думали, что владельцем всех блокировок является менеджер блокировок, однако это не так. У каждой блокировки есть владелец, и его можно найти в таблице syslockinfo в поле req_ownertype. Это поле может принимать три значения: 1, 2 и 3. Если значение равно 1, владельцем блокировки является транзакция – это самая распространенная ситуация. Если req_ownertype равен 2 – владельцем является курсор, созданный с опцией SCROLL_LOCKS. И, наконец, значение 3 говорит о том, что владельцем транзакции является сессия. Как правило, объектом подобной блокировки является база данных, а сама блокировка накладывается в момент выполнения команды use [database] и снимается, когда выполняется другая команда use, или завершается сессия.
По умолчанию SQL Server выбирает наиболее подходящий, по его мнению, уровень детализации блокировок и выполняет эскалацию блокировок при увеличении их количества. Вы можете задать другую стратегию блокировки непосредственно в самом запросе, с помощью хинтов, а можете (только для индексов) указать заранее степень детализации объектов блокировок. Делается это с помощью хранимой процедуры sp_indexoption. Вот ее синтаксис:
sp_indexoption [ @IndexNamePattern = ] 'index_name' , [ @OptionName = ] 'option_name' , [ @OptionValue = ] 'value' |
| Имя опции | Описание |
|---|---|
| AllowRowLocks | Если установлена в TRUE, разрешает использования блокировок на уровне строк. |
| AllowPageLocks | Если установлена в TRUE, разрешает использования блокировок на уровне страниц. |
| DisAllowRowLocks | Если установлена в TRUE, запрещает использование блокировок на уровне строк. |
| DisAllowPageLocks | Если установлена в TRUE, запрещает использование блокировок на уровне страниц. |
Рассмотрим пример ее использования. Следующий запрос установит около сотни блокировок, в чем можно убедиться, воспользовавшись хранимой процедурой sp_lock.
set
implicit_transactions
on
select City from Customers with (repeatableread)
|
Однако если перед этим запросов вызвать хранимую процедуру sp_indexoption следующим образом:
EXEC sp_indexoption 'Customers.City', 'allowrowlocks', false
|
Будет установлена всего одна (!) разделяемая блокировка на таблицу Customers.
В SQL Server 2000 появились две новые процедуры, предназначенные для работы с пользовательскими блокировками. Пользовательские блокировки позволяют решить проблему доступа к тем ресурсам, на которые не распространяется действие менеджера блокировок. Например, когда вы хотите защитить отдельный столбец в таблице или вызов хранимой процедуры, пользовательские блокировки являются лучшим выходом.
| ПРИМЕЧАНИЕ Возможно также написание расширенных хранимых процедур, в которых использовались бы механизмы синхронизации операционной системы. До выхода SQL Server 2000 это был единственный метод. |
Рассмотрим синтаксис процедур.
sp_getapplock [ @Resource = ] 'resource_name', [ @LockMode = ] 'lock_mode' [ , [ @LockOwner = ] 'lock_owner' ] [ , [ @LockTimeout = ] 'value' ] |
Чтобы убедиться, что ресурс захвачен, необходимо проверить возвращаемое значение функции. Если оно больше или равно 0, ресурс захвачен, если нет – произошла ошибка. Все возможные значения приведены в таблице 20.
| Значение | Описание |
|---|---|
| 0 | Ресурс успешно захвачен. |
| 1 | Ресурс был захвачен после определенного ожидания. |
| -1 | Ресурс захвачен не был, произошел возврат по таймауту. |
| -2 | Запрос на ресурс был прерван. |
| -3 | Запрос на ресурс был прерван вследствие возникновения мертвой блокировки. |
| -999 | В процедуру были переданы неверные параметры. |
После успешного захвата ресурса вы можете быть уверены, что обладаете тем типом доступа, который запросили. После работы с ресурсом, необходимо вызвать процедуру sp_releaseapplock. Вот ее синтаксис:
sp_releaseapplock [ @Resource = ] 'resource_name' [ , [ @LockOwner = ] 'lock_owner' ] |
Эта процедура должна быть вызвана столько раз, сколько вызывалась процедура sp_getapplock.
Примеры использования данной связки имеются в MSDN.
На этом я заканчиваю статью, надеюсь, она оказалась для вас интересной и полезной в практическом плане.
| Оценка 355
[+1/-0]
Оценить
|