 Оценка 1285
[+1/-0]
Оценка 1285
[+1/-0]

 Оценить
Оценить 





| Оценка 1285
[+1/-0]
Оценить
|
| ПРИМЕЧАНИЕ Утилиты CLR Profiler и WinDbg приведены на CD ROM. |
Производительность .NET-приложений зависит от множества факторов. Немалое влияние на производительность оказывают качество оптимизации JIT-компилятора, объектная ориентация .NET и сборщик мусора. Однако я уверен, что с ростом интеллектуальности CLR первые два фактора будут влиять на производительность все меньше и меньше. Даже такой «гандикап» управляемых сред, как проверки выхода за пределы массива и частое использование косвенных вызовов (виртуальных методов, методов интерфейсов) рано или поздно будут устраняться JIT- и пре-JIT-компиляторами. Знание же об используемом процессоре и других аспектах системы позволит управляемым средам порождать даже более быстрый код, нежели код, созданный оптимизирующими не типобезопасных native-компиляторами (вроде C/C++), так как те вынуждены генерировать код в расчете на обобщенный набор инструкций (вроде набора инструкций Pentium) и не имеют информации о таких аспектах системы, как объем оперативной памяти и размер кэша.
Если же говорить о сборщике мусора, то тут картина не столь радужна. Конечно, алгоритмы сборки мусора тоже постоянно совершенствуются, но рассчитывать на то, что их влияние сведется к нулю, все же пока не приходится. Единственное, что может радикально изменить положение с управлением памятью в управляемых средах – это введение оптимизации, позволяющей компилятору размещать некоторые локальные объекты (на которые нет внешних ссылок) в стеке приложения. И, хотя такие работы уже ведутся в проекте Java 1.6, разрабатываемом Sun Microsystems, нам с вами в ближайшие несколько лет вряд ли придется использовать сборщик мусора, не оказывающий ощутимого влияния на скорость управляемых приложений. Поэтому при создании эффективных управляемых приложений нужно четко понимать, во что обходится услуги сборщика мусора, когда и в чем проявляются его слабые и сильные стороны, и что нужно делать, чтобы увеличить эффективность сборщика.
Понимание устройства сборщика мусора (Garbage Collector, GC) в Microsoft .NET позволяет избавиться от большого количества фобий и предрассудков, что, в свою очередь, позволяет более продуктивно использовать .NET.
На сегодняшний день разработан целый ряд алгоритмов сборки мусора, каждый из который имеет свои достоинства и недостатки. Учитывая то, что эти алгоритмы могут комбинироваться, общее количество вариаций GC довольно велико.
В статье Игоря Ткачева Автоматическое управление памятью в .NET уже поднималась тема сборщика мусора в .NET. Однако эта статья является введением в мир GC. Подробнее о работе GC можно прочесть в книге Джефри Рихтера (Jeffrey Richter) «Applied Microsoft .NET Framework Programming» или в статье «Garbage Collection: Automatic Memory Management in the Microsoft .NET Framework», вышедшей в двух частях в журнале MSDN Magazine. Книга, по сути, содержит в себе эту статью. Однако и с этими статьями не все замечательно. Во-первых, они не дают полной информации о работе GC, проблемах, с ним связанных, и вопросах оптимизации использования памяти в управляемых приложениях. А во-вторых, эти статьи не доступны в Интернете на русском языке. Перевод же книги Рихтера на русский язык оставляет желать лучшего. Более полную информацию о GC можно найти в разных блогах, но, к сожалению, это отнюдь не простая задача. Ну и конечно же, вся эта информация имеется только на английском. Данная статья является попыткой собрать воедино всю публично доступную информацию о GC. Надеюсь, эта попытка увенчается успехом.
В основе алгоритма, используемого в .NET CLR, лежит алгоритм «mark, sweep and compacting» (пометить, подмести и уплотнить).
Выделение памяти под управляемые объекты производится в управляемых кучах (managed heap).
Для каждого процесса создается две кучи. Куча для маленьких объектов (Small Objects Heap) и куча для больших объектов (Large Objects Heap, LOH). В первой куче размещаются небольшие объекты, во второй – большие, то есть те, что имеют размер, превышающий 85 000 байт. Так как среднестатистическое объектно-ориентированное приложение в основном манипулирует маленькими объектами, то куча, предназначенная для маленьких объектов, обычно называется «обычной» или «основной». Когда речь заходит о куче, предназначенной для размещения больших объектов, то обычно для ее идентификации применяют аббревиатуру – LOH.
Управление обычной кучей и LOH производится совершенно различным образом. В отличие от обычной кучи, в LOH не производится уплотнение объектов. Вместо этого в ней используется подход сходный с тем, что используется в кучах C/C++ или ОС.
Упрощенно процесс выделения памяти под объекты в обычной куче GC можно описать так. Имеется указатель alloc_ptr, отделяющий используемую часть кучи от части содержащей свободное пространство. Конец свободного пространства описан неким другим указателем, alloc_limit. При выделении памяти под новый объект к alloc_ptr прибавляется размер объекта, память под который нужно занять. Полученная величина сравнивается с alloc_limit. Если она меньше или равна alloc_limit, производится инициализация нового объекта (размечаются внутренние структуры, вслед за чем вызывается конструктор объекта), значение alloc_ptr возвращается коду, запросившему создание объекта, а рассчитанное значение помещается в alloc_ptr (тем самым уменьшая объем свободной памяти).
Когда свободная память исчерпывается, запускается процесс сборки мусора. Он состоит из двух шагов. На первом шаге вычисляется граф живых объектов. На втором живые объекты сдвигаются таким образом, чтобы они лежали последовательно друг за другом. Другими словами, производится уплотнение кучи. Это позволяет избежать фрагментации кучи. В результате этой операции ссылки на перемещенные объекты становятся некорректными. Чтобы избавиться от этой неприятности, производится процедура коррекции ссылок, и все ссылки начинают указывать на участки кучи, в которые перемещены объекты.
В LOH уплотнение не производится. Вместо этого LOH управляется алгоритмами, сходными с теми, что используются в С/C++-куче и куче ОС, то есть на основе связанных списков свободных блоков. Свободные блоки объединяются и затем используются для повторного выделения.
Какие же выводы можно сделать на базе вышесказанного?
Скорость выделения памяти под объекты в GC .NET очень высока. Это достигается:
Мертвым объектом считается объект, на который нет ссылок. Обратите внимание на эту мысль. Очень часто непонимание этого приводит к неверному пониманию принципов работы GC и/или к неверной оценке скоростных характеристик GC. Дело в том, что мертвые объекты ничего не стоят. Случай, когда при сборке мусора все объекты являются мертвыми, является идеальным случаем!
Представьте, что .NET работает на машине с гигабайтами оперативной памяти.
| ПРИМЕЧАНИЕ Это, кстати, еще не самый худший случай. Ведь 64-битные компьютеры и ОС уже доступны широким массам. А они позволяют иметь неприлично очень много памяти. |
Выделение памяти никак не зависит от объема уже занятой памяти, количества размещенных объектов и т.п. Но скорость сборки мусора очень даже зависит и от объема занятой памяти, и, особенно, от количества живых объектов. В больших приложениях граф объектов может оказаться настолько большим, что скорость сборки мусора окажется заметной. Это отразится в работе приложения в виде пауз. На Web-серверах в Интернете, где и так достаточно причин для пауз, пользователь может не обратить внимания на секундную паузу, или просто не придать ей должного внимания. В пакетных задачах, не завязанных на железо, это тоже не критично. Но в интерактивных приложениях это может оказаться неприемлемым.
Исследованиями в области алгоритмов GC занимается очень много народу. Тут и отдельные пытливые самоучки, и целые кафедры институтов, и даже огромные корпорации вроде IBM, Microsoft и Sun. Так что не мудрено, что в вопросах оптимизации этих алгоритмов есть немало наработок.
Итак, что же можно придумать для ускорения процесса сборки мусора?
Эта оптимизация предполагает, что на многопроцессорной машине собирать мусор можно, используя сразу несколько процессоров. Чем больше процессоров, тем больше скорость сборки мусора. Однако если куча одна, то доступ к ее структуре придется синхронизировать. А это может свести на нет все преимущества распараллеливания. Чтобы этого избежать, можно завести по отдельной куче на каждый процессор. Тогда и выделение памяти, и сборку мусора можно будет производить полностью параллельно. Именно это и делается в так называемом серверном GC .NET. Его можно использовать только на многопроцессорных машинах. Причем, ко всему прочему, исполняющую систему (далее EE, от Execution Engine) .NET придется долго уговаривать использовать этот тип GC. В .NET Framework 1.0 и 1.1 до SP1 подобные уговоры можно было осуществить только через API хостинга .NET, т.е. запуская CLR программно посредством COM. В .NET Framework 2.0 и 1.1 с SP1 появился еще один вид уговоров – XML-уговоры. В этих версиях тип требуемого GC можно описать в конфигурационном файле приложения. Сделать это можно следующим образом:
<configuration>
<runtime>
<gcServer enabled="true"/>
</runtime>
</configuration>
|
Проверить, включен ли серверный GC, можно, обратившись к статическому свойству System.Runtime.GCSettings.IsServerGC (доступному только в .NET Framework 2.0).
Однако любое количество процессоров не страхует от пауз при сборке мусора, ведь при сборке мусора все равно производится полная остановка всех управляемых потоков. К тому же преимущества серверного GC можно ощутить, только если у вас имеется компьютер с более чем двумя процессорами (что на практике означает с четырьмя и более).
Concurent GC – это второй вид оптимизации процесса сборки мусора. Его суть заключается в том, что процесс построения графа объектов ведется без приостановки управляемых потоков. Вместо этого запускается специальный GC-поток, строящий граф. Поскольку в любой момент управляемые потоки могут изменить граф и вообще пересечься с GC-потоком, требуется синхронизация со всеми операциями, модифицирующими управляемые ссылки. Естественно, что параллельный GC-поток и необходимость синхронизации (подробнее см. раздел «Барьер записи») не могут не замедлить процесс сборки мусора по сравнению с обычной схемой. Однако во многих случаях такое замедление незаметно. Зато это позволяет избавиться от паузы, вызванной построением графа объектов. Малый размер пауз выгоден для интерактивных приложений. Особенно в нем нуждаются GUI-приложения и игры. Не мудрено, что именно этот режим используется в .NET Framework по умолчанию. Отключить его можно, как и серверный GC, через конфигурационный файл (для .NET Framework 2.0, 1.1 с SP1):
<configuration>
<runtime>
<gcConcurrent enabled="false"/>
</runtime>
</configuration>
|
или через COM API хостинга.
Concurrent GC позволяет избежать пауз при сборке мусора, но не позволяет избежать непроизводительных затрат времени, так как снова и снова перебирает весь граф объектов. Как показали многочисленные исследования и наблюдения, объекты делятся на два больших класса: долгожителей и проживающих относительно короткую жизнь (временных объектов).
Причем племя долгожителей обычно значительно меньше, чем племя временных объектов.
Как я уже говорил ранее, сборка мусора делится на две стадии: построение графа живых объектов и уплотнение кучи. Если принять во внимание, что большинство объектов – временные, умирающие еще до сборки мусора, то частое уплотнение кучи не является проблемой. Ведь все старые объекты уже уплотнены, а новые в основном вымерли. Однако стадия построения графа будет включать в себя вычисление графа для всех, в том числе и старых, объектов. Да и рано или поздно некоторые старые объекты могут умереть, и придется из-за пары-другой объектов передвигать довольно много старых объектов (чтобы уплотнить кучу).
А что если попытаться отделить новые объекты (ведь именно среди них смертность так велика) от старых? Именно эта идея и привела к разработке сборщика мусора, основанного на поколениях.
GC .NET поддерживает три поколения 0, 1 и 2. Поколения 0 и 1 считаются эфемерными. Рождаясь, объекты попадаются в нулевое поколение. Большая их часть помирает, не дождавшись первой сборки мусора. Те из них, кто переживает первую в своей жизни сборку мусора, попадают в первое поколение. Первое поколение – это своего рода отстойник. Оно позволяет отфильтровать объекты, которые не успели умереть к моменту сборки мусора по чистой случайности. Второе поколение – это, можно сказать, дом престарелых. В нем доживают свой немалый век долгожители.
Чаще всего мусор собирается в нулевом поколении. В приложениях, не имеющих комплексов по поводу создания большого количества объектов, она может производиться по нескольку раз в секунду или раз в несколько секунд.
Сборка мусора первого поколения производится значительно реже. Обычно это происходит раз в несколько минут. В худшем случае – раз в несколько секунд.
Сборка мусора во втором поколении происходит крайне редко. И это не мудрено, так как именно сборка этого поколения является самой дорогой. Кстати, оптимизации вроде Concurent GC, описанной выше, имеют смысл только при сборке второго поколения. Сборка нулевого и первого поколения настолько быстры, что подобного рода оптимизации способны скорее затормозить GC, нежели ускорить.
Поколения располагаются друг за другом. Сначала идет второе поколение. За ним первое, а за ним нулевое. С каждой сборкой мусора (если, конечно, не складывается ситуация, когда все объекты эфемерных поколений умерли) объекты младших поколений продвигаются в следующее (более старое) поколение. Это приводит к сдвижке указателей на начало поколения вперед и вперед.
Объем памяти, отводимый под поколения, варьируется. Размер нулевого поколения обычно подбирается в зависимости от размеров кэша процессора, но может изменяться в зависимости от собранной в ходе работы GC статистики. По словам Рихтера, при инициализации EE для поколений устанавливаются значения, приведенные в таблице 1.
| Поколение | Размер (по-умолчанию) |
|---|---|
| 0 | 256 Кб. |
| 1 | 2 Мб. |
| 2 | 10 Мб. |
Однако, похоже, что эти цифры не очень точны, или что CLR очень быстро подстраивает размеры поколений под профиль приложения. Я не раз наблюдал картину, когда нулевое поколение увеличивалось до нескольких мегабайт, а первое поколение оставалось в пределах сотни килобайт. Зато 10 МВ для второго поколения, похоже, реальная цифра.
На что же влияют размеры поколений? В первую очередь на частоту сборки мусора и на то, сборка каких поколений будет производиться.
Есть три причины, вызывающих запуск процесса сборки мусора:
Самой частой причиной является пункт 1. Пункт 3 обычно является большой редкостью. Ну а пункт 2 зависит от программиста, но обычно тоже крайне редок. Однако в Windows-приложениях пункт 2 может быть инициирован подсистемой учета ресурсов ОС (хендлов).
Пункт 3 приводит к сборке мусора второго поколения. GC.Collect() позволяет указать, какое поколение необходимо «подмести». А вот пункт 1 заставляет GC задуматься. Ход его мыслей приблизительно следующий: «Ага! Надо проверить лимит второго поколения. Если он превышен, то собрать его. Если нет, то проверить лимит первого поколения. Если он превышен, то собрать первое поколение. Иначе собрать только нулевое поколение».
При сборке мусора в старших поколениях в обязательном порядке убирается мусор и во всех младших. Так, при сборке мусора во втором поколении убирается мусор также в нулевом и первом поколениях. А вот сборка мусора нулевого поколения никакие другие поколения не затрагивает.
Теперь вы знаете кое-что о GC, но для полного понимания принципов работы GC вам придется узнать еще немало. Следующее по списку, о чем следует рассказать – это о том, как же занимается физическая память под GC-кучу?
Память, точнее, адресное пространство под управляемую кучу, занимается с помощью функции VirtualAlloc. Выделение адресного пространства производится сегментами. Размер сегмента равен 16 мегабайтам (иногда больше).
Когда инициализируется исполняющая система (Execution Engine, EE) производится занятие двух сегментов – одного для обычной кучи и одного для LOH.
Физическая память запрашивается у системы и отдается системе по мере необходимости. При инициализации ЕЕ обычно у системы занимается около 7 мегабайт физической памяти.
Куча может состоять из одного эфемерного сегмента, который содержит нулевое и первое поколения, и возможно, часть второго, а также нескольких сегментов второго поколения. Сегментов второго поколения может и не быть (именно так и обстоит дело в самом начале работы приложения).
После сборки мусора, если адресного пространства в эфемерном сегменте становится недостаточно для размещения нулевого и первого поколений, EE занимает очередной сегмент. При этом предыдущий эфемерный сегмент становится сегментом второго поколения, а новый сегмент становится эфемерным.
Чтобы создать новый объект, нужно обнулить память и сдвинуть alloc_ptr. Обнулять память и производить другие расчеты для создания каждого объекта накладно. Чтобы ускорить этот процесс, в GC используется так называемый контекст размещения (allocation_context) – заранее проинициализированный участок памяти, размер которого заведомо подходит для размещения объекта. При выделении памяти нужно только увеличить значение alloc_ptr и убедиться, что его значение не превышает значения alloc_limit.
Когда памяти в контексте становится недостаточно, производится размещение нового контекста (под который снова обнуляется память и т.п.).
Чтобы не повредить кучу при выделении памяти под новый объект, производится легковесная блокировка.
Чтобы GC и EE могли получать информацию об объектах, каждый объект хранит не только данные, необходимые прикладному программисту, но и дополнительную служебную информацию. В нее входит индекс синхронизации, указатель на таблицу методов (или как его иногда называют по аналогии с C++ – указатель на vtbl) и размер массива (если объект является массивом). На рисунке 1 демонстрируется внутреннее устройство объекта и таблицы методов.
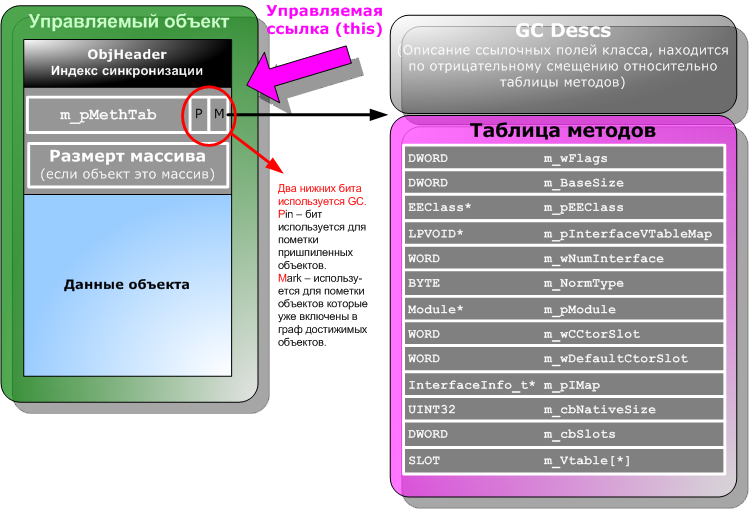
Рисунок 1. Служебная информация, помещаемая в управляемые объекты.
Индекс синхронизации. Для синхронизации при многопоточном доступе .NET позволяет использовать блоки синхронизации, которые могут быть ассоциированы с любыми объектами, размещенными в куче. Если попытаться применить к объекту конструкцию C# «lock ()» или передать ссылку на объект в метод Monitor.Enter(), EE, если это еще не сделано, ассоциирует с объектом блок синхронизации и запишет его индекс в специальное скрытое поле, имеющееся у каждого объекта. Это поле недоступно из управляемого кода честными путями. Однако если ссылочный объект не переопределяет функцию GetHashCode(), то по умолчанию она возвращает значение именно этого индекса. Блок синхронизации при этом не создается. Индекс блока синхронизации находится по отрицательному смещению относительно адреса начала объекта.
Указатель на таблицу методов и таблица методов. Каждый класс имеет уникальную таблицу методов, на которую ссылаются экземпляры этого класса. Объекты ссылаются на таблицу методов своего класса через поле m_pMethTab. Нижние два бита этого поля используются в качестве флагов. Один – Pin-бит – поднимается у объектов, которые временно нельзя перемещать в другую область памяти. Другой – Mark-бит – используется алгоритмом вычисления графа достижимых объектов. Оба этих бита используются только во время сборки мусора, так что в остальное время m_pMethTab можно использовать для доступа к таблице методов без предварительного маскирования. Стало быть, они не оказывают влияние на производительность EE.
Выше (по адресному пространству), над таблицей методов, находится описание, используемое сборщиком мусора (см. рисунок 2). Это описание состоит из количества записей и самих записей, идущих выше. С помощью этого описания код сборщика мусора может определять, на какие объекты ссылается некоторый объект. Каждая запись содержит информацию о некотором количестве ссылочных полей, располагающихся в объекте последовательно, и их смещении относительно начала объекта.
Классы, не помеченные атрибутом StructLayout со значением Explicit или Sequential, перестраиваются таким образом, чтобы имеющиеся в них ссылочные поля шли последовательно. Это ускоряет работу сборщика мусора.
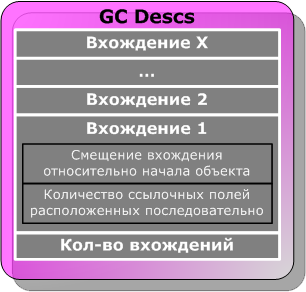
Рисунок 2. Описание раскладки ссылочных полей объекта.
Описание GC присутствует, только если объект содержит в себе поля ссылочного типа.
Если в классе такие поля есть, то поле m_wFlags содержит флаг enum_flag_ContainsPointers (0x40000).
Таким образом, имея список корневых ссылок, GC может вычислить граф живых объектов, не прибегая к услугам рефлексии или других высокоуровневых средств получения метаинформации (информации о типах).
| Тип поля | Имя поля | Описание |
|---|---|---|
| DWORD | m_wFlags | Флаги, описывающие детали реализации класса. Список флагов приведен в таблице 3.Нижнее слово (два нижних байта) описывает размер элемента массива или размер value-типа (в противном случае оно равно нулю).Общий размер объекта вычисляется как m_BaseSize плюс количество элементов, умноженное на величину, хранящуюся в нижнем слове этого поля (если там содержится значение, отличное от нуля). |
| DWORD | m_BaseSize | Базовый размер экземпляра класса. В базовый размер не входит размер, занимаемый элементами массива. |
| EEClass* | m_pEEClass | Указатель на описание класса исполняющей подсистемы. |
| LPVOID* | m_pInterfaceVTableMap | Указатель на подтаблицу карты методов интерфейса. |
| WORD | m_wNumInterface | Количество реализуемых интерфейсов. |
| BYTE | m_NormType | CorElementType для данного класса (для большинства классов равен ELEMENT_TYPE_CLASS) |
| Module* | m_pModule | Указатель на описание модуля. |
| WORD | m_wCCtorSlot | Номер слота, содержащего ссылку на статический конструктор. |
| WORD | m_wDefaultCtorSlot | Номер слота содержащего ссылку на конструктор, используемый по умолчанию (конструктор без параметров). |
| InterfaceInfo_t* | m_pIMap | Указатель на карту интерфейсов, реализуемых классом. |
| UINT32 | m_cbNativeSize | |
| DWORD | m_cbSlots | Количество слотов в таблице методов. |
| SLOT | m_Vtable[*] | Слоты таблицы методов (размер массива определяется переменной m_cbSlots). |
| Флаг | Значение | Описание |
|---|---|---|
| enum_flag_Array | 0x10000 | Объект является массивом. |
| enum_flag_large_Object | 0x20000 | Размер объекта превышает 85000 байт. |
| enum_flag_ContainsPointers | 0x40000 | Объект содержит поля ссылочного типа. |
| enum_flag_ClassInited | 0x80000 | |
| enum_flag_HasFinalizer | 0x100000 | В классе или его наследнике реализован метод Finalize(). Такие объекты сразу после создания должны быть помещены в очередь финализации. |
| enum_flag_Sparse | 0x200000 | Виртуальные таблицы для интерфейса разбросаны. |
| enum_flag_Shared | 0x400000 | Таблица методов разделяется между несколькими логическими классами. |
| enum_flag_Unrestored | 0x800000 | Ранее загруженный класс должен быть восстановлен. |
| enum_TransparentProxy | 0x1000000 | tranparent-прокси |
| enum_flag_SharedAssembly | 0x2000000 | Класс размещен в разделяемой сборке. |
| enum_flag_NotTightlyPacked | 0x4000000 | Поля value-типа не упакованы должным образом (значение недопустимо для классов). |
| enum_CtxProxyMask | 0x10000000 | Класс является контекстным заместителем (proxy). |
| enum_InterfaceMask | 0x80000000 | Класс является интерфейсом. |
Для создания ссылочного объекта в MSIL предусмотрена инструкция newobj:
newobj
instance
void SomeType::.ctor()
|
Для создания массива используется отдельная инструкция – newarr.
Сам процесс создания выглядит следующим образом:
1. EE выделяет память под объект. В общем случае эта операция сводится к сдвигу указателя на начало свободной области в эфемерном сегменте. Если в свободной области недостаточно места для размещения нового объекта, инициируется сборка мусора (чаще всего нулевого поколения). Выделяемый участок памяти инициализирован нулями, так что все ссылочные поля автоматически получают значение null.
2. EE инициализирует указатель на таблицу методов. Фактически после этого этапа объект является полноценным живым объектом. Однако на этом этапе на объект еще нет жестких ссылок, так что исключение внутри конструктора (если до этого не будет сделана жесткая ссылка) приведет к тому, что только что созданный объект автоматически будет считаться мусором. После этого действия у объекта уже можно вызвать виртуальные методы. Так что вызов виртуального метода в конструкторе некоторого базового класса может привести к вызову переопределенного в дочернем классе метода. Это поведение отличается от поведения, принятого в C++, так что C++-программистам стоит обратить на это особое внимание. Надо понимать, что вызов этот будет производиться еще до выполнения тела конструктора дочернего класса, так что, переопределяя методы, вызываемые из конструктора, нужно быть осторожным и не рассчитывать на инициализацию, производимую в конструкторе. Хорошей идеей будет также отказаться от дизайна, основанного на вызове виртуальных методов из конструктора. И вообще, лучше избегать всего, что может удивить пользователей ваших классов.
3. EE закладывает указатель на объект в регистр ecx и передает управление конструктору, указанному в инструкции newobj, породившей генерацию кода создания объекта. Регистр ecx используется по той причине, что по соглашению fastcall (используемому в .NET для вызова методов по умолчанию) через него передается первый параметр функции. Для экземплярных методов первым параметром всегда является ссылка на this.
4. Если во время работы конструктора не произошло необработанных исключений, то ссылка на объект помещается в ту или иную переменную области видимости, из которой вызывался код создания объектов. Сама переменная при этом может быть как локальной, располагаясь в регистре процессора или стеке, так и полем (статическим или полем экземпляра). В общем-то, размещение ссылки в первой переменной не являются частью процесса создания объекта. С точки зрения MSIL, после создания объекта ссылка помещается на вершину подразумеваемого стека виртуальной машины. Что дальше будет происходить со ссылкой, EE уже не интересует. Но фактически до размещения ссылки во внешней переменной процесс создания объекта еще не является законченным.
Хотя описанный выше процесс выглядит довольно прозрачным, у многих могут возникнуть сопутствующие вопросы. Попытаюсь предвосхитить их:
1. Что будет, если во время работы конструктора произойдет исключение? По сути, конструктор – это обычный метод. Он даже может быть заинлайнен JIT-компилятором. Так что исключение внутри него приведет к раскрутке стека и передаче управления к последнему объявленному блоку try/catch/finally.
2. Будет ли при этом объект полностью сформирован? Ответ на этот вопрос зависит от того, что понимать под словом «сформирован». С одной стороны – да, будет, так как память под объект уже выделена на предыдущих этапах, ей задано начальное значение (нули), проинициализирована ссылка на таблицу методов, объект находится внутри области памяти, отведенной для нулевого поколения, а стало быть, подлежит сборке мусора, а также, если объект имеет финализатор, то он помещен в очередь финализации, и после сборки мусора у него будет вызван финализатор (виртуальный метод Finalize() объявленный в базовом для всех ссылочных объектов классе System.Object (object в C#). Однако логическая инициализация может быть прервана на полуслове. Ведь, как я уже говорил, конструктор – это обычный метод, и исключение прерывает его как любой другой.
3. Что будет, если исключение произойдет внутри конструктора базового класса? Прежде чем ответить на этот вопрос, нужно оговориться, что конструктор базового класса не вызывается автоматически подсистемой выполнения. Таким образом, в общем случае он может быть вообще не вызван! Языки вроде C# и MC++ автоматически встраивают код вызова конструктора базового класса в начало кода конструктора класса наследника. Причем делают это, даже если объект наследуется от System.Object. Это совершенно бессмысленно, так как конструктор System.Object ничего не делает, но реально это не влияет на производительность, так как его вызов устраняется в процессе инлайнинга. После этого объяснения нетрудно понять, что вызов конструктора базового класса является не более чем обычным вызовом, а стало быть, подчиняется обычной логике обработки исключения. Понятно, что исключение внутри вызванного метода, если его не обработать, приведет к тому, что код, следующий за кодом, приведшим к исключению, выполнен не будет, и логическая инициализация не будет доведена до конца. Естественно, что если возможно было бы заполучить ссылку на такой недоинициализированный объект, то вероятность возникновения наложенных логических ошибок была бы очень велика. Но так как необработанное исключение приводит к раскрутке всего стека, то не выполняется и код, который должен использовать создаваемый объект. А стало быть, проблем, казалось бы, быть не может. Почему «казалось бы»? Да потому, что проблема все же может возникнуть. Дело в том, что в классе объекта может быть перегружен финализатор. Но об этом стоит поговорить отдельно.
4. Будет ли вызван финализатор, если в процессе работы конструктора произошло необработанное исключение? Да, будет. С точки зрения EE объект считается сформированным еще до вызова конструктора. Если объект реализует финализатор, то перед вызовом конструктора ссылка на него помещается в очередь финализации. Так как после раскрутки стека, вызванной исключением, ссылок на объект больше не существует, то после первой же сборке мусора объект будет считаться мертвым, и EE должен будет переместить ссылку на него из очереди финализации в другую очередь – freachable, которая отслеживается отдельным потоком, потоком финализации. Этот поток проверяет, не пуста ли freachable-очередь, и если не пуста, извлекает из нее ссылки на объекты и вызывает у них метод Finalize(). Таким образом, финализирован может быть даже объект, при инициализации которого произошло исключение. Вы должны учитывать подобный исход, когда перегружаете у объекта Finalize() или реализуете в нем управление ресурсами каким-то другим образом (обычно через интерфейс IDisposable). Вопрос обработки таких ситуаций – это сам по себе интересный вопрос, и лучше рассмотреть его в рамках отдельной статьи.
5. Может ли объект быть собран сборщиком мусора между присвоением ссылки на новый объект в переменную, удерживающую объект от смерти, и выходом из конструктора? Думаю, что даже здравый смысл подсказывает, что такого быть не может. Если бы это было возможно, пользоваться таким runtime-ом было бы невозможно. Но почему это происходит? Вернее, не происходит? Дело в том, что уборка мусора возможна только в так называемых безопасных точках. Безопасные точки – это позиции в исполняемом коде, в которых можно безопасно приостановить выполнение потока и произвести уборку мусора. Для этих позиций JIT-компилятор рассчитывает так называемые карты корней GC. Выполнение не может быть прервано в процессе создания объекта, если ссылка на объект еще не находится в одном из корней GC.
6. Что будет если не создать переменную для ссылочного объекта, но вызвать у него некий метод? Все будет ОК. :) Если в коде присутствует конструкция вроде:
new SomeClass().SomeMethod();
|
то объект не будет уничтожен до тех пор, пока ссылка на него будет требоваться методу SomeMethod(). Можно провести забавнейший эксперимент, демонстрирующий это. Скомпилируйте следующий код в release и запустите его на выполнение не из-под отладчика:
using System;
class A
{
publicvoid Test1()
{
Console.WriteLine("Вошли в Test1()");
// Производим сборку мусора.
GC.Collect();
GC.WaitForPendingFinalizers();
Test2();
Console.WriteLine("Вышли из Test1()");
}
publicvoid Test2()
{
Console.WriteLine("Выполнился Test2();");
}
~A() { Console.WriteLine("~A();"); }
staticvoid Main()
{
new A().Test1();
}
}
|
Как ни странно, на консоли вы увидите:
Вошли в Test1() ~A(); Выполнился Test2(); Вышли из Test1() |
Обратите внимание, что сборщик мусора утилизировал объект, несмотря на то, что в это время выполнялся его метод, а после того, как объект был уничтожен, удалось без проблем вызвать другой метод этого же класса.
Так как же такое возможно? Все дело в том, что этот метод не обращается к полям объекта или к его виртуальным членам. Это позволяет JIT-компилятору не учитывать this в картах корней GC для этих методов. Надо заметить, что подобные оптимизации JIT делает только в релизе, и только если приложение запускается не из-под отладчика. Если пометить метод Test2() модификатором virtual или обратиться к некоторому полю после кода, инициирующего сборку мусора, то все встанет на свои места, и объект не будет уничтожен во время сборки мусора, инициируемой в методе Test1(). Например, если в предыдущем тесте заменить описание метода Test2() на следующее:
public
virtual
void Test2()
{
Console.WriteLine("Выполнился Test2();");
}
|
то на консоль будет выведено:
Вошли в Test1() Выполнился Test2(); Вышли из Test1() ~A(); |
Это происходит потому, что во время вызова GC.Collect() на объект имелась ссылка в регистре процессора, и он был помечен как корень GC для точки, из которой производилась уборка мусора.
***
Память, выделяемая под объект, инициализируется нулями. Для ссылочных полей это обязательное условие. Ведь если в поле попадет некая грязь, то она может быть неверно интерпретирована сборщиком мусора, что приведет к его некорректной работе. Value-поля в принципе не обязаны инициализироваться, но типобезопасные языки вроде C# требуют, чтобы они тоже были инициализированы (явно или нулями), так что все объекты, создаваемые в управляемой куче, инициализируются по умолчанию нулями. Даже если в конструкторе объекта произойдет сбой, объект не может содержать некорректных указателей. Таким образом, CLR обеспечивает важный инвариант. Что бы ни случилось, все указатели в управляемых объектах могут быть или равны null (нулю), или обязаны указывать на живые объекты. В управляемом мире исключены такие вещи, как подвисшие ссылки или неверные указатели. В небезопасном режиме, конечно, можно нарушить это условие, но на то этот режим и назван небезопасным. В безопасном режиме подобные ошибки исключены. Это делает процесс выполнения предсказуемым, а отладку – простой и понятной.
Для прикладного программиста создание объекта является атомарной операцией. Так что если в процессе создания объекта возникнет необработанное исключение, то в стек ничего положено не будет. При этом произойдет раскрутка стека, и, в зависимости от наличия обрамляющих блоков try, будет или вызван обработчик исключения, или приложение будет завершено (с выдачей соответствующего диагностического сообщения). Реально обработка исключения является несколько более нетривиальным процессом, но сейчас это не важно. Главное, что исключение не может привести к тому, что прикладной код получит недоинициализированный объект.
EE вызывает только конструктор, указанный в инструкции newobj. Вызов конструкторов базовых классов осуществляется кодом, генерируемым компилятором и может вообще отсутствовать, если язык это допускает.
EE может инлайнить вызовы конструкторов. Следовательно, он может устранять вызовы пустых конструкторов. Так, например, вот такой код:
using System;
using System.Diagnostics;
class A
{
public A()
{
Debugger.Break();
_field = 1;
}
privateint _field;
publicint Test()
{
return _field;
}
}
class Program
{
staticvoid Main()
{
Console.WriteLine(new A().Test());
}
}
|
при выполнении в релиз-версии без отладчика приводит к тому, что JIT устраняет как вызов конструктора, так и метода Test.
Что действительно может вызвать непонимание, так это то, как нужно вести себя в случае возникновения исключений в конструкторе. Откровенно говоря, все, что связано с финализацией, является довольно большой темой, которой имеет смысл посвятить отдельную статью. Но не упомянуть о финализации тоже невозможно.
Чтобы вычислить граф живых объектов, GC делает следующее:
Собственно живыми объектами называются объекты, достижимые из набора корневых ссылок. Такие корневые объекты называют корнями GC. Понятно, что все объекты, на которые не осталось ссылок, являются мертвыми.
Чтобы алгоритм сканирования не зацикливался, и чтобы избежать многократного сканирования одних и тех же объектов, пройденные объекты помечаются специальным флагом. В качестве флага выступает как раз тот самый Mark-бит, о котором уже говорилось выше.
Алгоритм сканирования объектов эфемерного поколения отличается от алгоритма сканирования всего графа объектов. В процессе сканирования каждая ссылка проверяется на принадлежность к сканируемым поколениям (к сканируемому и более младшим). Так как эфемерные поколения располагаются в отдельном, и, что немаловажно, едином сегменте непрерывного адресного пространства, то не составляет труда сделать подобные проверки. В псевдокоде этот алгоритм можно представить следующим образом:
void ScanObject(
IntPtr objRef,
IntPtr startAddressOfGeneration,
IntPtr endAddressOfGeneration)
{
// Проверяем, что ссылка не нулевая, и что объект принадлежит к// диапазону адресов сканируемых поколений.if (objRef == null
|| GetMarkBit(objRef)
|| objRef < startAddressOfGeneration
|| objRef > endAddressOfGeneration)
return;
// Помечаем объект как проверенный.
SetMarkBit(objRef, true);
// Некоторые действия, предпринимаемые GC для живых объектов.foreach (IntPtr childRef in GetChildren(objRef))
ScanObject(childRef, startAddressOfGeneration, endAddressOfGeneration);
}
|
Полное сканирование отличается только двумя вещами. Во-первых, тем, что при этом не проверяется принадлежность объекта к диапазону адресов сканируемых поколений. А во-вторых, тем, что в списке корней GC отсутствует список ссылок из более старых поколений, о котором речь пойдет чуть ниже.
Учитывая то, что количество корней GC в типичном объектно-ориентированном приложении невелико, анализ корней GC происходит почти что молниеносно.
К корням GC относятся:
Если вести речь о полной уборке, то последний пункт не нужен. Граф достижимых объектов можно вычислить, отталкиваясь только от остальных корней GC. Но при уборке мусора в эфемерных поколениях встает одна проблема – проблема ссылок из более старших поколений.
Весь смысл алгоритма, основанного на множественных поколениях, заключается в том, чтобы отделить новые объекты от старых и проводить уборку мусора только для новых объектов. Это хорошо звучит на словах, но при практической реализации алгоритма возникает одна проблема. Чтобы вычислить, какие из новых объектов достижимы, неминуемо придется просканировать весь граф объектов (включая те, что располагаются в старших поколениях). Не правда ли, абсурдная ситуация? Ведь именно это и должна была устранить данная оптимизация.
Чтобы избавиться от необходимости каждый раз сканировать весь граф живых объектов, можно применить хитрый трюк. После очередной уборки мусора можно начать отслеживать все ссылки, которые делаются на молодые объекты из старых поколений. Список таких ссылок и будет использоваться как список дополнительных корней GC. Как показывает практика, обычно таких ссылок не очень много. Конечно же, корни GC могут указывать и на объекты старших по сравнению со сканируемым поколений. Но это не проблема, так как их сканирование предотвращается проверкой на принадлежность к адресному пространству сканируемых поколений (как это было продемонстрировано выше).
Отслеживанием ссылок на молодые объекты в объектах, принадлежащих старым поколениям, занимается специальный код, встраиваемый JIT-компилятором в каждой точке, где производится запись ссылки в поля других объектов. Такой код называется «барьером записи».
Есть разные способы учета ссылок из прошлых поколений. К сожалению, я не смог найти точную информацию о том, какой способ используется в .NET. Но по сути это и не важно. Важно понимать, что копирование ссылки на объект в поле другого объекта в .NET стоит дороже, нежели в неуправляемых языках. Это, можно сказать, плата за автоматическое управление памятью. В сумме со временем, затрачиваемым на уборку мусора, время, затрачиваемое на барьер записи, составляет основные затраты времени на управление памятью.
Затраты на барьер записи не зависят от объема, количества или частоты занятия объектов. Они зависят только от количества модификаций ссылочных полей. Так что, проектируя свое приложение, имеет смысл предпочитать алгоритмы, реже модифицирующие ссылочные поля.
При этом нужно понимать, что код барьера записи – это всего несколько инструкций, и выполняется он очень быстро. Также нужно понимать, что при работе с массивами код барьера записи может быть вынесен за пределы цикла и вообще мало влиять на общую производительность.
Барьер записи применяется не только в алгоритме GC, основанного на поколениях. Он применяется так же и в инкрементальных GC. Здесь он используется для отслеживания изменений графа объектов и для блокировки параллельного доступа к памяти.
Существует множество профайлеров памяти и средств обнаружения утечек памяти, предлагаемых независимыми поставщиками. Я не буду останавливаться на них, а скажу о двух средствах, доступных бесплатно.
SoS – расширение отладчика, позволяющее получить разнообразную информацию об управляемой куче. Это довольно низкоуровневая информация, и в ней не так-то просто разобраться, но если вы действительно наткнетесь на проблемы, связанные с утечкой управляемой памяти, имейте в виду, что это самый мощный инструмент из доступных бесплатно.
SoS – это расширение для отладчиков WinDbg и VS, оформленное в виде DLL. Более подробно о том, что такое SoS и как его запустить, рассказывается в статье «SOS: It's Not Just an ABBA Song Anymore» (http://msdn.microsoft.com/msdnmag/issues/03/06/Bugslayer/default.aspx).
Простой пример. Команда «!eeheap -gc» выводит список объектов, их количество и объем занимаемой ими памяти (в байтах). Эта команда полезна для выявления утечек и просто небрежного выделения объектов.
Команда dumpheap позволяет увидеть информацию об объектах кучи. Например, следующая команда выводит информацию обо всех экземплярах класса System.Byte[]:
!dumpheap -type System.Byte[] |
В блоге http://blogs.msdn.com/mvstanton/ приводится небольшой обучающий курс по SoS.
SoS лучше всего использовать из-под отладчика WinDbg, так как под управлением отладчика, встроенного в VS, доступны не все команды. WinDbg и его описание доступны по следующей ссылке: http://www.microsoft.com/whdc/devtools/debugging/default.mspx.
Исходные коды SoS доступны в коде Rotor.
CLR Profiler – это графическая утилита, позволяющая получить статистику использования памяти управляемым приложением. Утилита предоставляет множество интерактивных диаграмм. Самое приятное, что утилита поставляется с исходным кодом. Есть версия утилиты как для .NET 1.х, так и для 2.0, причем они несовместимы между собой. Так что если CLR Profiler не будет у вас работать, то возможно, вы просто скачали не ту версию.
CLR Profiler можно загрузить с сайта Microsoft по ссылке:
Статьи по CLR Profiler:
| ПРИМЕЧАНИЕ К сожалению, все эти материалы написаны на английском, но, надеюсь, что в будущем у меня дойдут руки и до статьи по проблемам управления памятью в .NET-приложениях. |
Всем известно, что при нехватке физической памяти приложение начинает сбрасывать в файл подкачки (swap file) редко используемые части занятой оперативной памяти.
Происходит это, когда приложению нужно памяти больше, чем на данный момент свободно в системе. При этом ОС в первую очередь пытается сбросить свои внутренние буферы (например, кэш файловой системы). Если этой памяти не хватает, начинается «свопинг».
Если память, сброшенная в файл подкачки, действительно используется редко, то замедление получается не такое уж большое. Ведь обращение к памяти относительно локализовано, и swapping производится не часто. Однако файл подкачки – это обычный дисковый файл, а скорость работы дисковой подсистемы в тысячи раз медленнее, чем скорость оперативной памяти.
Чтобы вы могли оценить затраты, связанные с подкачкой, я создал синтетический тест, в котором сначала занимается гандикап – огромное количество памяти (под 10 миллионов объектов, каждый из которых содержит массив длиной от 1 до 128 байт), а затем, не освобождая эту память (храня ссылки на объекты в массиве), производится эмуляция стандартной работы приложения (занимаются и освобождаются объекты). В результате создается ситуация, при которой во время эмуляции стандартной работы объем занятой оперативной памяти превышает объем физической памяти, доступной в этот момент в системе (в системе было установлен гигабайт оперативной памяти и параллельно было запущено немало приложений, общий объем занимаемой ими памяти приблизительно был равен 400 мегабайтам).
Основной тест написан на C# и, естественно, занимает память в управляемой куче. Также я создал аналогичные тесты на C++, занимающие память в обычной куче Windows, и модификацию C++-теста, занимающую память с использованием библиотеки QuickHeap (http://gzip.rsdn.ru/article/cpp/QuickHeap.xml), ускоряющей работу с памятью в C++-приложениях за счет использования более быстрого, но более прожорливого алгоритма.
Все три теста выполняются сначала с миллионом объектов в качестве гандикапа, а затем – с 10 миллионами. В первом случае объем занимаемой памяти, хотя и велик, но не превышает объема свободной памяти в системе, в которой производилось тестирование. Во втором случае объем гандикапа приблизительно равен объему оперативной памяти в системе. Расчет делается на то, что в обоих случаях после занятия гандикапа приложение не трогает принадлежащие к нему объекты. Вместо этого оно начинает интенсивно выделять большое количество объектов, не удерживая ссылки на них в управляемом тесте, и освобождая объекты в неуправляемых тестах. Таким образом, в основной части теста работа одновременно ведется с небольшим количеством объектов и, соответственно, памяти.
Ниже приведены результаты C++-теста, использующего стандартную кучу Windows:
e:\MyProjects\Tests\Perf\CppNew2\release>CppNew2.exe Timestamp: 4.238123 sec. ObjCount=11001000 e:\MyProjects\Tests\Perf\CppNew2\release>CppNew2.exe Timestamp: 37.864712 sec. ObjCount=20001000 |
Значение ObjCount – количество объектов, создаваемых при работе теста, включая как гандикап, так и рабочие объекты. Как видите, второй тест сильно отстал от первого, но отставание все же уложилось в разумные рамки (порядка 10 раз).
Если последить за картиной занятия памяти, то наблюдается следующее. При запуске с миллионом объектов объем занятой виртуальной памяти быстро поднималась примерно до 100 мегабайт и держалась на этом уровне до конца теста. Объем workset-а так же быстро достигал 100 мегабайт и так же неизменно держался до окончания теста.
При запуске теста с десятью миллионами объектов картина в корне отличалась. Сначала и workset и объем виртуальной памяти быстро достигали отметки в 400+ мегабайт. Далее объем виртуальной памяти продолжал постепенно (уже не так быстро) расти, а объем workset-а начал падать и стабилизировался на отметке 10-12 мегабайт (это объем занимаемый объектами, одновременно живущими на стадии «эмуляции обычной работы приложения»).
Совершенно ясно, что если бы приложение начало во время работы обращаться к предварительно занятым объектам (тем самым 10 миллионам), то все было бы значительно печально, так как при этом начался бы постоянный свопинг и основное время тратилось бы работу с винчестером.
Ради удовлетворения любопытства я повторил тот же тест с использованием своей библиотеки QuickHeap:
e:\MyProjects\Tests\Perf\CppNew2\release>CppNew2.exe Timestamp: 2.193539 sec. ObjCount=11001000 e:\MyProjects\Tests\Perf\CppNew2\release>CppNew2.exe Timestamp: 14.508904 sec. ObjCount=20001000 |
Забавно, что даже в условиях свопинга она показала намного лучший результат, чем стандартная куча Windows. Забавно это потому, что QuickHeap достигает своего быстродействия за счет перерасхода памяти. Но еще забавнее было наблюдать за картиной выделения памяти.
При запуске с миллионом объектов объем занятой виртуальной памяти скакнул к ~130 мегабайтам, что существенно выше, нежели в тесте с кучей Windows, но объем workset-а вырос всего ~96 мегабайт! Таким образом, получается, что QuickHeap хотя и тратит больше памяти, но обеспечивает лучшую локализацию данных (по крайней мере, при первом обращении).
Запуск теста с 10 миллионами предварительно занятых объектов привел к очень быстрому занятию порядка гигабайта виртуальной памяти и довольно быстрому увеличению этого объема до 1.3 гигабайта (напомню, что куча Windows постепенно росла вплоть до отметки в 1 гигабайт). Затем объем виртуальной памяти стабилизировался. Workset рос плавно (но быстро) до отметки в 400 мегабайт, после чего столь же плавно (но столь же быстро) спустился до отметки 14-9 мегабайт.
Большую скорость QuickHeap я в данном случае могу объяснить именно лучше локальности данных, что вызвало меньшее количество циклов свопинга. Так что хотя общее количество виртуальной занятой памяти было больше, но обращений к диску (как не странно) оказалось значительно меньше.
Ну, а что же GC? Для GC подобный тест оказался самым плохим паттерном использования. Вот его результаты:
e:\MyProjects\Tests\Perf\GC2\GC2\bin\Release>GC2.exe 00:00:02.1843580 Количество созданных объектов: 11001000 Количество сборок мусора поколения 0: 590 Количество сборок мусора поколения 1: 154 Количество сборок мусора поколения 2: 7 e:\MyProjects\Tests\Perf\GC2\GC2\bin\Release>GC2.exe 00:20:47.7608425 Количество созданных объектов: 20001000 Количество сборок мусора поколения 0: 769 Количество сборок мусора поколения 1: 273 Количество сборок мусора поколения 2: 27 |
Да-да! Две секунды на тест с миллионом объектов и более 20 минут (!) на тест с 10 миллионами!!! Почему такая разница? Думаю, самые прозорливые уже догадались, почему это так (я запустил параллельно архиватор! – шутка). Секрет заключается в том, что при сборке мусора второго поколения GC «дотрагивается» до всех объектов кучи. А это приводит к тому, что Windows поднимает страницы виртуальной памяти, на которых размещены объекты, с диска в физическую память. Это подтверждает и картина использования памяти. Объем виртуальной памяти начинает расти и очень быстро доходит до ~900 мегабайт. Далее он изменяется очень незначительно. А вот workset начинает постоянно расти и, достигнув отвертки в 900 мегабайт, сбрасывается до ~400-500 мегабайт. Далее он снова начинает расти до 900 и снова сбрасывается. Так продолжается на протяжении двадцати минут.
В принципе, это не нормально для сборщика мусора, основанного на поколениях, так как он должен был бы пропихнуть неиспользуемые в данный момент объекты во второе поколение и забыть про них. Но почему-то наличие объектов во втором поколении постоянно подталкивает GC к сборке мусора во втором поколении. Причем делает это он тем чаще, чем больше объем второго поколения. Налицо эвристика. В чем она заключается, не знаю, но учитывать это придется. Скорее всего, столь неразумное поведение GC связано с тем, что сборка мусора второго поколения запускается при нехватке памяти в системе. Получается замкнутый круг: нехватка памяти в системе провоцирует сборку мусора второго поколения, а сборка мусора второго поколения провоцирует поднятие страниц в память. На самом деле, это просчет программистов, писавших GC, так как по-хорошему реагировать нужно было бы на нехватку физической памяти.
Какой из этого можно сделать вывод? GC хорошо ведет себя, только если имеет достаточно свободной памяти. Если workset приложения начинает дергаться, то подбираясь к объему виртуальной памяти, то сбрасываясь, знайте, что, скорее всего, вы заняли слишком много лишней памяти. Большое количество сборок второго поколения также говорит о том, что профиль вашего приложения плохо совместим с эвристиками GC.
Что же делать? Пересмотреть политику создания и удержания в живых объектов. Возможно, отказаться от кэша или подгружать малозначимые данные по требованию. Еще один простой и дешевый совет – купить лишний гигабайт памяти. :)
В этой статье я рассказал о том, как приблизительно устроен GC. Надеюсь, что эта информация поможет вам создавать более быстрые и менее ресурсоемкие приложения.
Я встречал много фобий, связанных с непониманием принципов работы GC. Чаще всего встречается мнение, что GC непригодно для интерактивных приложений. Надеюсь, что из статьи ясно, что это не так, поскольку механизмы вроде GC, основанного на поколениях, и Concurrent GC делают задержки сборки мусора незаметными для человека, взаимодействующего с компьютером. Вторая фобия – GC отъедает непомерно много памяти. Для этого заблуждения, по крайней мере, есть основания. При наличии большого объема памяти .NET-приложения действительно не стесняются в запросах. Но на самом деле это связано с тем, что алгоритмы GC работают более эффективно при использовании больших объемов памяти. Если памяти в системе начинает не хватать, GC переходит в более экономный режим работы. Многие противники GC, не находя аргументов, заявляют, что «GC не пригодно для задач реального времени». Сборщик мусора, реализованный в .NET, действительно непригоден для задач реального времени. Однако будем честными друг с другом – многие ли занимаются такими задачами? К тому же данная характеристика – это всего лишь свойство реализации. Так, например, GC экспериментальной ОС Singularity (см. статью в этом номере), используемый в ядре, отвечает требованиям реального времени.
| Оценка 1285
[+1/-0]
Оценить
|
