 Оценка 541
[+1/-1]
Оценка 541
[+1/-1]

 Оценить
Оценить 



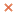


| Оценка 541
[+1/-1]
Оценить
|
| Часть 1. C и C-подобные языки Часть 2. Pascal Часть3. Сравнение методов оптимизации Дополнительные ресурсы |  |
Так уж сложилось, что большинство ПО в нашей стране разрабатывается для Windows. И так уж сложилось, что в основном при этом используются средства разработки, созданные Microsoft или Borland. Однако свет на этих двух фирмах клином не сошелся. В мире есть немало других средств разработки, начиная от “монстров” и заканчивая множеством бесплатно распространяемых средств разработки. О некоторых подобных средствах и рассказывается в данной статье.
Оставим рассказы о больших (и дорогих!) продуктах их создателям, и сосредоточимся на бесплатных продуктах, которым, как правило, перепадает гораздо меньше внимания.
Все бесплатные средства разработки можно разделить на три группы. Первые — это компиляторы, разработанные в рамках GNU, например, GCC. За редким исключением под Linux они работают намного лучше, чем под Windows. Это неудивительно, так как они разрабатывались для работы в *nix, а затем были портированы в Windows. Кроме того, в мире UNIX существуют свои стандарты, которые Windows-программисту могут показаться несколько странными (например, другой синтаксис ассемблерных команд). Обычно в портированных компиляторах все эти «причуды» сохраняются.
Компиляторы для Linux как правило распространяются под лицензией GPL (GNU Public License). Это означает, что вы можете бесплатно скачать сам компилятор и его исходные тексты, можете запускать их на любом числе компьютеров, передавать своим друзьям и даже перепродавать (но в этом случае вы не можете брать денег больше, чем вы потратили на носитель, копирование, оформление, упаковку и доставку покупателю, а также на другие услуги, осуществлённые вами). Фирмы-разработчики таких компиляторов получают прибыли за счет выпуска дисков в красивых коробках, которые они продают так же, как и коммерческие программы (через магазины, через интернет). Многие люди покупают коробочные варианты, но при этом они получают возможность обращаться со своими вопросами в службу технической поддержки фирмы-издателя. Кроме того, к диску обычно прилагается некоторый набор документации. В остальном никакой разницы между поставкой на диске и закачкой из интернета нет – тот же самый компилятор и его исходники.
Вторая категория — устаревшие программы, которые раньше успешно продавались, а теперь фирмы-разработчики раздают их бесплатно (сюда относятся уже упомянутый Turbo Pascal, Watcom C++ и еще несколько компиляторов под DOS). Ни одного Windows-компилятора в этой категории вы не найдете.
Третья и самая привлекательная категория — это компиляторы, изначально разработанные под Windows. Такие проекты обычно поддерживаются либо энтузиастами, либо фирмами, работающими под той же лицензией GPL.
Сайт:
http://www.cs.virginia.edu/~lcc-win32/
Скачать:
ftp://ftp.cs.virginia.edu/pub/lcc-win32/lccwin32.exe (компилятор и среда разработки, 3.7 Мб)
ftp://ftp.cs.virginia.edu/pub/lcc-win32/win32hlp.exe (документация по Win32 API, 12.8 Мб)
LCC-Win32 — это бесплатные компилятор и интегрированная среда разработки C для Windows. С его помощью вы можете создавать полноценные Win32-приложения (прилагается редактор ресурсов и даже простой графический редактор), консольные приложения для Windows и DLL-библиотеки. LCC распространяется на следующих условиях: компилятор и среду разработки можно скачать и использовать бесплатно, кроме того, предлагается купить диск с исходными текстами компилятора и примерами программ (от 30 до 105 евро в зависимости от комплектации).
Компилятор LCC реализован для различных платформ (для Windows, Linux и Solaris — см. http://www.cs.princeton.edu/software/lcc/). Как удалось выяснить из анализа откомпилированного кода, оптимизация (под Windows) в нем довольно слабая (по сравнению с компиляторами VC++, Intel C++ или GCC). Несмотря на это, LCC создает очень компактные программные файлы («Hello, World» с одним окном занимает 7 Кб, простое консольное приложение — 3 Кб). В чем же здесь секрет? Оказывается, все создаваемые программы, использующие стандартные функции C (например, printf, sqrt, strcmp), динамически, а не статически «прилинковывают» библиотеку crtdll.dll, что, разумеется, значительно уменьшает размер исполняемого файла. Указанная библиотека присутствует в дистрибутиве Windows, и распространять со своими приложениями ее не нужно. Но функции эти вызываются очень часто, и такое решение несколько снижает производительность (особенно если вы используете стандартную функцию в цикле).
Перейдем к описанию среды разработки. Редактор кода поддерживает поиск и замену с подстановочными знаками, сравнение файлов, переход между описанием и реализацией переменных и классов, всплывающие подсказки для аргументов функций (только для собственных функций, но не для библиотечных). Очень удобно, что некоторые ошибки (имена несуществующих переменных и функций) подчеркиваются прямо при вводе текста программы. Отлично спланированный мастер создает заготовку приложения, позволяя выбирать множество параметров. Кроме того, имеются инструменты для управления версиями программ (можно записывать версии в хранилище и извлекать их, сравнивать версии).
Интерфейс редактора ресурсов похож на последние версии Visual Studio или C++ Builder: панель с элементами управления спрятана в выпадающее меню и не занимает места на экране, текущий элемент можно выбирать из списка. Можно посетовать только на нестабильную работу редактора ресурсов — у меня он периодически «вылетал» с сообщением о критической ошибке. Кроме того, если вы установили программу в каталог, имя которого содержит пробелы (например, «Program files»), то вам не удастся даже запустить редактор ресурсов (разработчики честно предупреждают об этом, хотя лучше бы им это устранить).
Очень неплох отладчик. Он показывает значения переменных в виде всплывающих подсказок, позволяет наблюдать за изменением переменных в окнах Auto Watch, Locals и Watch, просматривать стек вызова процедур, отлаживать программу на уровне машинного кода, отслеживая регистры и память. Если в результате оптимизации переменная будет перенесена в регистр, отладчик укажет на это. Встроенный профилировщик показывает время выполнения, частоту вызовов процедур и даже отдельных строк кода.
Итак, оптимизация в компиляторе LCC довольно слаба, но среда разработки позволяет писать и отлаживать программы с некоторым комфортом. Если для вас некритична скорость выполнения программ, но важен их размер, LCC будет хорошим выбором.
Сайт:
http://bloodshed.net/dev/devcpp.html
Скачать:
http://prdownloads.sourceforge.net/dev-cpp/devcpp4980.exe (компилятор и среда разработки, 12.0 Мб)
http://prdownloads.sourceforge.net/dev-cpp/devcpp4980exe.exe (только среда разработки, 2.38 Мб)
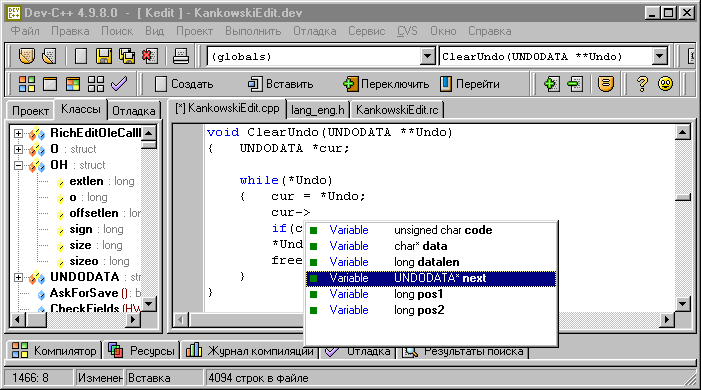
MinGW — это порт линуксовского компилятора GCC, а Dev-C++ — IDE, по умолчанию использующая этот компилятор, но также позволяющая работать и с другими компиляторами, совместимыми с GCC, например, CygWin. Эта IDE также распространяется под лицензией GPL. Редактор кода можно только похвалить, ибо он значительно облегчает повседневную работу программиста с помощью шаблонов кода, всплывающих подсказок для функций и автозавершения со списком членов класса или структуры. В дистрибутив включена краткая справка и примеры. В наличии имеется также поддержка скинов, закладок, переназначения клавиш и различных вариантов подсветки синтаксиса. Но самое приятное то, что среда Dev-C++ многоязычная, и есть русский вариант перевода.
Теперь о грустном. Во всем двенадцатимегабайтном дистрибутиве не нашлось места для редактора ресурсов, и вам остается либо редактировать их в текстовом виде, либо искать утилиту от сторонних разработчиков (неплохим выбором будет, например, Resource Hacker — http://www.users.on.net/johnson/resourcehacker/). Имеется интеграция с системой управления версиями CVS.
Отладка ваших программ выполняется также через внешний GNU Debugger. Внешне это немного напоминает отладчик в Visual C++ 6.0. Можно отслеживать значения переменных (если задержать курсор над именем переменной, она добавляется в список отладки), прогонять программу по шагам, просматривать машинный код и регистры процессора.
Но меня, как фанатика оптимизации, заинтересовал в первую очередь компилятор. Red Hat на своем сайте говорит, что GCC поддерживает десятки передовых методик оптимизации (http://www.redhat.com/software/gnupro/technical/gnupro_gcc.html). Могу с ответственностью заявить: все эти суперметоды при портировании на Windows благополучно перекочевали в MinGW, ибо для контрольных программ он генерировал код примерно такого же качества, как Visual C++. Подробнее вопрос оптимизации обсужден в конце статьи. Жаль только, что нет возможности выбрать преимущественную оптимизацию по скорости или по размеру, как в компиляторах от Microsoft и Intel.
Скорость компиляции невелика даже при выключенной оптимизации. Другая неприятная особенность: как и LCC, MinGW использует функции из дополнительной библиотеки msvcrt.dll, что снижает производительность и может вызывать проблемы с версией библиотеки, ее наличием на компьютере пользователя и т. п. Размер программ почему-то не становится от этого намного меньше, и программа с одним пустым окном занимает 13 Кбайт. Кроме того, в бета-версии Dev-C++ мне не удалось отключить добавление отладочной информации (пришлось удалять ее с помощью шестнадцатеричного редактора).
Выводы: компилятор MinGW генерирует очень качественный код, но занимает много места и работает довольно медленно. Возможны также проблемы с библиотекой msvcrt.dll (по адресу http://mingwacr.sourceforge.net можно найти исходники альтернативной run-time-библиотеки, но, к сожалению, она еще находится в стадии разработки). Разработчики Dev-C++ уделили большое внимание внешней стороне (скинам, сложным настройкам, поддержке различных языков), но забыли о редакторе ресурсов, без которого невозможно создавать полноценные приложения для платформы Win32.
Существует и другой порт компилятора GCC на платформу Win32 — Cygwin, http://www.cygwin.com. Он предназначен, прежде всего, для переноса программ с Linux. Его DLL реализует Unix-подобные функции на платформе Win32, и POSIX-программа может обращаться к этим функциям, как она обращалась бы к «родным» функциям *nix. Впрочем, Win32-приложения не привязаны к этой библиотеке, и используют статически связанный с ними run-time. Степень оптимизации Cygwin полностью аналогична MinGW, так как оба они основаны на одном и том же компиляторе GCC. Размер дистрибутива — около 19 Mb, можно скачать также портированные с Linux утилиты общим объемом в две сотни мегабайт. Ранние дистрибутивы Cygwin состояли из одного файла, сейчас же нужно скачать небольшой инсталлятор (260 Кб) и выбрать в нем компоненты для установки. Инсталлятор найдет ближайшее к вам зеркало FTP-сервера, скачает и установит все компоненты.
Сайт:
http://www.borland.com/products/downloads/download_cbuilder.html
Скачать:
ftp://ftpd.borland.com/download/bcppbuilder/freecommandLinetools.exe (8,5 Мб, компилятор и утилиты)
Borland предлагает бесплатно скачать свой компилятор C++, компоновщик, компилятор ресурсов, утилиту пакетной компиляции Make, Grep для поиска файлов и некоторые другие программы командной строки. Прилагается краткая справка и примеры к STL. Компилятор более чем средний (см. итоговую таблицу), но создаваемые программы не привязаны ни к какой библиотеке и имеют размер от 50 Kb.
Существует множество бесплатных редакторов кода с возможностью подключения компиляторов (см. например, http://www.lancs.ac.uk/people/cpaap/pfe, http://www.fixedsys.com/context/, http://cedit.sourceforge.net/). Настроив их для работы с BCC и запуска упомянутого выше Resource Hacker (http://www.users.on.net/johnson/resourcehacker/), вы получите более или менее работоспособную среду разработки, в которой не хватает только отладчика.
Сайт:
Скачать:
ftp://ftp.digitalmars.com/dmd.zip (компилятор, 4.5 Мб)
Как известно, у языка C были предшественники, называвшиеся A и B. Язык D (читается «ди») — это попытка не только продолжить традиции C и C++, но и создать на их основе новый язык программирования. Основной синтаксис языка — классы, функции, условия, циклы — остался прежним. Ниже перечислены некоторые возможности этого языка:
// Было в C:
int *a = (int*)malloc(10 * sizeof(int)); // Выделили память для 10 чисел
a = (int*)realloc(a, N * sizeof(int)); // Изменили размер выделенного блока
free(a); // Освободили указатель// Стало в D:int[10] a; // Массив из десяти элементов
a.size = N; // Изменяем его размер |
int[char[]] dict; // ассоциативный массив целых чисел с индексом-строкой
dict[»home»] = 2; // ассоциировать с элементом home число 2
dict[»tree»] = 5; // ассоциировать с элементом tree число 5 |
int[10] a;
a[10..19] = a[0..9]; // Скопировать первые 10 элементов в следующие 10
a[0..9] = 0; // Обнулить первые 10 элементовint[] b = a[2..5]; // b – динамический массив, в который будут// скопированы элементы массива a с 2 до 5
b[] += 5; // Увеличить все элементы на 5
b.sort; // Отсортировать b по возрастанию |
bit[80] a; // Массив из 80 битов (10 байт) |
Label: for(i = 0; i < 10; ++i) for(j = 0; j < 10; ++j) if (a[i, j] == 0) break Label; // Прервать цикл по i |
char[] str = \t "Текст на
нескольких
строках
";
|
class Window // Описание и реализация
{
void Height(int newheight){ // Устанавливаем ширину окна
RECT rect;
GetWindowRect(m_hwnd, rect);
SetWindowPos(m_hwnd, 0, 0, 0, rect.width, hewheight,
SWP_NOZORDER | SWP_NOACTIVATE | SWP_NOMOVE);
}
int Height() { // Запрашиваем ширину окна у Windows
RECT rect;
GetWindowRect(m_hwnd, rect);
return rect.height;
}
}
Window wnd; // Использованиеif(wnd.height < 200) // Здесь будет вызвано чтение свойства
wnd.height = 200; // Здесь будет вызвана запись свойства |
b = cast(B) a; |
Итак, язык D можно назвать очень прогрессивным. С отдельными новинками вроде операторов !<>= или ключевого слова cast можно поспорить, но в целом чувствуется, что все эти улучшения не «высосаны из пальца», а на самом деле нужны профессиональным программистам — авторы предназначают свое детище для них, а не для изучающих программирование. Однако писать на нем вполне удобно: не нужно постоянно метаться между объявлением и реализацией, проще вылавливать ошибки, нет необходимости в методах Get / Set. Наглядные операции со строками, сортировка, битовые, динамические и ассоциативные массивы, тип комплексных чисел встроены в язык D. Теоретически, это может улучшить оптимизацию (например, компилятор может попытаться избежать повторного копирования строки, что невозможно при использовании функции из стандартной библиотеки).
Но такое решение в чем-то ограничивает программиста. Язык стал более высокоуровневым, более близким к Pascal или Basic. Впрочем, это общая тенденция «продолжателей» C++ — вспомним Java или C#. Однако, в отличие от них, D — это полностью компилируемый язык, не использующий ни байт-кода, ни run-time-компонентов. Консольное «Hello, World» на D занимает 64 Кб, приблизительно столько же занимает примитивное приложение в окне.
Компилятор языка D распространяется бесплатно, предлагается также купить компакт-диск с дополнительными утилитами и примерами кода. Есть версии компилятора под Windows и Linux. Часть исходных текстов открыта для просмотра и изменений; в будущем автор планирует создать open source-версию D. Дизассемблирование программ на D показало, что оптимизация у него, откровенно говоря, слабовата. Впрочем, было бы странно ожидать большего, когда авторы все еще дорабатывают этот язык программирования. Для D пока не создано полноценной среды разработки с отладчиком и редактором ресурсов. Вы можете скачать лишь порт Micro Emacs на D под консоль Win32, DOS или Linux. На том же сайте можно найти компилятор Digital Mars C/C++. По степени оптимизации он аналогичен D (который был построен на его основе).
Сайт:
http://www.freepascal.org/down-win32.html
Скачать:
ftp://ftp.freepascal.org/pub/fpc/dist/Win32/w32106full.zip (полная версия, 18.5 Мб)
На указанной выше странице можно скачать отдельные компоненты (базовая версия с примерами программ и средой разработки весит около 4 Мб).
Free Pascal — это распространяемый под лицензией GPL компилятор. Компилятор реализован на платформах Windows, DOS, OS/2, Linux и Palm OS. По сравнению с традиционным языком Pascal, добавлены следующие расширения:
Система компоновки та же, что и в Pascal: существуют отдельные модули и главная программа. Если исходный текст модуля не был изменен с момента последней компиляции, он не будет компилироваться заново. Модули, как обычно, включаются предложением Uses. Нельзя не отметить, что такой подход гораздо удобнее заголовочных файлов и библиотек, принятых в C/С++.
Компилятор работает довольно быстро.
Заявлено три режима оптимизации — слабый, сильный и очень сильный, как в GCC (-O1, -O2 и -O3), кроме того, возможен выбор между оптимизацией по размеру и по скорости выполнения кода. Путем экспериментов удалось выяснить, что Free Pascal успешно переносит часто используемые переменные в регистры, оптимизирует умножения на степени двойки и на 3, 5, 9, 17, выполняет ряд других несложных преобразований. Самое смешное, что не оптимизируется присваивание вида x := 0. Вместо XOR компилятор использует медленную и длинную инструкцию MOV. Минимальная программа под Windows (с использованием Win32 API) занимает 16 Кбайт, консольное Windows-приложение — 14 Кбайт. Для запуска откомпилированных программ не требуется никаких дополнительных DLL.
Набор стандартных модулей включает в себя графические модули Graph, Win32Graph, модули ввода/вывода Crt и WinCrt, модуль DOS для файловых операций, Windows для использования Win32 API. Дополнительные модули: FCL (проект замены библиотеки VCL из Delphi, не путать с Framework Class Library), модули для работы с базами данных Interbase, MySQL и PostgreSQL, для использования OpenGL, для работы с архивами и регулярными выражениями. Примеры к графической библиотеке включают в себя игры «Тетрис», «Лабиринт», программу, выводящую фрактал Мандельброта и т.п. Благодаря кроссплатформенным модулям, все эти программы могут быть откомпилированы под DOS, Windows и Linux с минимальными изменениями в исходном коде.
Среда разработки, внешне очень похожая на Turbo Pascal, работает в текстовом режиме, но является Windows-приложением (как Far). Пока что IDE находится в стадии бета-тестирования (у меня не работала клавиша Delete, а текст сохранялся в кодировке DOS). Но разработчики уже успели реализовать подсветку синтаксиса, шаблоны для нового проекта, поиск-замену, диалоговые окна для настройки многочисленных параметров компилятора, а также встроенный калькулятор и таблицу символов. Ничуть не хуже, чем в Dev-C++, хотя и несколько медленнее, работает отладка Windows-приложений (также реализована через отладчик GNU Debugger). Вместе с Free Pascal поставляется компилятор rc-файлов, но визуального редактора ресурсов, к сожалению, не предусмотрено.
Free Pascal хорошо подходит для обучения программированию и для написания несложных программ, которые могут работать под разными ОС. В качестве языка для обучения Free Pascal вполне может заменить Turbo Pascal, тем более что он позволяет создавать полноценные графические приложения для Windows без помощи Win32 API — достаточно использовать модуль WinGraph, который почти ничем не отличается от модуля Graph из Турбо Паскаля.
В итоговой таблице указаны те методы оптимизации, которые проводят компиляторы над вашими программами. Привожу фрагменты тестовых программ для Си (программы для Pascal аналогичны приведенным):
x *= 8; shl eax, 3 ; Сдвинуть на 3 разряда влево — так делают LCC32, D, MinGW,; MSVC++ (оптимизация по размеру), FreePascal и BCC lea ecx, DWORD PTR [eax*8] ; MSVC++ (оптимизация по скорости) add eax, eax; eax = x * 2 — Intel C++ Compiler add eax, eax; eax = x * 4 add eax, eax; eax = x * 8 |
Последние два варианта на современных процессорах работают быстрее, так как инструкции LEA и ADD могут выполняться параллельно с другими инструкциями на разных конвейерах процессора. Некоторые компиляторы умеют представлять умножение на 7 как умножение на 8, а затем вычитание сомножителя. Точно так же умножение x на пять представляется как x*4 + x, которое можно выполнить одной быстрой инструкцией LEA:
x *= 7;; компиляторы MinGW, MSVC++ lea ecx, DWORD PTR [eax*8] ; Умножить eax на восемь sub ecx, eax; Вычесть eax; компилятор Borland C++ mov edx, eax shl eax,3 ; Умножить eax на 8, вычесть edx. Слегка медленнее, чем LEA, sub eax,edx; так как SHL может выполняться только на U-конвейере; компиляторы LCC32, Free Pascal и D используют гораздо более медленный вариант: imul eax, 07 x *= 5;; компиляторы MinGW, MSVC++, LCC, Borland C++ lea eax, DWORD PTR [eax*4 + eax] ; Быстрый способ умножить eax на 5; компиляторы D и Free Pascal imul eax, 05 ; Обычное умножение работает намного медленнее |
Деление на константу можно заменить умножением на обратную константу, которое выполняется слегка быстрее. Эту особенность учитывают компиляторы MinGW, MSVC++, LCC:
unsigned int x; // Для чисел со знаком требуется чуть x /= 3; // более сложный ассемблерный трюк mov eax, aaaaaaabH ;Записываем в edx число (2^33)/3 mul [ebp-4] ;Часть произведения x * (2^33/3), начиная с 32-го разряда,;будет записана в edx. В результате edx = (x / 3) * 2 shr edx, 1 ;edx = edx / 2 = x / 3 |
Из-за погрешности при переводе в двоичную систему счисления приходится сохранять один дополнительный разряд. Так, если бы мы умножили 3 на (2^32)/3, в EAX получили бы FF FF FF FF, а в EDX — ноль. Так как мы отбрасываем EAX, в результате деления на три получился бы ноль, а не единица. Поэтому приходится умножать на (2^33)/3, а затем делить на 2.
int x, y;
y = x + 5;
x = y * 2;
|
разные компиляторы компилируют такой код:
; MSVC++
mov edx, DWORD PTR [esp + 4] ; edx = x
lea eax, DWORD PTR [edx+5] ; eax = edx + 5
mov DWORD PTR [esp], eax; y = eax
lea ecx, DWORD PTR [eax+eax] ; ecx = eax * 2
mov DWORD PTR [esp + 4], ecx; x = ecx; MinGW
mov eax, DWORD PTR [ebp-08] ; eax = x
add eax, 05 ; eax = eax + 5
mov DWORD PTR [ebp-04], eax; y = eax
lea ecx, DWORD PTR [eax+eax] ; ecx = eax * 2
mov DWORD PTR [ebp-08], ecx; x = ecx; LCC
mov eax, DWORD PTR [ebp-04] ; eax = x
add eax, 5 ; eax = eax + 5
mov eax, DWORD PTR [ebp-08] ; y = eax
mov edi, eax
shl edi, 1 ; edi = edi * 2
mov DWORD PTR [ebp-04], edi; x = edi; BCC
mov ecx, DWORD PTR [esp] ; ecx = x
add ecx, 5 ; ecx = ecx + 5
mov DWORD PTR [esp+4], ecx; y = ecx
mov eax, DWORD PTR [esp+4] ; eax = y
add eax, eax; eax = eax * 2
mov DWORD PTR [esp], eax; x = eax; D
mov ebx, DWORD PTR [esp+10] ; ebx = x
add ebx, 5 ; ebx = ebx + 5
mov DWORD PTR [esp+14], ebx; y = ebx
add ebx, ebx; ebx = ebx * 2
mov DWORD PTR [esp+10], ebx; x = ebx; Free Pascal
mov eax, DWORD PTR [esp] ; eax = x
add eax, 5 ; eax = eax + 5
mov DWORD PTR [esp+4], eax; y = eax
shl eax, 1 ; eax = eax * 2
mov DWORD PTR [esp], eax; x = eax |
Компилятор от Microsoft почему-то решил сохранить значение регистра EDX (исходный x), записав инструкцию LEA вместо ADD. MinGW справился с этим заданием лучше. Он максимально использовал регистр EAX, благодаря чему созданный им машинный код на один байт короче (в реальной программе это может обернуться экономией в несколько килобайт). LCC сделал бесполезное копирование EAX в EDI (EAX в последующей программе не используется).
Компилятор D обошелся всего одним регистром, но почему-то EBX, а не EAX, инструкции с которым короче на байт. Практически идеально (как и MinGW) распределил регистры Free Pascal, но на более длинных программах этот компилятор показал себя не лучшим образом. Например, если написать после нашей программы writeln(x, y), компилятор будет сначала рассчитывать переменные x и y, записывать их в память, а затем считывать те же значения из памяти и передавать их процедуре writeln.
Borland C++ Compiler фактически не сделал никакой оптимизации: не воспользовался значением переменной y, записанной в ECX, и заново считал ее из памяти в EAX. На более длинных программах выяснилось, что BCC выносит в регистры только часто встречающиеся переменные. Иногда его стратегия работает успешно, но чаще другие компиляторы дают лучший код. Простой пример: программа для вычисления факториала.
int i, f=1;
scanf(“Число: %d”, &i);
for(; i>1; i--)
f *= i;
printf(«Факториал: %d», f);
|
lea esi, dwordptr [ebp-4] mov ebx, 1 ; EBX = f, ESI = &i push esi push offsetdd; строка «Число: %d» call scanf add esp, 8 cmp dwordptr [esi],1 ; если указано число <= 1, цикл не выполнится ни разу jle short L3 L2: ; начало цикла imul ebx, dwordptr [esi] ; ebx, то есть f, домножается на i при каждой итерации dec dwordptr [esi] ; i уменьшается cmp dwordptr [esi], 1 ; и сравнивается с единицей jg short L2 L3: push ebx push OFFSET de ; строка «Факториал: %d» call printf add esp, 8 |
Неясно, почему в регистр ESI была вынесена ссылка &i, а не переменная i, которая встречается намного чаще и даже является счетчиком цикла. Зато если исключить из программы &i, в регистр будет перенесена не только переменная f, но также i, что нам и требовалось. Эту ситуацию можно оценить как неустойчивую работу регистровой оптимизации (иногда работает нормально, иногда не работает вовсе):
int i, f=1; char s[200];
gets(s); // Избавляемся от &i, считывая строку функцией gets()
i = atoi(s); // и переводя ее в число с помощью atoifor(; i>1; i--)
f *= i;
printf(«Факториал: %d», f);
|
; ... (для краткости приведен только цикл)
cmp eax,1 ; EAX = i, EBX = f
jle short L3
L2:
imul ebx,eax
dec eax
cmp eax,1
jg short L2
L3:
|
В процессорах Pentium Pro и выше имеются 3 декодера D0, D1 и D2, которые разделяют машинные инструкции на элементарные микрооперации (после декодирования эти микрооперации могут выполняться параллельно на 5 многоступенчатых конвейерах). Декодер D0 может декодировать инструкции из любого числа микроопераций (от 1 до 4), а декодеры D1 и D2 — только из одной микрооперации. Поэтому инструкции должны быть упорядочены в соответствии с правилом 4-1-1 (сначала — инструкция из 2-4 микроопераций, затем две инструкции из одной микрооперации). Тогда все 3 инструкции будут декодированы за один такт.
Из одной микрооперации (1m) состоят команды типа «регистр-регистр», инструкции чтения из памяти и перехода, например, INC EAX; MOV EAX, EDX; AND EAX, 5; JGE label. Инструкции чтения-изменения и записи состоят из 2 микроопераций (2m), инструкции чтения-изменения-записи — из четырех (4m). К таким инструкциям относятся SUB EAX, [mem]; POP ECX; MOV EAX, [ESP+04]. Сложные команды (CALL, RET, команды длиннее 7 байтов, например, содержащие непосредственные операнды и смещение одновременно) декодируются за несколько тактов на D0, и декодирование других инструкций в это время приостанавливается. Аналогичный механизм в Pentium IV отличается от более ранних процессоров тем, что декодированные микрооперации кэшируются, и при повторном выполнении (например, в циклах) декодирование не требуется.
int x, y, z;
y--;
x++;
z+=3;
x+=y;
printf(“%d %d %d”, x, y, z);
|
; MinGW
;1-ый такт
mov ecx, dwordptr [ebp-04] ; 4m — декодер D0;2-ой такт
mov edx, dwordptr [ebp-08] ; 4m — декодер D0;3-ий такт
mov eax, dwordptr [ebp-12] ; 4m — декодер D0
add eсx, 03 ; 1m — декодер D1
dec edx; 1m — декодер D2;4-ый такт
push eсx ; 2m — декодер D0
inc eax; 1m — декодер D1;5-ый такт
push edx; 2m — декодер D0
add eax, edx; 1m — декодер D1;6-ой такт
push eax; 2m — декодер D0;7-ой такт
mov dwordptr [ebp-08], edx; 4m — декодер D0;8-ой такт
push OFFSET d_d_d ; 2m — декодер D0;9-ый такт
mov dwordptr [ebp-04], ecx; 4m — декодер D0;10-ый такт
mov dwordptr [ebp-12], eax; 4m — декодер D0;11-ый и 12-такты
call printf ; 6m — декодер D0 |
Из ассемблерного листинга видно, что MinGW свободно переставляет независимые инструкции, следуя правилу 4-1-1. На третьем такте было декодировано 3 команды, на четвертом и пятом — по 2 команды. Для этого MinGW вставил быстрые инструкции INC EAX и ADD EAX, EDX между тремя медленными PUSH.
Аналогично работает оптимизация под декодеры в MSVC++. Компиляторы BCC, LCC, Free Pascal и D не производят такой оптимизации и выполняют операции в том порядке, в котором они записаны.
char s[]=”abc xyz”, *p;
p = strchr(s, ‘ ‘);
printf(“%d %s”, p-s, s);
|
; LCC
push 32 ; пробел
push OFFSET s
call strchr
mov DWORD PTR[p], eax;Эта строка бесполезна, т.к. p в дальнейшем не используется
push OFFSET s ; Эта команда также бесполезна: адрес s уже находится в стеке
lea edx, OFFSET s
sub eax, edx
push eax; p-s
push d_s ; «%d %s»
call printf
add esp, 20 ; очищаем стек только один раз |
Компиляторы BCC и MinGW не используют этот прием, а Free Pascal и вовсе не может применить его, поскольку передает параметры в соответствии с соглашениями о вызовах Pascal. Ни один компилятор не смог «догадаться», что после вызова strchr адрес строки s все еще находится в стеке, и не нужно заталкивать его туда еще один раз, чтобы вызвать функцию printf.
Если функция не принимает параметров, сохранять EBP в начале функции и восстанавливать его по окончании не требуется. Все рассматриваемые компиляторы кроме Free Pascal знают об этом и избегают генерации ненужного кода.
float a, b, c, d;
scanf(“%f %f %f”, &a, &b, &c);
d = (b / (2*a)) * (b / (2*a)) - c / a;
if(d >= 0) // Дискриминант больше нуля
printf(“Корни: %f, %f\n”,
-b / (2*a) + sqrt(d),
-b / (2*a) - sqrt(d) );
else
printf( «Действительных корней нет\n» );
|
; LCC
fld dwordptr [ebp-04] ; Загрузить b
fstp dwordptr [ebp-14] ; Сохранить промежуточный результат в памяти
fld dwordptr [ebp-08] ; Загрузить a
fld dwordptr [00402064] ; Загрузить 2
fmul dwordptr [ebp-14] ; Умножить a на 2
fdivp st(1), st(0) ; Вычислить b/2a
fstp dwordptr [ebp-18] ; Сохранить этот промежуточный результат в памяти
fld dwordptr [ebp-18] ; Загрузить тот же результат [зачем?! есть же FLD st(0)]
fmul dwordptr [ebp-18] ; Умножить b/2a на b/2a
fld dwordptr [ebp-10] ; Загрузить c
fdiv dwordptr [ebp-14] ; Загрузить a
fsubp st(1), st(0) ; Вычесть (b/2a)^2-c/a
fstp dwordptr [ebp-0C] ; Сохранить в переменной
fldz
fcomp dwordptr [ebp-0C] ; Сравнить с нулем
fstsw ax
sahf
ja L124
fld dwordptr [ebp-0C] ; Снова загружаем переменную (совершенно бесполезный
sub esp, 08 ; шаг, так как она уже находится в st0)
fstp qwordptr [esp]
call sqrt ; Вызов sqrt из CRTDLL.DLL
mov dwordptr [ebp-1C], eax; Сохранение sqrt(d)
fld dwordptr [ebp-0C]
sub esp, 08
fstp qwordptr [esp] ; Сохранение d в памяти (ненужный шаг)
call sqrt ; Второй вызов sqrt из CRTDLL.DLL (также малополезный)
fld dwordptr [ebp-08] ; Повторное вычисление b/2a (CSE не сработало!)
fchs
fld dwordptr [00402064]
fmul dwordptr [ebp-04]
fdivp st(1), st(0)
push eax; Преобразование возвращенного функцией sqrt значения
fild dwordptr [esp] ; к вещественному типу
add esp, 04
fsubp st(1), st(0) ; Вычитание -b / (2*a) - sqrt(d)
sub esp, 08
fstp qwordptr [esp] ; Запись в стек для передачи printf
fld dwordptr [ebp-08] ; Третье вычисление b/2a (CSE не сработало!)
fchs
fld dwordptr [00402064]
fmul dwordptr [ebp-04]
fdivp st(1), st(0)
mov edi, dwordptr [ebp-1C]
push edi
fild dwordptr [esp]
add esp, 04
faddp st(1), st(0) ; Сложение -b / (2*a) + sqrt(d)
sub esp, 00000008
fstp qwordptr [esp] ; Запись в стек для передачи printf
push OFFSET roots ; строка «Корни: %d %d»
call printf
|
Выражение b / (2*a) встречается в этом примере четыре раза. Компилятор LCC весьма разумно счел, что в первой строке вычисления можно сократить, посчитав b / (2*a) только один раз. Но объединить эту строчку с последующими двумя он «не додумался». Кроме того, не были отпимизированы умножения на два, квадратный корень вычислялся с помощью библиотечной функции, для хранения промежуточных значений использовалась память, а не регистры математического сопроцессора. Другие компиляторы оказываются в этой ситуации более сообразительными.
; MinGW
fld DWORD PTR [ebp-20] ; Загрузить a
fld DWORD PTR [ebp-16] ; Загрузить b. После выполнения команды: st0=b, st1=a
fld st(1) ; Перенести a в st0. Регистры FPU: st0=a, st1=b, st2=a
fld st(1) ; Перенести b в st0. st0=b, st1=a, st2 = b, st3=a
fxch st(0), st(1) ; Обменять st0, st1. st0=a, st1=b, st2 = b, st3=a
fadd st(0), st(3) ; Сложить a и a. st0=2a, st1=b, st2 =b, st3=a
fld DWORD PTR [ebp-12] ; Загрузить c. st0=c, st1=2a, st2=b, st3=b, st4=a
fxch st(0), st(2) ; st0=b, st1=2a, st2=c, st3=b, st4=a
fdiv st(0),st(1) ; Разделить. st0=b/2a, st1=2a, st2=c, st3=b, st4=a
fxch st(0), st(2) ; st0=c, st1=2a, st2=b/2a, st3=b, st4=a
fdiv st(0), st(4) ; Разделить. st0=c/a, st1=2a, st2=b/2a, st3=b, st4=a
fxch st(0), st(2) ; st0=b/2a, st1=2a, st2=c/a, st3=b, st4=a
fmul st(0), st(0) ; Умножить. st0=(b/2a)^2, st1=2a, st2=c/a, st3=b, st4=a
fsubrp st(2), st(0) ; Вычесть и вытолкнуть. st0=2a, st1=(b/2a)^2-c/a, st2=b
fldz ; Загрузить нуль. st0=0, st1=2a, st2=(b/2a)^2-c/a, st3=b
fxch st(0), st(2) ; Обменять. st0=(b/2a)^2-c/a, st1=2a, st2=0 (бесполезно)
fucom st(2), st(0) ; Сравнить st0 и st2
fstsw ax
fstp st(2) ; Сохранить в st2 и вытолкнуть. st0=2a, st1=(b/2a)^2-c/a, st2=b
test ah, 1
jne L2 ; Перейти на ветвь «Действительных корней нет»
fld st(2) ; Прочитать из st2. st0=b, st1=2a, st2=(b/2a)^2-c/a
fchs ; st0=-b
sub esp, 12
fdivrp st(1), st(0) ; Разделить и вытолкнуть. st0=-b/2a, st1=(b/2a)^2-c/a
fstp QWORD PTR [ebp-32] ; Сохранить -b/2a в памяти и вытолкнуть из стека
fld st(0) ; Удвоить вершину стека: st0=st1=(b/2a)^2-c/a=d
fsqrt ; Извлечь квадратный корень
fucom st(0), st(0)
fnstsw ax
and ah, 69
cmp ah, 64
jne L8 ; Перейти на обработчик ошибки (если под корнем было отриц. число)
fsubr [ebp-32] ; st0=-b/2a–sqrt(d), st1=d, st2=b, st3=a
fxch st(0), st(3) ; st0=a, st1=d, st2=b, st3=-b/2a– sqrt(d)
sub esp, 8
fadd st(0), st(0) ; Снова начинаем вычислять b/2a (не сработало CSE!)
fxch st(0), st(2) ; st0=b, s1t=d, st2=2a, st3=-b/2a- sqrt(d)
fchs
fxch st(0), st(3) ; st0=-b/2a- sqrt(d), st1=d, st2=2a, st3=-b
fst QWORD PTR [ebp-32] ; Записать –b/2a- sqrt(d) в промежуточную переменную и
fstp QWORD PTR [esp] ; в стек для printf (непонятно, почему это не было; сделано сразу после подчета данного выражения)
fld st(0) ; Удвоить st0: st0=d, st1=d, st2=2a, st3=-b
fxch st(0), st(3) ; Обменять: st0=-b, st1=d, st2=2a, st3=d
fdivrp st(2), st(0) ; Разделить: st0=d, st1=-b/2a, st2=d
fxch st(0), st(2) ; Обменять: st0=d, st1=-b/2a, st2=d (бесполезно)
fsqrt ; Извлечь корень (второй раз!): st0=sqrt(d), st1=-b/2a, st2=d
fxch st(0), st(1) ; st0=-b/2a, st1=sqrt(d), st2=d
fstp QWORD PTR [ebp-40] ; Сохранить –b/2a в промежуточной переменной и вытолкнуть
fucom st(0), st(0) ; Проверить ошибку при вычислении sqrt(d)
fstsw ax
and ah, 69
cmp ah, 64
jne L9 ; Перейти на обработчик ошибки
fstp st(1) ; Сохранить в st1 и вытолкнуть (бесполезно): st0=sqrt(d)
fadd qwordptr [ebp-28] ; Сложить –b/2a + sqrt(d)
sub esp, 8
fst qwordptr [esp] ; Записать результат в стек...
pushl $LC2 ; строка «Корни %d %d»
fstp qwordptr [ebp-28] ; ...и в промежуточную переменную
call _printf
|
MinGW хранит почти все промежуточные значения в регистрах st(0)…st(7), вычисляет квадратный корень инструкцией fsqrt (право, совершенно не нужно вызывать для этого функцию из DLL, как это делает LCC). Но переменные загружаются в регистры FPU совершенно не в том порядке, в котором выполняются арифметические операции. MinGW слишком часто обменивает значения регистров инструкцией FXCH, и большинство этих обменов бесполезно. Ассемблерный код превращается в мешанину, разобраться в которой можно только отслеживая каждую перестановку регистров (см. комментарии к листингу). Программа станет короче и проще, если поменять порядок загрузки переменных в регистры. Кроме того, удаление повторяющихся подвыражений, которое так расхваливала RedHat на своем сайте, не сработало ни разу. Выражение b/2a вычислялось трижды, а корень из d — дважды.
Другие компиляторы выдали код примерно такого же качества. Компиляторы D, BCC и Free Pascal хотя и смогли избежать ненужных манипуляций с регистрами FPU, но четыре раза вычисляли одно и то же выражение b/2a и два раза извлекали корень, кроме того, ни один из этих компиляторов не заменил a * 2 на a + a. К тому же все они много раз загружали одни и те же значения переменных из памяти. Так что если вы пользуетесь этими компиляторами, то вам следует самостоятельно выносить повторяющиеся подвыражения в промежуточные переменные. Похоже, что оптимизация операций с плавающей точкой под силу только коммерческим монстрам вроде Intel C++ Compiler или MSVC:
; MSVC++
fld DWORD PTR [esp] ; Загрузить a
fadd ST(0), ST(0) ; st0 = a + a
fdivr DWORD PTR [esp+4] ; st0 = b / 2a
fld ST(0)
fld ST(0) ; Сохранить значение b / 2a в регистре FPU
fmulp ST(1), ST(0) ; st0 = (b / 2a)^2
fld DWORD PTR [esp+8]
fdiv DWORD PTR [esp] ; st0 = c / a
fsubp ST(1), ST(0) ; Провели вычитание и нашли d
fcom DWORD PTR __real@4@ ; Сравнение с нулем
fnstsw ax
test ah, 1
jne SHORT $L1204 ; Переход на ветвь «Действительных корней нет»
fsqrt
sub esp, 8
sub esp, 8
fld ST(1) ; Восстановили b / 2a
fchs ; st0 = -b / 2a
fsub ST(0), ST(1) ; -b/2a – sqrt(d)
fstp QWORD PTR [esp+8] ; Запись в стек для передачи printf
fxch ST(1)
fsubr ST(0), ST(1) ; sqrt(d) – b/2a
fstp QWORD PTR [esp] ; Запись в стек для передачи printf
push OFFSET roots ; строка «Корни: %d %d»
fstp ST(0)
call printf
|
Этот код практически идеален (почти такой же написал бы опытный ассемблерщик). Он почти в два раза короче, чем «продукция» остальных компиляторов, повторяющиеся выражения вычисляются только один раз, промежуточные значения сохраняются в регистрах FPU, используются короткие и быстрые формы команд. Единственный недостаток: константа ноль загружается из памяти (инструкция FCOM), а не с помощью FLDZ.
int a = 0;
a = 2 * 2 * (a + 0); // Должно быть заменено на a *= 4// или (лучше) удалено вообще, т.к. a = 0if(FALSE) // If должен быть исключен, так как условие всегда ложно
a++;
printf(“%d”, a);
|
В идеальном случае компилятор должен заменить весь этот код на эквивалентный ему printf(«%d», 0). Именно так сделали MSVC++, MinGW, LCC и D:
xor edi, edi; LCC push edi push _d ; строка “%d” call printf add esp, 8 |
Borland C++ не смог полностью прооптимизировать арифметические операции над нулевой переменной:
xor eax, eax; a = 0 shl eax, 2 ; a *= 4 jmp short @2 inc eax; a++ @2: push eax push offset s call _printf add esp, 8 |
Кроме того, BCC предупредил об «Unreachable code», но не убрал a++. А между тем многие программисты используют всегда ложные или всегда истинные условия для исключения отладочных команд:
#define DEBUG 0 // замените на 1 во время отладки
…
if (DEBUG)
printf(“x = %d”, x);
|
Почему не воспользоваться директивами препроцессора #ifdef / #endif? Потому что код, заключенный между ними, не проверяется на синтаксические ошибки, если условие ложно. Если редактировать и компилировать этот код при DEBUG равном 0, в готовую программу могут попасть ошибки. По этой причине многие предпочитают ложные условия. В случае с BCC придется отказаться от их использования.
Компилятор Free Pascal выдал такой «шедевр»:
xor eax, eax; a := 0 mov a, eax add eax, 0 ; a := a + 0 shl eax, 2 ; a := a * 4 mov a, eax; далее вызов функции writeln с аргументом a |
Впрочем, учитывая искусственность примера (никто в здравом уме не будет писать нечто вроде a + 0, разве что такой код мог быть сгенерирован препроцессором или транслятором с другого языка), этот недостаток компилятора вполне можно ему простить. Главное, что Free Pascal прооптимизировал конструкцию if false then, о которой я уже говорил, и 2 * 2 (арифметические выражения часто записывают вместо «магических чисел», чтобы повысить удобочитаемость кода).
switch (message)
{
case PSM_QUERYSIBLINGS: // PSM_QUERYSIBLINGS = 1132// ...case WM_INITDIALOG: // 272// ...case WM_NOTIFY: // 78// ...case WM_COMMAND: // 273
}
|
Проверять равенство переменной message константам в том порядке, в котором они записаны, нерационально. Сначала лучше проверить среднюю по величине константу (272=WM_INITDIALOG). Если message меньше 272, проверять 273 и 1132 бесполезно — нужно лишь проверить число 78. Если же message больше 272, проверим числа 273 и 1132.
;MinGW
cmp DWORD PTR [ebp-36], 272
je L7 ; если равно 272, переходим к соотв. ветви
cmp DWORD PTR [ebp-36], 272
ja L51 ; если больше 272, проверяем 273 и 1132
cmp DWORD PTR [ebp-36], 78
je L15 ; если равно 78, переходим к соотв. ветви
jmp L2 ; ни одно из условий не сработало - выходим
L51:
cmp DWORD PTR [ebp-36], 273
je L19 ; если равно 273, переходим к соотв. ветви
cmp DWORD PTR [ebp-36], 1132
je short L3 ; если равно 1132, переходим к соотв. ветви
jmp L2 ; выходим
L3:
|
Единственная ошибка компилятора здесь в том, что третья строка совершенно бесполезна, и ее следует исключить (инструкция je не меняет флаги, установленные cmp). Да и переменную message следовало бы вынести в регистр. Если число констант больше, компилятор может добавить еще несколько проверок, и все они образуют сбалансированное дерево, корень которого — это средний по величине элемент.
Другой часто встречающийся случай — последовательные значения констант в case (например, 1, 2, 3, 4 и 5). В этом случае хороший компилятор создаст таблицу переходов, в которой записаны адреса ветвей, и выполнит косвенный переход по элементу этой таблицы. Оба эти метода (сбалансированное дерево и таблица переходов) успешно используются компиляторами MinGW, LCC и MSVC в режиме оптимизации по скорости. Компиляторы D, Free Pascal и BCC «умеют» только создавать таблицу переходов.
Однако Free Pascal и BCC, а также MSVC в режиме оптимизации по размеру, применяют другой метод. Они проверяют значения, начиная с наименьшего, и вычитают сначала первое значение, затем разницу между первым и вторым, затем между вторым и третим и так далее. Так как разность между числами меньше, чем сами эти числа, инструкции SUB будут занимать меньше байтов, но число проверок останется прежним. Этот метод уменьшает размер кода, но не делает его быстрее:
; BCC
mov edx,dwordptr [ebp-4]
sub edx,78
je @7 ; message = 78, переходим к нужной ветви
sub edx,194
je @6 ; message = 194+78=272, переходим к нужной ветви
dec edx
je @5 ; message = 194+78+1=273
sub edx,859
jne @2 ; если message не равно 1132, то выходим из case-блока |
if (x > 0)
SendMessage(hRTF, EM_GETSEL, (LPARAM)&x, (WPARAM)&y);
else
SendMessage(hRTF, EM_GETSEL, (LPARAM)&y, (WPARAM)&x);
|
Первые два аргумента повторяются, причем исключить повтор средствами языка невозможно. Если мы напишем
SendMessage(hRTF, EM_GETSEL, x > 0 ? (LPARAM)&x : (LPARAM)&y,
x > 0 ? (WPARAM)&y : (LPARAM)&x);
|
то опять получим повтор, но уже не аргументов, а условий. Оптимизирующий компилятор должен решать эту задачу за нас, «вынося за условие» инструкции PUSH для первых двух аргументов:
mov eax, [ebp-12] ; eax = x, ebx = &x lea ebx, [ebp-12] test eax, eax jle L3 ; Если x <= 0, перейти на L3 lea edx, [ebp-16] ; edx = &y push edx; Передать аргументы: &x, &y push ebx L5: push 176 ; Общие для обоих случаев аргументы hRTF, EM_GETSEL push esi call SendMessageA ; Вызываем функцию lea esp, [ebp-8] ; Эпилог функции — восстанавливаем стек pop ebx xor eax, eax pop esi pop ebp ret ; Выход из функции L3: push ebx; Передать аргументы: &y, &x lea edx, [ebp-16] ; edx = &y (к сожалению, MinGW не вынес эту инструкцию) push edx jmp L5 |
Из шести рассматриваемых компиляторов такой метод оптимизации применяют только MSVC и MinGW.
var x, y, i: integer;
a: array [1..10] of integer;
begin
readln(x, y); {Иначе x и y могут быть оптимизированы как константы}for i:= 1 to 10 do
a[i]:= (x + y) * i;
// Аналогичный пример на C
int x, y, i, a[10];
for(i=0; i < x; ++i)
a[i] = (x + y) * i;
|
mov edi, DWORD PTR [ebp-92] ; сохранить x — число итераций цикла mov DWORD PTR [ebp-144], edi mov ebx, 01 ; i = 1 (eax — это i) cmp ebx, DWORD PTR [ebp-144] ; если i > x, выйти jg @@27 @@28: ; начало цикла mov eax, ebx mov edx, DWORD PTR [ebp-92] ; edx = x add edx, DWORD PTR [ebp-96] ; edx += y imul edx, ebx; edx *= i mov DWORD PTR [ebp+eax*4-144],edx; записать edx в текущий эл-т массива cmp eax, DWORD PTR [ebp-144] ; сравнить i и x jge @@27 ; если i > x, выйти inc ebx jmp @@28 @@27: |
Заметны мелкие огрехи регистровой оптимизации: Free Pascal не использовал регистр ecx, а в ebx сохранил то же значение, что и в eax. Но главное, что (x+ y) не было вынесено из цикла, а умножение не было заменено сложением. Кроме того, очень неудачно записано условие цикла: один условный переход и два безусловных повторяются при каждой итерации. А требовалось всего лишь завести третью регистровую переменную, которая при каждой итерации увеличивалась бы на x + y. Для сравнения приведу код, выданный MinGW:
mov ecx, dwordptr [ebp-40] ; ecx = x xor edx, edx; edx = i = 0 cmp edx, ecx; i < x - ? jge E1 ; нет — выходим mov ebx, ecx; ebx = x xor eax, eax; обнулить eax add ebx, dwordptr [ebp-3C] ; ebx += y D6: ; начало цикла mov dwordptr [ebp+4*edx-38], eax; записать eax в массив inc edx; увеличить i на единицу add eax, ebx; увеличить eax на ebx (т.е., на x + y) cmp edx, ecx; если i < x, продолжаем jl D6 E1: |
Этот код также не лишен недостатков, но работает он намного быстрее, чем предыдущий. Цикл стал короче, так как из него было выброшено все лишнее. Наиболее качественный код для этого примера генерируют, конечно же, коммерческие компиляторы Intel C++ и Microsoft Visual C++. Они создают указатель на текущий элемент массива и при каждом проходе цикла сдвигают его вперед на 4 байта (размер переменной int), благодаря чему удается избавиться от сложной и медленной инструкции mov dword ptr [ebp+4*edx-38], eax.
Замена предусловия постусловием — это самое большее, на что способны такие компиляторы, как LCC, BCC, D и Free Pascal. При их использовании высокоуровневая оптимизация — вычисление инвариантов вне цикла, преобразование индексов в указатели, запись цикла «задом наперед» (счетчик изменяется от большего значения к меньшему) — целиком ложится на плечи программиста. Например, наш пример можно бы было переписать так:
int x, y, i, *p, a[10];
scanf(“%d %d”, &x, &y);
x += y; // x = x + y (шаг увеличения y)
y = 0; // y — текущее значение числа, заносимого в массивfor(i = 9, p = &a[0]; i >= 0; --i, y += x, p++)
*p = y;
|
Любой компилятор сгенерирует для этого цикла почти идеальный код. Другое дело, что писать подобные программы непросто, они плохо переносятся, да и об удобочитаемости в данном случае говорить не приходится.
| LCC | MinGW | D | Free Pascal | Borland C++ | VC++ | |
|---|---|---|---|---|---|---|
| Быстрые умножения | + | ++ | + | + | + | ++ |
| Использование регистров | + | + | + | + | +– | + |
| Оптимизация под декодеры | – | + | – | – | – | + |
| Оптимизация вызовов функций | + | – | + | N/A | – | + |
| Оптимизация инструкций FPU | – | – | – | – | – | + |
| Удаление «мертвого» кода | + | + | + | – | – | + |
| Удаление повторяющихся выражений | + | ++ | – | – | – | ++ |
| Оптимизация case | + | + | – | + | + | ++ |
| Оптимизация условий | – | + | – | – | – | + |
| Оптимизация циклов | – | + | – | – | – | ++ |
Все компиляторы тестировались при включенном режиме наилучшей оптимизации. Для сравнения в таблице приведены методы оптимизации Microsoft Visual C++. Знак плюс указывает на наличие возможности, два плюса — на полную или улучшенную ее реализацию.
http://www.optim.su/cs/2001/3/compar/compar.asp — «Кто сегодня самый шустрый?» — сравнение компиляторов Intel C++, VC++, Delphi, Java, C#, Visual Basic.
http://bloodshed.net/compilers/index.html, http://www.devzoo.com/editor_win.php — Списки бесплатных компиляторов и редакторов кода.
http://www.winprog.org/tutorial/msvc.html — как бесплатно скачать и установить Microsoft Visual C++, а также Platform SDK (требуется выкачать с сайта Microsoft несколько сотен мегабайт).
http://www.avhohlov.narod.ru/ — Сайт о программировании компиляторов. Автор предлагает компилятор собственного языка Context — нечто среднее между Си и Паскалем. Есть версии под DOS и под Windows. Компилятор генерирует ассемблерный листинг, который затем нужно пропустить через Turbo Assembler.
http://fpc.by.ru/ — русский сайт о Free Pascal. Информация об языке, отладчике, режимах компиляции, первые главы книги о программировании в Win32 на Free Pascal (автор обещает выкладывать следующие главы по мере их написания), примеры программ и форум.
http://www.gnu-pascal.de — многоплатформенный компилятор GNU Pascal, прямой конкурент Free Pascal. Представляет собой адаптацию компилятора GCC для языка Pascal. Для компиляции под Win32 требуется скачать исходные тексты, компилятор GCC, MinGW или Gygwin (в общей сложности не менее 8 Мб). Готовых исполнимых файлов для Win32, а тем более среды разработки, нет. В отличие от Free Pascal, распространяемого с исходниками на Free Pascal, этот компилятор распространяется с исходниками на C.
http://www.xbasic.org — многоплатформенный компилятор X-Basic. Язык основан на Basic, но значительно переработан: добавлены указатели, битовые операции, массивы с элементами произвольного типа. Есть средства для создания GUI, функции для работы с файлами, датой. Оптимизация кода полностью отсутствует, и вместе с откомпилированной программой нужно поставлять DLL размером 1,5 Мб. Среда разработки и компилятор работают крайне нестабильно. Однако, X-Basic — это единственный бесплатный компилятор Бэйсика в машинный код для Win32.
http://www.rowan.sensation.net.au/moonrock.html — интересный компилятор Бэйсика, но, к сожалению, для DOS. Как и в X-Basic, язык слегка видоизменен, расширен новыми полезными командами (условная компиляция, логические сдвиги, работа со стеком, портами, выделение памяти, хэширование и даже вычисление CRC). Прилагается полтора десятка примеров. Компилирует в ассемблерный листинг (бесплатный ассемблер прилагается).
http://www.powerbasic.com — коммерческий компилятор Basic ($200). Судя по описанию, это нечто революционное (и на других сайтах о Power Basic отзываются неплохо). Но скачать можно только версию под DOS.
http://www.libertybasic.com — интерпретатор Basic под Windows (Shareware, $40). Позволяет создавать окна (но без помощи визуального редактора форм), писать довольно сложные программы. Есть возможность компилировать вашу программу в p-код и распространять ее вместе с run-time размером около мегабайта.
http://www.rapideuphoria.com — интерпретатор Basic-подобного языка под DOS, Windows и Linux. Очень прост, хорошо подходит для обучения программированию, однако вызывать функции Win32 крайне сложно и неудобно. Базовая версия бесплатна, продаются исходные тексты за $50.
| Оценка 541
[+1/-1]
Оценить
|