 Оценка 491
Оценка 491 
 Оценить
Оценить 





| Оценка 491 Оценить
|
Программа Researcher
mfc71.dll, msvcp71.dll, msvcr71.dll
Во втором номере журнала RSDN была опубликована статья Андрея Мартынова о метаданных .NET. Автор рассмотрел логическую структуру метаданных и показал, каким образом можно получить доступ к данным при помощи Reflection. Reflection пользуется внутренним представлением метаданных, предоставляемым CLR. CLR считывает их из таблиц, присутствующих в файле. Таким образом, Reflection показывает логическую организацию метаданных. Целью же этой статьи является описание физической организации исполняемых файлов .NET, и, в частности, метаданных.
У читателя может возникнуть вопрос – а зачем, собственно, рассматривать эту физическую организацию данных, ведь в стандарте ECMA-335 формат метаданных описан очень подробно? Дело в том, что в процессе изучения физической структуры метаданных у меня сложилось твёрдое убеждение, что то, что есть на самом деле, не всегда соответствует стандарту ECMA-335. В стандарте, например, невозможно найти некоторые данные, без знания которых невозможно произвести анализ файла. Некоторые вещи, по моему мнению, просто не соответствуют действительности. Достаточно часто я вместо стандарта использовал SS CLI, где содержатся ответы на большинство вопросов, связанных с функционированием CLR. Не имея под руками исходных кодов SS CLI, разобраться в некоторых подробностях просто невозможно.
Мы с коллегами нередко беседовали на темы исследования и отладки кода в .NET, при этом неоднократно звучали вопросы типа «А где находятся эти метаданные в файле? А как добраться непосредственно до MSIL'а?». В этой статье я постараюсь показать, каким образом можно получить ответы на эти и другие вопросы, проанализировав исполняемый файл .NET без помощи Reflection.
Чтобы досконально изучить структуру исполняемого файла и, в частности, метаданных, я написал программу Researcher, которую и использовал при подготовке данной статьи. Программа находится в стадии разработки, но, думаю, и «as is» она может принести немалую пользу при анализе внутренних структур исполняемых файлов (кстати, именно эта программа «заставила» меня выяснить, что же такое «<Module>», но об этом – позже). Эту программу можно найти на компакт-диске, поставляемом с этим выпуском журнала.
Основной задачей программы является построение «карты» файла, то есть определение, в каком месте файла какие данные находятся. Думаю, эту задачу программа решает полностью. Тем не менее, я уверен, что у неё есть недостатки. Если кто-то из читателей напишет мне письмо и выскажет пожелания относительно улучшения программы, я буду благодарен.
Итак, все метаданные, включаемые в состав исполняемого .NET-файла, представляются в виде хипов (heaps). Обычно в каждой программе бывает пять хипов. (#~, #Strings, #US, #Blob, #GUID). Хип #~, в свою очередь, состоит из таблиц, размер и формат строк в которых меняется от файла к файлу.
Таким образом, перед тем, кто пытается проанализировать метаданные без использования Reflection, сразу же встаёт несколько задач:
Я не буду долго рассказывать о том, что такое заголовки исполняемых файлов, и какая информация в них находится. Скажу только, что в начале исполняемого файла находятся заголовок DOS и заголовок PE-файла, который, в свою очередь, включает в себя «обязательную» и «необязательную» части (см. рисунок 1).
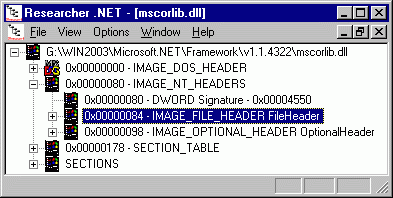
Рисунок 1. Общая структура исполняемого файла.
В конце «необязательного» заголовка находится массив DataDirectory, состоящий из шестнадцати структур типа IMAGE_DATA_DIRECTORY (тип описан в winnt.h). RVA (relative virtual address, относительный виртуальный адрес) «точки входа» в метаданные (см. рисунок 2) содержится в элементе этого массива с индексом 14 (можно использовать в качестве индекса значение IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR).
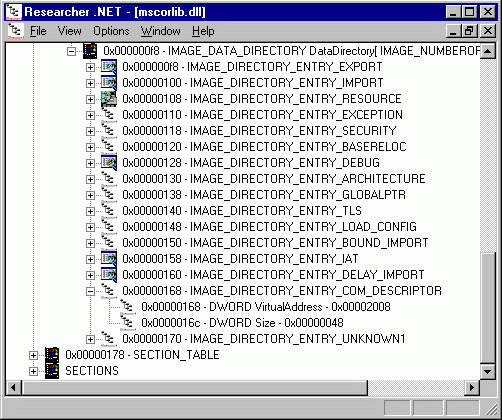
Рисунок 2. RVA "точки входа" в метаданные.
По указанному адресу находится структура типа IMAGE_COR20_HEADER (рисунок 3), определение которой приведено ниже (взято из файла CorHdr.h):
// CLR 2.0 header structure.
typedef
struct IMAGE_COR20_HEADER
{
// Информация о версии
ULONG cb;
USHORT MajorRuntimeVersion;
USHORT MinorRuntimeVersion;
// Таблицы метаданных, флаги и информация о точке входа
IMAGE_DATA_DIRECTORY MetaData;
ULONG Flags;
ULONG EntryPointToken;
IMAGE_DATA_DIRECTORY Resources;
IMAGE_DATA_DIRECTORY StrongNameSignature;
IMAGE_DATA_DIRECTORY CodeManagerTable;
IMAGE_DATA_DIRECTORY VTableFixups;
IMAGE_DATA_DIRECTORY ExportAddressTableJumps;
// Информация о прекомипилированном образе файла// ( только для внутреннего использования )
IMAGE_DATA_DIRECTORY ManagedNativeHeader;
} IMAGE_COR20_HEADER;
|
| ПРИМЕЧАНИЕ Вся низкоуровневая часть CLI и, скорее всего, .NET написана на C++. Поэтому все фрагменты структур, приведенные в статье, описаны на этом языке. |
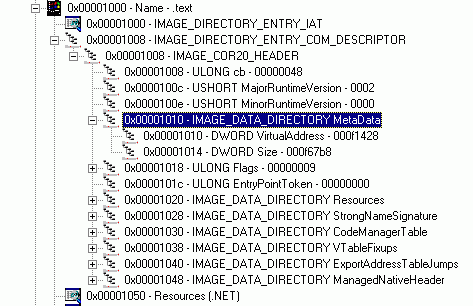
Рисунок 3. Структура типа IMAGE_COR20_HEADER.
Сразу становится ясно, какого рода информацию, используемую CLR, можно «выкачать» из исполняемого файла. По содержимому этой структуры можно определить, в каком месте исполняемого файла находятся те или иные данные. В частности, метаданные в mscorlib.dll (том файле, который показан на скриншотах) расположены по RVA = 0xf1428. Повторю, что в данном случае приведён RVA, а не смещение относительно начала файла.
| ПРИМЕЧАНИЕ Многие элементы в PE-файлах задаются с помощью RVA. RVA – это просто смещение элемента относительно начального адреса, по которому файл будет загружаться в память (например, при запуске на исполнение). Представьте, например, что загрузчик отображает PE-файл в память начиная с адреса 0x10000 в виртуальном адресном пространстве. Если какая-то таблица начинается с адреса 0x10464, ее RVA будет 0x464. Это не полное и не совсем точное описание, но его достаточно для понимания этой статьи. Для приведенного выше примера расчет RVA выглядит так: (Virtual address 0x10464)-(base address 0x10000) = RVA 0x00464 |
Итак, можно считать, что «прямой доступ» к данным, использующимся .NET, получен. Это и есть ответ на вопрос о том, где в исполняемом файле находятся метаданные.
По только что найденному смещению находится структура типа STORAGESIGNATURE. К сожалению, её описание в файлах, поставляемых в составе Platform SDK, отсутствует. Однако описание этой структуры можно найти в файле mdfileformat.h, который входит в состав SS CLI:
struct STORAGESIGNATURE
{
ULONG lSignature; // "Магическая" сигнатура (0x424A5342 )
USHORT iMajorVer; // Старшая часть версии файла
USHORT iMinorVer; // Младшая часть версии файла
ULONG iExtraData; // Смещение следующей структуры с информацией
ULONG iVersionString; // Длина строки с названием версии
BYTE pVersion[0]; // Строка, содержащая название версии.
};
|
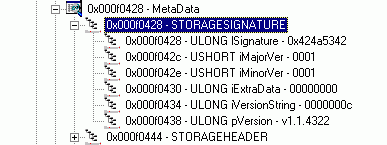
Рисунок 4. Структура типа STORAGESIGNATURE.
Я думаю, понятно, что никакой полезной для анализа информации в этой структуре не содержится, а о назначении ее полей можно судить по их названиям. Я, честно говоря, не нашёл ответа на вопрос о том, смещение чего должно записываться в поле iExtraData, но в своё оправдание могу сказать, что я ни разу не встречал файла, в котором значение этого поля было бы ненулевым. Однако если кто-то из читателей найдёт возможным сообщить мне о назначении этого поля и пришлёт соответствующий файл, я буду весьма признателен.
Идём дальше. Взглянув на рисунок, можно заметить, что непосредственно за структурой типа STORAGESIGNATURE следует структура типа STORAGEHEADER, описанная в том же файле:
struct STORAGEHEADER
{
BYTE fFlags; // Флаги STGHDR_.
BYTE pad;
USHORT iStreams; // Сколько всего стримов используется
};
|
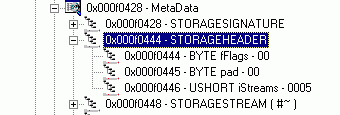
Рисунок 5. Структура типа STORAGEHEADER.
Главным полем в этой структуре является поле iStreams, которое определяет число потоков в анализируемом файле. На рисунке 5 видно, что в данном случае в файле присутствует пять потоков. Таким образом, мы получили число следующих за STORAGEHEADER структур типа STORAGESTREAM. Тип STORAGESTREAM описан в том же файле mdfileformat.h:
//**********************************************************************
// Такой структурой описывается каждый поток, она включает в себя смещение
// и размер данных. Название потока представлено ANSI-строкой с завершающим
// нулём.
//**********************************************************************
struct STORAGESTREAM
{
ULONG iOffset; // Смещение потока в файле метаданных
ULONG iSize; // Размер потокаchar rcName[MAXSTREAMNAME]; // Начальный символ названия потока
………<удалены inline-методы>
};
|
Так! Становится не просто теплее, а уже горячо! Каждая структура типа STORAGESTREAM содержит в себе смещение потока, его размер и название. Экспериментальным путём я установил, что смещение отсчитывается от начала блока метаданных, то есть от начала структуры типа STORAGESIGNATURE.
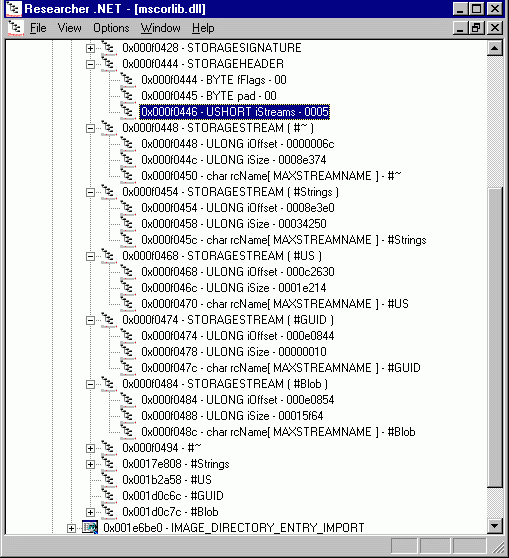
Рисунок 6. Заголовки потоков и потоки в исполняемом .NET-файле.
На рисунке 6 наглядно показаны все структуры типа STORAGESTREAM и расположение описываемых ими потоков. Что можно сказать? Да только то, что мы ответили и на вопрос о том, как определить число хипов и смещения, по которым они располагаются.
Упомяну, что об этих структурах и о назначении полей можно прочитать в п. 23.2.1 и 23.2.1 второй части стандарта ECMA-335.
Скажу сразу, что пока я не ставлю перед собой задачу рассказывать о назначении того или иного блока информации. Сейчас я расскажу только о формате, не более. О назначении мы поговорим позже.
Итак, первым и, возможно, самым простым с точки зрения организации данных, является хип с именем «#Strings». В нём находится последовательность UTF-8-строк. На месте первой строки, правда, находится не сама строка, а только завершающий эту строку нуль. На рисунке 7 хорошо видно, что первая строка хипа является пустой.
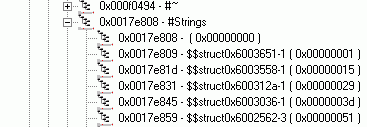
Рисунок 7. Хип #Strings
Кстати, обратите внимание на числа, которые приведены после строк. Эти числа представляют собой смещения строк относительно начала хипа. Обращения к строкам производятся именно по этим смещениям.
В аспекте структуры более интересен формат хипа, который называется «#Blob». В нём хранятся последовательности числовых данных в виде «число байтов в последовательности-последовательность». Назначение этих данных может быть самое разное. Это может быть цифровая подпись, могут быть закодированные описания типов аргументов методов и так далее. С назначением каждого из "блобов" необходимо "разбираться" отдельно. Естественно, никаких указателей на то, где на него производится ссылка, "блоб" не содержит. Никаких разделителей в хипе нет, всё определяется только размером каждого «блоба». Как и в случае хипа строк, первый байт хипа «блобов» является нулевым, я называю его «индикатором».
Чтобы правильно определить размер «блоба», необходимо проанализировать несколько первых байтов этого «блоба». Я не буду здесь описывать механизм определения размера, он описан в разделе 23.2.4 второй части стандарта ECMA-335. Наглядно хип «#Blob» представлен на рисунке 8.
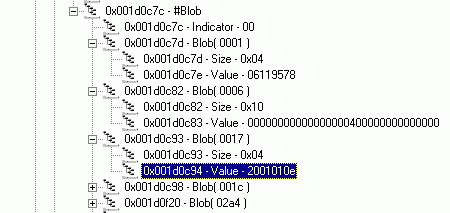
Рисунок 8. Хип #Blob
Как и в предыдущем случае, обращение к конкретному «блобу» осуществляется только по его смещению относительно начала хипа.
Структуру, подобную структуре #Blob, имеет и хип #US. Вся разница между ними состоит только в том, что последовательность состоит не из чисел, как в «блобе», а из символов UNICODE. Здесь стоит сказать, что, судя по всему, размер каждого элемента хипа #US кодируется точно так же, как и в случае «блобов», однако документального подтверждения этому предположению я нигде не нашёл.
Доступ к элементам этих хипов осуществляется по смещению относительно начала хипа. Нулевой элемент имеет смещение, равное нулю, смещение последующих элементов, естественно, определяется совокупной длиной предыдущих. Разумеется, обратиться к элементу хипа по индексу невозможно. Хип #GUID хранит GUID-ы, ссылки на которые могут встречаться в метаданных. Так как GUID-ы имеют фиксированный размер, обращение к элементам этого хипа производится по индексу.
Самое интересное я приберёг напоследок. Те хипы, о которых рассказано выше, не приближают нас к пониманию структуры исполняемого файла. Эта структура разложена чуть ли не по кирпичикам в хипе «#~» (да-да, это не описка, имя хипа на самом деле состоит из диеза и тильды). В исходных текстах SS CLI этот хип ещё называется потоком сжатой модели (compressed model stream). Думаю, из сказанного ниже читателю станет понятно, почему этот поток называется сжатым.
Хип #~ представляет собой стрим (stream), в который сериализована совокупность таблиц. О таблицах стоит, наверное, поговорить особо. Дело в том, что, как и любой другой, стрим #~ необходимо раскодировать, потому что число таблиц, число записей в каждой таблице и даже формат записи в таблицах меняются от файла к файлу (у меня содержимое этих таблиц ассоциируется с чем-то зыбким и колышущимся… :-) ), следовательно, осуществить доступ к данным таблицы нельзя ни по индексу, ни по смещению. Чтобы вычислить смещение какой-то таблицы, программа должна знать размер всех предыдущих таблиц. Кстати, этим данные исполняемого файла .NET отличаются от обычного исполняемого PE-файла, в котором можно было определить смещение любой секции и проанализировать её. Здесь же для проведения анализа необходимо знать количество строк в каждой таблице и размер записи (строки) в таблице. Но даже зная всё это, нельзя получить доступ к определённому полю без сведений о смещении относительно начала записи. Таким образом, обрабатывать таблицы в программе можно только последовательно, от начала и до конца.
По моему мнению, стандарт ECMA-335 в основном посвящён формату именно #~. В этой части статьи я постараюсь рассказать, каким образом можно «добраться» до таблиц, описывающих исполняемый файл .NET.
Поток сжатой модели начинается с класса CminiMdSchemaBase (не удивляйтесь, что в данном случае используется не структура, а класс, ведь в C++ класс от структуры отличается только областью видимости членов), который находится в файле metamodel.h. Это определение приводится ниже:
//*****************************************************************************
// Схема расположения данных. Для каждой таблицы в ней хранится число записей, а также
// размеры потоков строк, “блобов», GUID’ов. Обладая этой информацией, мы можем вычислить
// размеры записей, а затем и размеры таблиц.
//*****************************************************************************
class CMiniMdSchemaBase
{
public:
ULONG m_ulReserved; // Зарезервировано, должно быть равно нулю.
BYTE m_major; // Номер версии
BYTE m_minor;
BYTE m_heaps; // Биты размеров хипов
BYTE m_rid;
// Виты размеров хиповenum {
HEAP_STRING_4 = 0x01,
HEAP_GUID_4 = 0x02,
HEAP_BLOB_4 = 0x04,
PADDING_BIT = 0x08,
DELTA_ONLY = 0x20,
EXTRA_DATA = 0x40,
HAS_DELETE = 0x80,
};
unsigned__int64 m_maskvalid; // Маска наличия таблиц unsigned__int64 m_sorted; // Маска отсортированных таблиц
< Несколько функций, входящих в класс, не приведены. >
};
|
Эта структура приведена на рисунке 9:
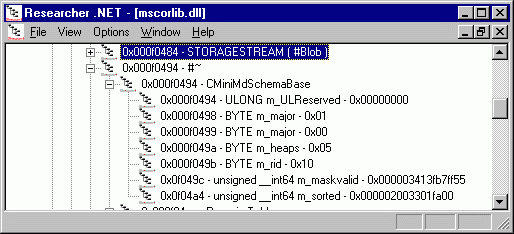
Рисунок 9 Структура типа CminiMdSchemaBase.
Кстати, описание этой структуры в текстовом виде можно найти в п. 23.2.6 второй части стандарта ECMA-335.
С точки зрения исследования метаданных в этой структуре представляет интерес только поле m_maskvalid. Именно оно определяет, какие таблицы присутствуют в файле.
Здесь необходимо сказать, что в исполняемом файле может присутствовать до сорока двух (0х2а) таблиц. Каждая из таблиц имеет своё предназначение. При этом у каждой таблицы есть свой номер. В исполняемом файле таблицы следуют строго в порядке возрастания номеров. Младшие сорок два бита поля m_maskvalid являются индикаторами присутствия таблиц в файле. Если нулевой бит установлен в единицу, то в файле присутствует нулевая таблица, равен единице первый бит – первая таблица присутствует в файле и т.д. В частности, в примере, приведённом на рисунке 9, видно, что в файле присутствует нулевая таблица, вторая, четвёртая и так далее. Естественно, что число битов этого поля, установленных в единицу, равно числу таблиц, присутствующих в исполняемом файле.
Таким образом, мы ответили ещё на один вопрос. Теперь мы знаем, какие таблицы включены в исполняемый файл. Ниже, в таблице 1, приведен список таблиц, используемых .NET:.
| Номер таблицы | Название таблицы | Назначение таблицы |
|---|---|---|
| 0 (0x0) | Module | Описание модуля (модулей) программы |
| 1 (0x1) | TypeRef | Описание типов, на которые производятся ссылки в программе |
| 2 (0x2) | TypeDef | Описание типов, использующихся в программе |
| 3 (0x3) | FieldPtr (в стандарте не описана) | Данные в таблице используются только в том случае, когда модуль загружен в память |
| 4 (0x4) | Field | Описание полей типов, перечисленных в TypeDef |
| 5 (0x5) | MethodPtr (в стандарте не описана) | Данные в таблице используются только в том случае, когда модуль загружен в память |
| 6 (0x6) | Method | Описание методов типов, перечисленных в TypeDef |
| 7 (0x7) | ParamPtr (в стандарте не описана,в исследованных файлах не встречалась) | Данные в таблице используются только в том случае, когда модуль загружен в память |
| 8 (0x8) | Param | Описание параметров типов |
| 9 (0x9) | InterfaceImpl | Описание реализации интерфейсов |
| 10 (0xa) | MemberRef | Описание членов классов, расположенных в других сборках, на которые производятся ссылки |
| 11 (0xb) | Constant | Значения констант |
| 12 (0xc) | CustomAttribute | Значения атрибутов |
| 13 (0xd) | FieldMarshal | Информация, позволяющая определить, каким образом данные будут представлены при взаимодействии с неуправляемым (unmanaged) кодом |
| 14 (0xe) | DeclSecurity | Атрибуты системы безопасности |
| 15 (0xf) | ClassLayout | Информация, позволяющая CLI определить, каким образом должны быть расположены классы внутри сборки |
| 16 (0x10) | FieldLayout | Информация, позволяющая CLI определить, каким образом должны быть расположены поля внутри сборки |
| 17 (0x11) | StandAloneSig | Сложные сигнатуры методов и полей, параметры инструкций косвенного вызова (calli) |
| 18 (0x12) | EventMap | Перечень событий, обрабатываемых классами |
| 19 (0x13) | EventPtr (в стандарте не описана, в исследованных файлах не встречалась) | Данные в таблице используются только в том случае, когда модуль загружен в память |
| 20 (0x14) | Event | Описание событий |
| 21 (0x15) | PropertyMap | Перечень свойств классов |
| 22 (0x16) | PropertyPtr (в стандарте не описана,в исследованных файлах не встречалась) | Данные в таблице используются только в том случае, когда модуль загружен в память |
| 23 (0x17) | Property | Описание свойств |
| 24 (0x18) | MethodSemantics | Информация, позволяющая связать методы и относящиеся к ним свойства и события |
| 25 (0x19) | MethodImpl | Дескрипторы явного переопределения методов |
| 26 (0x1a) | ModuleRef | Список модулей, на которые производятся ссылки |
| 27 (0x1b) | TypeSpec | Спецификация типа |
| 28 (0x1c) | ImplMap | Информация о неуправляемых (unmanaged) методах, которые могут вызываться управляемым кодом сборки |
| 29 (0x1d) | FieldRVA | RVA значений, по умолчанию присваиваемых полям |
| 30 (0x1e) | ENCLog (в стандарте не описана, в исследованных файлах не встречалась) | Информация об изменениях метаданных, произведённых во время отладки программы (edit-and-continue) |
| 31 (0x1f) | ENCMap (в стандарте не описана, в исследованных файлах не встречалась) | Вспомогательная информация об edit-and-continue |
| 32 (0x20) | Assembly | Информация о сборке |
| 33 (0x21) | AssemblyProcessor | В настоящее время не используется |
| 34 (0x22) | AssemblyOS | В настоящее время не используется |
| 35 (0x23) | AssemblyRef | Информация о сборках, на которые производятся ссылки |
| 36 (0x24) | AssemblyRefProcessor | В настоящее время не используется |
| 37 (0x25) | AssemblyRefOS | В настоящее время не используется |
| 38 (0x26) | File | Описание файлов, используемых сборкой |
| 39 (0x27) | ExportedType | Описание экспортируемых сборкой типов |
| 40 (0x28) | ManifestResource | Описание управляемых (managed) ресурсов |
| 41 (0x29) | NestedClass | Описание вложенных классов |
По названиям таблиц можно догадаться об их назначении. К сожалению, нумерация этих таблиц никоим образом не соответствует логической организации информации, и то, из каких побуждений таблице давался тот или иной номер, осталось для меня загадкой. И хотя на анализ содержимого этих таблиц этот порядок не влияет, он всё же вызвал у меня в своё время некоторые неприятные эмоции.
Как я уже говорил выше, чтобы получить смещение какой-либо таблицы, необходимо произвести разбор всех предшествующих ей таблиц. В общем, технология работы с данными, записанными в этот хип, похожа на технологию, применяемую для работы с любыми другими потоками (ведь недаром этот хип называется потоком сжатой модели) – сначала нужно распаковать содержимое в соответствующие структуры.
Итак, мы ответили на все вопросы, поставленные в начале статьи, за исключением одного. Пока мы не знаем, как определить число строк в каждой из таблиц. Но, как говорится, нет ничего проще. Сразу за структурой типа CminiMdSchemaBase следует массив двойных слов. Размер этого массива равен количеству таблиц, присутствующих в файле, при этом между элементами массива и таблицами существует однозначное соответствие, то есть нулевой элемент массива соответствует таблице с минимальным номером, присутствующей в файле, первый – следующей таблице и так далее. В каждом элементе массива записано число строк соответствующей таблицы. На рисунке 10 показан массив, о котором мы говорим:
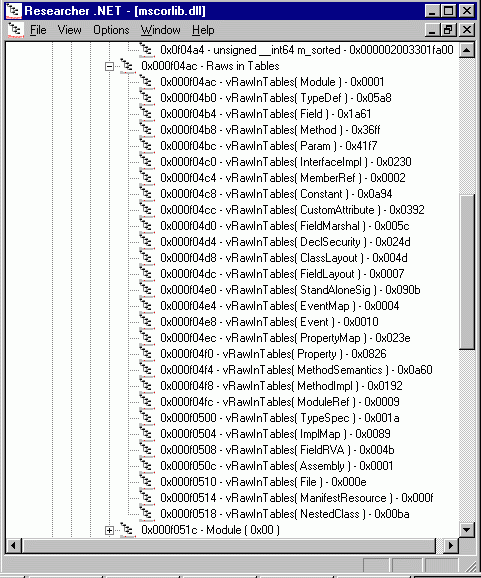
Рисунок 10. Массив, определяющий число строк в таблицах.
За названием элемента массива в скобках указано имя таблицы. Обратите внимание, что разбирается достаточно большая сборка. В качестве подопытной сборки в этой статье используется основная сборка .NET – mscorlib.dll. Это самая большая сборка, встречавшаяся мне. В частности, 14079 (0x36ff) методов и 16887 (0x41f7) параметров внушают уважение, как и 1448 (0x5a8) типов, определённых в ней.
За массивом следуют непосредственно таблицы.
Итак, мы ответили на все вопросы, поставленные в начале статьи. Однако возникают новые вопросы, на которые я постараюсь ответить в следующей части статьи:
Какие данные хранятся в таблицах?
От каких факторов зависит формат данных, представленных в таблице?
Каким образом можно определить формат таблиц?
Какие действия необходимо произвести для того, чтобы правильно «расставить» всё по своим местам?
Как я уже говорил выше, формат таблиц, по которым «распределены» метаданные, является переменным. От файла к файлу могут изменяться число и размер строк, а также размер полей. Подчёркиваю – от файла к файлу, формат всех строк одной таблицы в пределах файла один и тот же.
Данные в таблицах могут быть разделены на несколько категорий. Во-первых, это могут быть поля строго определённой длины, например, слово, хранящее в себе флаги. Естественно, в стандарте ECMA-335 описаны все такие поля и жёстко определена длина каждого из этих полей.
Во-вторых, это могут быть индексы или смещения. Их длина может составлять два или четыре байта. Обычно индексы представляют собой номера строк в других таблицах. Их длина равна четырём байтам только в том случае, если число строк в таблице, на которую они ссылаются, невозможно записать двумя байтами. Думаю, понятно, что достаточно проблематично найти таблицу, число строк в которой будет больше 65536. Ведь даже количество методов в mscorlib.dll меньше этого значения.
Длина полей, в которые записываются смещения данных относительно начала хипа, тоже может быть равна двум или четырём байтам. Как и в предыдущем случае, до четырёх байтов размеры этих полей увеличиваются только в том случае, если смещение в хипе невозможно записать двумя байтами. При этом замечу, что случаи, когда смещение в хипе превышает 64К, встречаются сплошь и рядом. В частности, на рисунке приведёно окончание хипа #Strings того же файла mscorlib.dll. Обратите внимание на смещения строк в этом хипе.
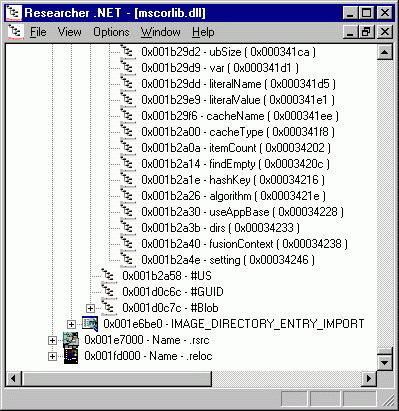
Рисунок 11.
Таким образом, в случае, когда данные, хранящиеся в поле, представляют собой индекс строки другой таблицы, для определения размера поля необходимо произвести следующие действия:
Если данные представляют собой смещение в другом хипе, необходимо действовать по-другому. Во-первых, данные о размере хипов можно получить из соответствующих хипам структур типа STORAGESTREAM. Однако есть более простой способ. В структуре типа CminiMdSchemaBase есть поле m_heaps, представляющее собой набор флагов. Значения флагов (HEAP_STRING_4, HEAP_GUID_4 и HEAP_BLOB_4) приведены в перечислении, описанном в этой же структуре. Если, скажем, флаг HEAP_STRING_4 установлен, то длины всех полей всех таблиц, значения которых являются индексами в хипе строк, равны четырём байтам. Аналогично обстоит дело и с полями, ссылающимися на хип «блобов» или «GUID'ов». Таким образом, определив, какие флаги выставлены в поле m_heaps, мы фактически определяем размер полей, ссылающихся на хипы.
И, наконец, ещё одна категория данных – так называемые закодированные данные. Чтобы извлечь из этих данных необходимую информацию, нужно преобразовать их в другую форму, занимающую, как правило, больше места, нежели исходные данные. К сожалению, заранее ничего о длине этих данных сказать нельзя. Кстати, при определении длины этих данных Microsoft использует хитрый приём, описание которого я в стандарте ECMA-335 не нашёл, как ни старался. Однако ниже я постараюсь описать этот приём.
При формировании таблиц используются двенадцать закодированных типов. В большинстве случаев данные, закодированные в них, размещены следующим образом. В младших байтах закодирован номер таблицы, а в старших байтах – номер строки в этой таблице. Следовательно, для получения номера строки необходимо выделить несколько младших байтов, получив тем самым номер таблицы, после чего сдвинуть оставшуюся часть (слова или двойного слова) вправо, получив тем самым номер строки. Логично предположить, что сдвиг происходит на то число байтов, которое необходимо для записи максимального номера таблицы, на которую может ссылаться закодированный элемент. Но почему-то в некоторых случаях в стандарте указано, что ссылки могут производиться, скажем, на две таблицы, а на самом деле резервируется возможность ссылок на пять таблиц. Естественно, если речь идёт о двух таблицах, достаточно было бы одного бита, а для пяти таблиц необходимо три бита. Возможно, поэтому применяется следующий способ:
Определяется число таблиц, на которые может ссылаться закодированный токен.
Определяется число битов, на которые необходимо сдвигать вправо закодированный токен для получения номера строки.
Производится сдвиг закодированного токена на число, записанное в соответствующем элементе массива.
Список закодированных токенов и число разрядов, на которые необходимо производить сдвиг, приведены в таблице 2.
| Наименование закодированного токена | На какие таблицы может ссылаться | На сколькоразрядовнеобходимосдвигать |
|---|---|---|
| TypeDefOrRef | TypeDefTypeRefTypeSpec | 2 |
| HasConstant | FieldDefParamDefProperty | 2 |
| HasCustomAttribute | MethodDefFieldDefTypeRefTypeDefParamDefInterfaceImplMemberRefModulePermissionPropertyEventSignatureModuleRefTypeSpecAssemblyAssemblyRefFileExportedTypeManifestResource | 5 |
| HasFieldMarshal | FieldFDefParamDef | 1 |
| HasDeclSecurity | TypeDefMethodDefAssembly | 2 |
| MemberRefParent | TypeDefTypeRefModuleRefMethodDefTypeSpec | 3 |
| HasSemantic | EventProperty | 1 |
| MethodDefOrRef | MethodDefMemberRef | 1 |
| MemberForwarded | FieldDefMethodDef | 1 |
| Implementation | FileAssemblyRefExportedType | 2 |
| CustomAttributeType | MethodDefMemberRef | 3 |
| ResolutionScope | ModuleModuleRefAssemblyRefTypeRef | 2 |
Что ж, осталось только взять в руки стандарт ECMA-335 и аккуратно, поле за полем, строка за строкой, таблица за таблицей, разобрать всю информацию, которая присутствует в исполняемом файле .NET.
Однако всего сказанного еще недостаточно для понимания того, что находится в недрах исполняемого файла .NET. Если разобрать все таблицы исходя только из их формата, то к пониманию «философии» метаданных это не приблизит.
В данной статье не приводится описание структуры таблиц метаданных – такое описание достаточно объемно. Его можно найти в уже упоминавшемся стандарте ECMA-335. Дальше речь пойдет о логической структуре метаданных и о том, каким образом можно найти код того или иного метода.
К данному моменту стало примерно ясно, откуда у метаданных «ноги растут». Но, честно говоря, хотя все мелочи разобраны, за деревьями не видно леса. Не совсем понятно, каким образом данные из таблиц превращаются в те стройные структуры, которые показывает ILDasm и другие программы, способные отражать метаданные .NET. Что ж, давайте постараемся разобраться и в этом.
В этой части мы постараемся найти ответы на очередные возникшие перед нами вопросы:
Наверное, самое простое, что можно сделать – это получить список использующихся в программе пространств имён. Для этого необходимо просто-напросто просмотреть таблицу определения типов (TypeDefs, таблица 2). У этой таблицы есть поле Namespace. Значение этого поля представляет собой смещение в потоке #Strings названия Namespace’а, в которое входит описываемый тип. На рисунке 12 заметно, что тип String включён в пространство имён System.

Рисунок 12. Строка таблицы TypeDefs.
Кстати, нетрудно догадаться, что в поле Name записано название типа, точнее, смещение этого названия в том же потоке #Strings. Кроме того, в поле Extends заносится смещение названия типа, от которого данный тип унаследован. Скажем короче – тип String, унаследованный от типа System.Object, расположен в пространстве имён System. Таким образом, этих данных достаточно, чтобы построить иерархию, в которой будет определено «происхождение» того или иного типа.
Однако здесь есть одна тонкость. На рисунке 13 показано начало таблицы типов файла mscorlib.dll c “нераскрытыми” элементами:
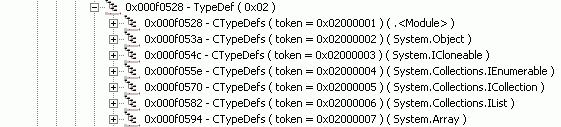
Рисунок 13. Начало таблицы типов файла mscorlib.dll.
Если внимательно присмотреться к изображению на рисунке, то можно заметить, что начальным элементом таблицы является некий тип с именем «<Module>». Интересно, что ни ILDasm, ни, скажем, Reflector этого типа не показывают. Интересно… А ларчик, как говорится, просто открывался. По мнению Microsoft, понять, что такое глобальные данные, гораздо легче, если представлять их как членов какого-то невидимого абстрактного общедоступного класса. Этим классом и является класс с именем <Module>, у которого нет базового класса и который не реализует ни одного интерфейса. Если, к примеру, какая-то переменная относится к классу <Module>, это означает, что данная переменная является глобальной.
Но как определить, к какому типу относятся данные или код (для методов)? Что ж, постараемся ответить и на эти вопросы. В частности, на рисунке 17 можно заметить, что в каждой строке таблицы TypeDefs есть поле MethodList. Значение этого поля является индексом в строке таблицы методов (Method, таблица 6), начиная с которой располагаются данные о методах, принадлежащих этому классу. На рисунке 17 видно, что список методов, принадлежащих классу String, располагается, начиная со строки с номером 155 (0x009b).
Считается, что список методов завершается строкой, предшествующей номеру, указанному в поле MethodList описания следующего типа. В частности, список методов класса String простирается до метода с номером 0x137, это показано на рисунке 14.
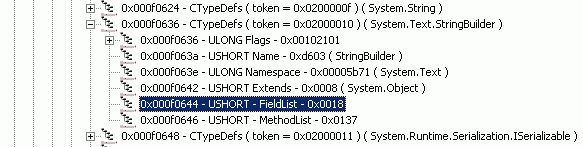
Рисунок 14.
Так оно и бывает в большинстве случаев. Однако, как быть в тех случаях, когда описание типа является последним в таблице типов? В этом случае считается, что список методов продолжается до конца таблицы методов.
Но и здесь не обошлось без исключений из правил. Что бы Вы сказали, уважаемый читатель, если бы вдруг увидели в поле MethodList значение, превышающее количество строк в таблице методов? Такая ситуация является признаком того, что у анализируемого класса просто-напросто нет методов. В этом случае в поле MethodList записывается значение, на единицу превышающее число строк в таблице методов. На рисунке 15 видно, что значение поля MethodList превышает число строк в таблице методов (0x36ff).
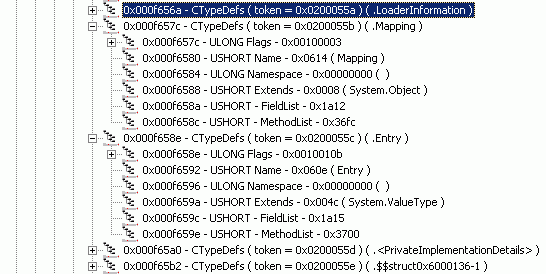
Рисунок 15. Значение 0x3700 поля MethodList больше числа строк в таблице методов (0x36ff).
Это означает, что типы, список которых начинается с токена 0x0200055c, методов не имеют.
И, наконец, остался один-единственный вопрос, на который пока не найден ответ. Каким образом определить, что класс является вложенным и понять, какой класс является классом-контейнером для вложенного класса? Естественно, нет ничего невозможного и в этом. Для того, чтобы определить, что класс является вложенным, достаточно заглянуть в поле флагов. О назначении этих флагов можно прочитать в стандарте ECMA-335. Замечу, что в том случае, когда класс является вложенным, у него установлен один из флагов, в название которых входит слово «Nested».
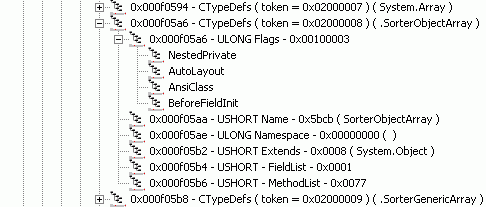
Рисунок 16. Вложенный класс SorterObjectArray.
На рисунке 16 видно, что у класса SorterObjectArray установлен флаг NestedPrivate. Это является признаком того, что класс является вложенным. Для того, чтобы найти класс, являющийся контейнером, необходимо заглянуть в таблицу вложенных классов (NestedClass, таблица 0x29). Каждая строка этой таблицы состоит из двух полей. Первое поле, NestedClass, является индексом строки в таблице TypeDefs, соответствующей вложенному классу. Значение второго поля – это индекс строки в той же таблице, соответствующей классу-контейнеру:

Рисунок 17. Вложенный класс и класс-контейнер.
На рисунке 17 видно, что класс SorterObjectArray является классом, включённым в класс Array.
Представим, что нам известно смещение таблицы методов. В частности, на скриншоте, приведённом на рисунке 11, видно, что её смещение равно 0x1072с2. Именно в этой таблице находится список всех методов, которые определены в исполняемом файле. Что ж, попробуем понять, что здесь к чему. Заодно немного попрактикуемся в определении размеров полей таблиц.
Итак, заглянув в стандарт ECMA-335, можно увидеть, что каждая строка таблицы методов состоит из нескольких полей. Наиболее важным представляется начальное поле размером четыре байта. В этом двойном слове находится RVA кода метода. К этому полю мы ещё вернёмся.
Второе поле (его смещение от начала строки равно четырём) длиной 2 байта и третье поле (смещение равно шести) содержат различные флаги. Я не буду рассматривать назначение этих флагов, думаю, желающие смогут ознакомиться с назначением этих флагов в стандарте.
Следующее поле содержит в себе индекс в хипе строк, начиная с которого располагается имя метода. Здесь нельзя забывать о том, что этот индекс может быть двух- и четырёхбайтовым. В нашем случае длина хипа строк больше 0xffff, следовательно, длина поля, определяющего имя метода, равна четырём.
Соответственно, четырём равна и длина следующего поля, представляющего собой индекс в хипе «блобов». Об этих индексах нам ещё придётся говорить, но в следующих статьях.
И, наконец, последнее поле, индекс в таблице параметров (0x8). Его длина равна четырём байтам.
Таким образом, можно сделать вывод о том, что длина строки в таблице методов в данном случае равна восемнадцати байтам.
На рисунке 18 наглядно показана структура строки таблицы методов.
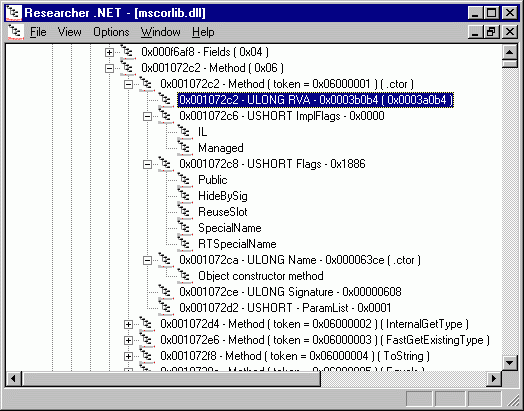
Рисунок 18. Структура строки таблицы методов.
Возможно, у читателя возникнет вопрос – а что это за таинственный «токен», следующий за словом «method»? Дело в том, что 4-байтовые токены фактически являются идентификаторами строк таблиц. Старший байт токена содержит номер таблицы, а младшие три байта – номер строки. Здесь необходимо обратить внимание на то, что нумерация строк таблиц начинается с единицы, а не с нуля. Например, идентификатором начальной строки таблицы определения типов (TypeDefs) будет являться токен 0x02000001, а идентификатором, скажем, седьмой строки этой же таблицы будет токен 0x02000007.
Но вернёмся к первому полю. Выше я сказал, что это поле хранит в себе RVA кода метода. Это не совсем так, потому что код метода предваряется некоторыми структурами. Поэтому лучше было бы сказать, что в первом поле находится RVA этих структур, непосредственно за которыми и расположен код метода. Осталось только разобраться, что это за структуры...
Итак, возьмём байт, на который указывает RVA, и «препарируем» его. Согласно стандарту, формат структуры, предшествующей коду, определяется тремя (заметьте – тремя!) младшими битами первого байта структуры. Соответствующие определения формата можно найти в файле CorHdr.h. Я привожу их ниже:
CorILMethod_TinyFormat = 0x0002,
CorILMethod_FatFormat = 0x0003,
|
Другими словами, если в младших двух битах записано значение 10b, то используется tiny-формат. Если же записано значение 11b, то используется fat-формат. В том случае, если используется tiny-формат, старшие шесть битов байта содержат размер кода. Очевидно, что tiny-формат может использоваться только в тех случаях, когда размер кода не превышает 26, то есть шестидесяти четырех байтов. Код начинается непосредственно с байта, следующего за начальным.
На рисунке 19 приведён пример tiny-метода:

Рисунок 19. Организация данных, описывающих tiny-код.
В тех случаях, когда записать код в tiny-формате невозможно, используют fat-формат. Структура, описывающая fat-формат, приведена ниже:
typedef
struct IMAGE_COR_ILMETHOD_FAT
{
unsigned Flags : 12; // Флаги unsigned Size : 4; // Размер этой структуры в двойных словахunsigned MaxStack : 16; // .maxstack
DWORD CodeSize; // размер кода
mdSignature LocalVarSigTok; // токен, начиная с которого расположены// сигнатуры локальных переменных
} IMAGE_COR_ILMETHOD_FAT;
|
Младшие два бита поля Flags содержат код формата, я уже об этом говорил выше. Из флагов используются только два бита. Соответствующие определения приведены ниже:
CorILMethod_InitLocals = 0x0010, // для всех локальных переменных вызывается// конструктор по умолчанию CorILMethod_MoreSects = 0x0008, // за текущим блоком следует другой блок |
В поле Size хранится размер структуры IMAGE_COR_ILMETHOD_FAT. В текущей версии её размер равен трём, но сам факт наличия этого поля говорит о том, что Microsoft оставила за собой право изменения формата этой структуры.
Поле MaxStack определяет необходимую для данного метода глубину стека. Необходимо заметить, что в IL глубина стека определяется не в байтах, а в слотах, независимо от размера элементов. По умолчанию это значение равно восьми.
Поле CodeSize определяет размер кода, который следует за структурой типа IMAGE_COR_ILMETHOD_FAT.
И, наконец, в поле LocalVarSigTok содержится токен строки таблицы StandAloneSig. В этих строках хранятся сигнатуры локальных переменных, используемых методом.
Рисунок 20 демонстрирует организацию данных, описывающих fat-код.
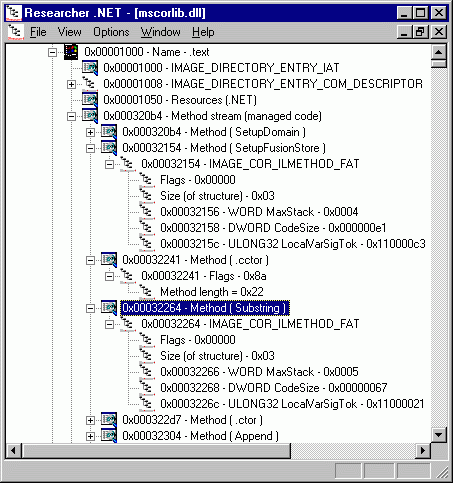
Рисунок 20. Организация данных, описывающих fat-код (для сравнения – по смещению 0x00032241 находится tiny-код).
Но и это ещё не всё. Если посмотреть на название одного из битов поля Flags, CorILMethod_MoreSects, то нетрудно догадаться, что если этот флаг установлен, то за кодом следуют ещё какие-то данные. И эти данные, естественно, представлены в своём собственном формате. Поэтому для того, чтобы получить возможность анализировать весь находящийся в исполняемом файле код, необходимо рассмотреть обработчики исключений.
Итак, если флаг CorILMethod_MoreSects установлен, то следом за последним байтом кода, на ближайшей границе двойного слова расположено объединение, описание которого приведено ниже:
typedef
union IMAGE_COR_ILMETHOD_SECT_EH
{
IMAGE_COR_ILMETHOD_SECT_EH_SMALL Small;
IMAGE_COR_ILMETHOD_SECT_EH_FAT Fat;
} IMAGE_COR_ILMETHOD_SECT_EH;
|
Чтобы определить, с какой структурой необходимо в данном случае работать, нужно проанализировать начальный байт, принадлежащий объединению. Фактически этот начальный байт представляет собой набор следующих флагов:
// коды атрибутов
typedef
enum CorILMethodSect
{
CorILMethod_Sect_Reserved = 0,
CorILMethod_Sect_EHTable = 1,
CorILMethod_Sect_OptILTable = 2,
// Маска для декодирования типа кода
CorILMethod_Sect_KindMask = 0x3F,
// fat-формат
CorILMethod_Sect_FatFormat = 0x40,
CorILMethod_Sect_MoreSects = 0x80,
} CorILMethodSect;
|
Насколько я могу судить, из первой группы в настоящее время используется только один флаг, CorILMethod_Sect_EHTable, то есть за кодом метода может следовать только код обработчика исключения. Как и код, обработчик исключения также может быть представлен в двух форматах, small и fat. Признаком формата является флаг CorILMethod_Sect_FatFormat. И, наконец, если установлен флаг CorILMethod_Sect_MoreSects, это значит, что за обработчиком исключения следует ещё один обработчик, и так до тех пор, пока соответствующий флаг не будет сброшен.
«Сброшенный» флаг CorILMethod_Sect_FatFormat означает, что в данном случае используется т.н. small-формат, другими словами, приведённое выше объединение можно рассматривать как структуру типа IMAGE_COR_ILMETHOD_SECT_EH_SMALL.,:
typedef
struct IMAGE_COR_ILMETHOD_SECT_EH_SMALL
{
IMAGE_COR_ILMETHOD_SECT_SMALL SectSmall;
WORD Reserved;
IMAGE_COR_ILMETHOD_SECT_EH_CLAUSE_SMALL Clauses[1];
} IMAGE_COR_ILMETHOD_SECT_EH_SMALL;
|
Перед тем, как идти дальше, хотелось бы сказать о том, что размер этой структуры фактически является переменным. Думаю, понятно, что массив Clauses в данном случае может состоять как из одного, так и из нескольких элементов. Поэтому попутно отметим, что для проведения анализа необходимо каким-то образом определить размерность данного массива.
Структуру проще, чем IMAGE_COR_IL_SECT_SMALL, придумать, наверное, сложно:
typedef
struct IMAGE_COR_ILMETHOD_SECT_SMALL
{
BYTE Kind;
BYTE DataSize;
} IMAGE_COR_ILMETHOD_SECT_SMALL;
|
Эта структура показана на рисунке 21
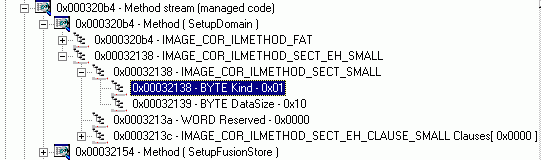
Рисунок 21. Структура IMAGE_COR_ILMETHOD_SECT_SMALL
В ней следом за байтом флагов, который уже разобран «по косточкам», следует байт, в котором записана длина кода обработчика исключения. Совершенно очевидно, что длина этого кода не может превышать 256 байтов. Однако именно этот байт и позволяет определить количество элементов в массиве. Оно определяется очень просто. Чтобы определить размер массива, необходимо значение DataSize разделить на размер структуры типа IMAGE_COR_ILMETHOD_SECT_EH_CLAUSE_SMALL, речь о которой пойдёт буквально через несколько строк.
Слово, следующее за этой структурой, предназначено только для выравнивания последней на границу двойного слова, хотя, как следует из названия, в дальнейшем оно может использоваться для каких-то целей.
И, наконец, то, что позволяет определить положение защищённого блока и обработчика исключения:
typedef
struct IMAGE_COR_ILMETHOD_SECT_EH_CLAUSE_SMALL
{
#ifdef _WIN64
unsigned Flags : 16;
#else// !_WIN64
CorExceptionFlag Flags : 16;
#endifunsigned TryOffset : 16;
unsigned TryLength : 8; // relative to start of try blockunsigned HandlerOffset : 16;
unsigned HandlerLength : 8; // relative to start of handlerunion
{
DWORD ClassToken;
DWORD FilterOffset;
};
} IMAGE_COR_ILMETHOD_SECT_EH_CLAUSE_SMALL;
|
В этой структуре хранятся не только все необходимые смещения. Значения поля Flags определены в следующем перечислении:
typedef
enum CorExceptionFlag
{
COR_ILEXCEPTION_CLAUSE_NONE,
COR_ILEXCEPTION_CLAUSE_OFFSETLEN = 0x0000, // Устаревшее
COR_ILEXCEPTION_CLAUSE_DEPRECATED = 0x0000, // Устаревшее// Если этот бит установлен, EH используется для фильтра
COR_ILEXCEPTION_CLAUSE_FILTER = 0x0001,
// Используется в качестве finally
COR_ILEXCEPTION_CLAUSE_FINALLY = 0x0002,
COR_ILEXCEPTION_CLAUSE_FAULT = 0x0004,
} CorExceptionFlag;
|
В поле TryOffset записывается смещение начала «защищаемого» блока кода, отсчитываемое от начала кода метода, TryLength – длина «защищаемого» блока. Аналогично, HandlerOffset и HandlerLength представляют собой смещение и длину обработчика исключений. Таким образом, получив эту информацию, можно определить, в каких местах в дизассемблированном коде нужно ставить операторы try и catch.
Последнее поле хранит в себе токен типа исключения или смещение кода обработчика. Как интерпретировать значение этого поля, зависит от флага COR_ILEXCEPTION_CLAUSE_FILTER.
Что касается fat-формата описания обработчика исключений, то он отличается от приведённого выше только длинами полей и отсутствием поля Reserved. Я не буду приводить его описание, оно находится в файле CorHdr.h.
Наглядно структура типа IMAGE_COR_ILMETHOD_SECT_EH_CLAUSE_SMALL приведена на рисунке 22.
Рисунок 22. Структура типа IMAGE_COR_ILMETHOD_SECT_EH_CLAUSE_SMALL.
Итак, найден не только RVA структуры, предшествующей коду, но определено место начала кода. Фактически определён и размер кода. Разобраны, наверное, все возможные варианты расположения кода в исполняемом файле. Надеюсь, что после внимательного прочтения этого раздела у читателя не останется вопросов о том, какой код каким образом и в каком месте исполняемого файла расположен.
Надеюсь, у читателей появилось понимание того, каким образом из исполняемого файла можно «выкусить» метаданные и код, а также понимание того, как из отдельных таблиц может проявиться полная картина, демонстрируемая ILDasm’ом и другими программами, позволяющими просматривать метаданные. Возможно, в дальнейшем я продолжу рассказ о метаданных и расскажу о том, что осталось за пределами этой статьи – поля, атрибуты, свойства, события, «блобы»…
| Оценка 491 Оценить
|
