The PegGrammar - a macro-attribute of a class (applicable to classes) designed to automate the creation of parsers for various formal languages. It can be applicable to mainstream programming languages (for example, you can find the grammar for C# here http://code.google.com/p/nemerle/source/browse/nemerle/trunk/snippets/csharp-parser/CSharpParser/Parser.n) and to simple grammars such as those usually dealt with regular expressions.
To use PegGrammar’s macro you need to add references to Nemerle.Peg.Macros.dll, Nemerle.Peg.dll libraies of the current project. These libraries are supplied in the compiler’s delivery. But it is better to collect these libraries from source code considering that PegGrammar currently still developing rapidly. Their source code can be found here.
It’s very simple to use the macro:
[PegGrammar(Options = EmitDebugSources, Start Rule,
grammar
{
Rules
}
)]
publicclass Parser
{
Handler methods for the rules
} |
We use PEG-notation in PegGrammar (http://en.wikipedia.org/wiki/Parsing_expression_grammar). It is very similar to extended Backus-Naur notation (BNF) but has a different interpretation.
While BNF describes the language, PEG describes the parser for the language (i.e. how to parse a string). This makes the behavior of the PEG similar to the behavior of regular expressions.
The PEG allows only unambiguous grammars (grammars with one parse tree) in contrast to the BNF. It makes PEG an excellent means to describe computer languages but not natural languages.
Use the next link to get more complete information about the PEG http://en.wikipedia.org/wiki/Parsing_expression_grammar. Here I'll describe only the main differences between PEG and BNF. The first and main difference is the use of the priority choice operator "/" in PEG instead of the enumeration operator «|» in the BNF. Shortly speaking an enumeration operator desrcribes alternative sub-rules that comprise the described rule. In addition alternatives should not interfere with each other (for unambiguous grammars). The priority choice operator behaves differently. If you parse the string in accordance with the first sub-rule, then the remaining rules (follows the "/") are ignored. If the string is not parsed in accordance with the first sub-rule, the position of the parse backtracked to the position of the sting, from which we began previous parse, and we trie to parse the string in accordance with the second sub-rule. If the string is parsed in accordance with the second sub-rule, then the remaining rules are ignored again. If not, it tries to parse a string in accordance with the third sub-rule, and so on, until you go through all the options. If the string is not parsed in accordance with any of the sub-rules then the parsing is unsuccessful.
An example of the priority choice operator:
simplExpr = num / parenthesesExpr / unaryMinus; |
This section describes the grammar of the PEG (in terms of PEG itself).
// PEG grammar
Rule = Attributes? RuleName ReturnType? '=' OrderedChoice ";";
ExpandableRule = Attributes? OperatorRuleName ReturnType? ";";
ExpandRule = Attributes? OperatorRuleName "is" RuleName '=' OrderedChoice ";";
OrderedChoice = Sequence ('/' Sequence)*;
Sequence = PredicateRule+;
PredicateRule = ('!' / '&')? CardinalityRule;
CardinalityRule = SimpleRule ('?' / '+' / '*')?;
SimpleRule = '%' / Scope / RuleName (":" Precedence)? / Ranges / Char
/ String / '(' OrderedChoice ')' / Empty;
Ranges = '[' Range+ ']';
Range = Char ".." Char / UnicodeCategory;
Precedence = ['0' .. '9']+;
ReturnType = ':' NemerleType
RuleName = Identifier;
OperatorRuleName = Identifier;
Attribute = "Inline"
/ "InlineAllSubrules"
/ "Extensible"
/ FailureRecovery
/ '%''(' MethodHandler ',' SkipRule ')'
/ '<' RuleName
/ '>' RuleName
Attributes = '[' Attribute (',' Attribute)* ']'
MethodHandler = Identifier;
SkipRule = OrderedChoice;
FailureRecovery = "FailureRecovery"'(' MethodHandler ',' StopRule ',' SkipRule ')';
// Area allowing to arrange the transactions
ScopedRule = OrderedChoice;
ScopeName = Identifier;
Scope = ScopeName '{' ScopedRule '}'; |
Here:
Identifier – correct Nemerle's identifier.
Char – correct Nemerle's character literal (for example: 'A' or '\'').
String – correct Nemerle's string literal.
NemerleType – description of Nemerle’s type (may include a namespace and type’s parameres).
UnicodeCategory – standard abbreviations for Unicode-categories (these abbreviations allow you to specify a class of characters).
The Rule specifies a named rule of parsing. Named rules can (and should) define a handler method, i.e., a method, which will be called whenever a successful analysis is done for the appropriate rule.
Example:
Sequence = PredicateRule+; |
OrderedChoice = E1 / E2 / ... / En |
The priority selection (OrderedChoice) specifies the sub-rules, which in turn try to parse a string in the current position. If the string at the current position is successfully recognized by one of the sub-rules then the rest of the sub-rules is ignored and the position shifts in the number of recognized characters. In this case the priority selection signals about the success of a parsing. If a parsing of the current sub-rule fails then it goes back in the parse position that precedes the beginning of analysis of this sub-rule. A parsing tries to parse a string according to the following sub-rule and so on. This process continues until successful recognition or exhausting the list of sub-rules (the latter is regarded as a failure of parsing of the operator of the priority selection ).
Priority selection may have an unlimited number of sub-rules as you can see from the grammar. Thus, the sequence (Sequence) is a degenerate case of priority selection.
Example:
RuleName / Range / Char / String |
E1 E2 ... En |
The sequence consists of one (degenerate case) or more predicative rule (PredicateRule). The predicative rules are parsed from left to right. If the analysis of one of the predicative rules fails, the analysis of the sequence is also considered a failure. A failure leads to a backtrack of the current parsing rule.
Example:
Char ".." Char ScopeName '{' ScopedRule '}' |
&E !E |
The predicative rule consists of an optional (in the degenerate case) predicate ('!' or '& ') and control rule (CardinalityRrule). The predicate converts the CardinalityRrule into predicative rule (ephemeral). Such a rule is recognized only with one purpose: whether one can continue further parsing. Information about the analysis of predicative sub-rule will be lost and the current position does not change.
Character ‘&’ denotes a positive predicate. It returns success if the rule which follows him is recognized, and the failure otherwise.
Character ‘!’ denotes a negaitive predicate. It returns success if the rule which follows him is not recognized, and the failure otherwise.
Example:
delimitedComment = "/*" (!"*/" any)* "*/"; |
The example parses a comment in the style of C language (/ * comment */). Here we use the predicate ‘!’ to make sure that parsed character is not part of a sequence “*/”. The sequence “*/” closes the comment.
E* E+ E? |
The control rule (CardinalityRule) consists of a simple rule and an optional control structure. We support three control structures:
Examples:
PredicateRule+
('/' Sequence)*
ReturnType? |
The simple rule (SimpleRule) consists of a set of scope (Scope), of literal expression, of ranges of characters, of a reference to the other (named) rule, of a sub-rule of any type (a sub-rule should be enclosed in brackets), of an empty rule (it parses nothing).
Examples:
PredicateRule Sequence ('?' / '+' / '*') ".." ['\u0000'..'\uFFFF'] 'Z' |
The ranges (Ranges) contain a list of ranges of characters or abbreviations of names (UnicodeCategory).
Examples:
['0'..'9'] ['\u0000'..'\uFFFF'] ['A'..'Z', 'a' .. 'z', '\u037F' .. '\u1FFF'] [Lu, Ll, Lt, Lm, Lo, Nl] ScopeName { Type* } |
The character literal allows us to describe one character.
Example:
't'
|
The string literal defines a sequence of characters.
Example:
"try"
|
This example is equivalent of the following one:
't'
'r'
'y'
|
Attributes allow you to specify additional meta-information for the named rule. Currently the following attributes are supported.
Inline attribute indicates that the rule should be opened at the place (i.e. a code of calling a function that parses the rule is substituted by a code of a function itself). The attribute is used for manual optimization. In general, there is no need to specify this attribute. The parser calculates a list of rules which must be opened at the place during the optimization of the rules.
InlineAllSubrules attribute indicates that all sub-rules should be opened at the place.
The FailureRecovery attribute allows you to specify "restore point" after the discovery of an error by a parser. If the grammar doesn’t set restore points or cut-off points (cut-off points are mentioned below), then a parser stops an analysis when it detects the first error (since all rules are rolled back) and reports an error. FailureRecovery attribute allows you to specify that this rule should not be backtracked when an error occurs. In addition FailureRecovery attribute specifies the handler method that generates stub (AST-element containing information about an error). Also FailureRecovery attribute specifies a rule which allows you to skip bad data in the input string. In this case a parser may continue to parse the line even if the line does not partially match the grammar of language (the line contains errors). That allows us to identify several errors at once.
The ‘%’ attribute specifies additional information for the cut-off points. You specify the cut-off point by the same character ‘%’ in a body of the rule. The cut-off point (as well as FailureRecovery attribute) is designed to restore a parsing of the input string after the discovery an error. Unlike FailureRecovery attribute, the cut-off points can not only prevent a backtrack of a parsing rule but also forcing the parser to create a branch of AST containing those elements that were parsed by the time of the error detection. In addition, the cut-off points are applicable only to the rules consisting of the sequences (Sequence). The recovery begins at the cut-off points only if the parser analyzed the initial part of the rules (prefix) which goes to cut-off points. That guarantees that the backtracking is not associated with the standard backtracking of a rule (which may happen, for example, in the case of parsing of an empty expression). Cut-off points can achieve better recovery after a detection of errors, as more accurately identify the location errors. Cut-off points allow creating AST containing a piece of data correctly entered by the user (that can be used, for example, in IntelliSense).
The '<' RuleName, '>' RuleName attributes are used in conjunction with the Extensible attribute to specify the relative priority of the rules. These attributes mark the rules intended for use in the extension points. These attributes will be used for sorting of sub-rules inside of extensible rule (marked with Extensible attribute).
The PegGrammar lets you create an expendable rule.
Rule can be expanded:
Examples:
[DynamicExpandable] expr : int; //rule can be expanded externally typeDecl : TypeDeclaration; // statically expendable rule |
You can specify the strength of binding when referring to expendable rules from the bodies of other rules.
In order to extend the rule describe the new rule and indicate the string “is” and the name of expendable rule after the name of the new rule. The examples describe a set of extensions for typeDecl rule (defined in the previous section):
classDecl is typeDecl = modifiers? "class"s identifier "{"s body "}"s structDecl is typeDecl = modifiers? "struct"s identifier "{"s body "}"s enumDecl is typeDecl = modifiers? "enum"s identifier "{"s body "}"s delegateDecl is typeDecl = modifiers? "struct"s identifier "{"s body "}"s |
You can specify the strength of binding when referring to expendable rules from the bodies of other rules. The strength of binding is specified after a colon which in turn coming after the name of the rule.
| ПРЕДУПРЕЖДЕНИЕ Warning Note taht the strength of binding can only be specified for expendinge rules. |
Using the strength of binding is convenient for describing grammars similar to the grammars of arithmetic expressions. Such grammars can be described by the rules of PEG. But the description will be more difficult as the priorities of the operators (the priorities of the operators are specified by the strength of binding of expressions in PegGrammar) will be given through a hierarchy of rules not declaratively. The associativity is impossible to express in terms of PEG (it will be determined by a code of the handler method).
The examples describe a set of extensions for expr rule:
letter = ['A'..'Z', 'a'..'z'] / '_'; digit = ['0'..'9']; identifier is expr = letter+ (letter / digit)* s; num is expr = digit + s; parentheses is expr = '('s expr ')'s; // postfix unary expressions postfixInc is expr = expr : 30 "++"s; postfixDec is expr = expr : 30 "--"s; // prefix unary expressions prefixInc is expr = "++"s expr : 30; prefixDec is expr = "--"s expr : 30; negation is expr = '-'s expr : 30; // infix binary expressions sum is expr = expr : 10 '+'s expr : 10; sub is expr = expr : 10 '-'s expr : 10; mul is expr = expr : 20 '*'s expr : 20; div is expr = expr : 20 '/'s expr : 20; listConcat is expr = expr : 5 "::"s expr : 4; // right-associative! |
Note the strength of binding is involved here. It looks like a left-recursive grammar. However there is more since precedence and associativity are given both. We define associativity as the difference between the strength of binding of the extreme left expandable rule and the extreme right one. If the difference is positive then the expression is right-associative. The operator ":: " is right-associative in the above example. If you try to recognize the following expression by the above parser:
1 :: 2 :: 3 |
then it will be interpreted as:
1 :: (2 :: 3) |
At the same time the expression:
1 + 2 + 3 |
will be recognized as:
(1 + 2) + 3 |
Associativity is not important for calculation of expressions but it is important for building AST.
To support the priorities PegGrammar combines the basic algorithm (a recursive top-down analysis with the backtracking and the partial memoization) and Top Down Operator Precedence (TDOP) algorithm. Vaughan Pratt developed TDOP algorithm. TDOP is sometimes called the Pratt-parser (by author). TDOP algorithm allows parsing expressions based on the priorities of the operators and allows left recursion.
Any expandable rule can serve as expressions in PegGrammar. TDOP assumes that its input stream consists of tokens (i.e. designed to operate with a separate lexer). That’s a problem for PegGrammar as it doesn’t use tokens. Also TDOP can’t make backtracking in case of failure when parsing another rule. This fact is not compatible with the ideology of PEG. Therefore we used the strength of binding (to control parsing of priorities and associativity of expressions) as primarily idea of the TDOP algorithm. Other details of the TDOP algorithm were changed so that it becomes compatible with the PEG parsing algorithm used in the PegGrammar.
All rules that expand some expandable rule (call it E) are split into two sets:
Recognition function of expandable rule gets the strength of binding (as input) on the right. The strength of binding is expressed in integer numbers. They are defined separated by ":" after the reference to an expandable rule. If the strength of binding for the rule is not specified then the default value is "0".
Recognition takes place in two stages:
| ПРИМЕЧАНИЕ Note Please note if during parsing of expendable rule there is a reference to the same expendable rule then recursive call of recognition function of expanding rule with the new value of the strength of binding from the right is made. That allows this algorithm to parse the complex nested expressions. |
Basically a parser gives an answer for the question whether an input string corresponds of given grammar (besides a parsing). You must specify the actions performed during parsing of certain rules of grammar to force a parser to do something more useful, for example, to form AST (an object model that describes the code) of the input line. You can solve the problem by insertion of so-called semantic actions into the grammar. This approach has some significant drawbacks. The first and most serious drawback - grammar diluted with semantic actions swells and eventually becomes the mess difficult to study. In addition, the embedded code of semantic actions is usually considered by parser generator as a text which leads to the disadvantage of creation and maintenance of a parser generator. This approach has other problems. Therefore a different approach was used in the PegGrammar macro.
Semantic actions are placed in individual methods of a class to which the metaatribut PegGrammar is applied. Such methods are called the handler methods. You can treat them as handlers of a "you parsed some grammar’s rule" event.
The name of the handler must match the name of the rule, for which it is added. Handler method is called when the parser completes the analysis of the relevant rule for some portion of the input string.
The parser regularly uses backtracking during a parsing of input string. Handler methods are called whenever relevant rule analyzed successfully. Subsequently the result of parsing rule can be discarded because of the backtracking. Thus the results of work of the handler methods can be discarded. It is very important to understand that the handler methods should not create any side-effects (to use some global state). All data (including error messages) that are used by the handler methods should be obtained through the input parameters and a result can be returned only through the method's return value or exception. Don’t put some data in the field of object-parser because data can become phantoms as a result of the backtrack rule.
| СОВЕТ Tip An exception of described rule is the use of scopes (Scope), which allow to free resources even in case of backtrack rules. You can read about domains below in the appropriate section. |
A rule for which declares the handler method should include a description of the type returned by the rule. It can be any Nemerle’s type. Handler method must have the same type of return value. If not then the compiler will give an error message.
Example of rules and corresponding handler methods (taken from the example of Calculator:):
[PegGrammar(Options = EmitDebugSources, start, grammar { any = ['\u0000'..'\uFFFF']; digit = ['0'..'9']+; spaces = ' '*; num : int = digit spaces; unaryMinus : int = '-' spaces simplExpr; ... } })] publicclass CalcParser { private num(digit : NToken, _ : NToken) : int { int.Parse(GetText(digit)) } private unaryMinus(_ : NToken, _ : NToken, se : int) : int { -se } ... } |
Each handler method must have parameters that accept information about the parsed sub-rules. The number of parameters depends on a content of the rule‘s body. If the body of rule consists of non-degenerate OrderedChoice then the handler must take exactly one parameter whose type must be compatible with the types that are returned by all elements of OrderedChoice.
simplExpr : int = num / parenthesesExpr / unaryMinus / parenthesesExprError / simplExprError; ... private simplExpr(se : int) : int { se } |
| ПРИМЕЧАНИЕ Note You may not describe these handler methods explicitly, as the PegGrammar macro simply does not call the handler of a rule whose input and output types are the same if such handler has not been described. |
Otherwise, that is if the body of rule is a degenerate case OrderedChoice (OrderedChoice with one element) then the body of rule can be regarded as a Sequence. Declare one parameter for each element of Sequence (upper level). I f the Sequence has only one element then you should declare one parameter. If the Sequence has two elements then you should declare two parameters and so on.
Types of parameters depend on the types of top-level sub-rules that form the body of rule for which we create a handler.
Types of parameters can be NToken type or user-defined type.
NToken type describes the result of parsing rule that has no handler (we don’t form any value for such rule). We may only know the position of the beginning and end of the text which was parsed by the rule and the text itself as the results of such rules.
Table 1 describes the algorithm for determining the type of the parameter depending on the type of sub-rule which is associated with this parameter.
Table 1. Types of parameters
|
Type of a rule (degenerate cases are not considered) |
Example |
Type |
Note |
|---|---|---|---|
|
Priority selection |
E1 / E2 / E3 |
T1 |
T1 is a type of first rule (E1). Types of all rules should be the same. * |
|
Sequence |
E1 E2 E3 |
T1 * T2 * T3 |
Tuple where Tn is a type of En rule (n=1,2,3). * |
|
Predicate |
!E or &E |
Parameter is not declared. |
|
|
Cycle |
E* or E+ |
SCG.List[T] ** |
T is a type described in a declaration of E rule. * |
|
Optional rule |
E? |
option[T] |
T is a type described in a declaration of rule E. * |
|
Reference to the rule |
E |
T |
T is a type described in a declaration of rule E. * |
* If E rule doesn’t have an indication of a type in its description then we use NToken type as parameter’s type. Note NToken is not used as a parameter type but it is used to specify the type of parameter as a whole. This is because we may get information only about what part of source string was parsed in accordance with rules that don’t have handler methods.
** SCG = System.Collections.Generic.
Perhaps it sounds difficult but in practice it's pretty simple. Let us consider the example given above.
For the rule
num : int = digit spaces; |
we create handler method:
private num(digit : NToken, _ : NToken) : int
{
int.Parse(GetText(digit))
} |
It has two parameters. The first parameter represents the value for the first sub-rule (“digit” that parsing a number). We use NToken type since handler method is not specified for “digit” rule. The text of parsed fragment allows getting the value of this type. In this handler the text passed to int.Parse function which converts it to an integer.
The second parameter of “num” handler method represents the value for the second sub-rule (“spaces” that parsing optional white spaces). This rule doesn’t have a handler also. We use NToken type to descripe the parameter corresponding to “spaces” rule. Since the value of white spaces is uninteresting to the problem being solved (for evaluating of the expression) this parameter is ignored. We use "_" as a name of the parameter to avoid warning about unused parameter.
For the rule
unaryMinus : int = '-' spaces simplExpr; |
we create handler method:
private unaryMinus(_ : NToken, _ : NToken, se : int) : int
{
-se
} |
It has three parameters. The first parameter represents the value for the first sub-rule (that parsing ‘-‘ literal). We can’t create a handler method for the first sub-rule since it is specified on the place (i.e. we din’t create separate named rule for it). We use NToken type as parameter type. This parameter is ignored since we are not interested in information about parsing the literal (we are interested only in a fact that the literal was parsed).
The second parameter of “unaryMinus” handler method represents the value for the second sub-rule (“spaces” that parsing optional white spaces). Its value is also ignored (I think it is not necessary to explain that the type of this parameter should be NToken).
The third parameter (se) corresponds to “simplExpr” sub-rule. The type of this parameter must be “int” since we specified the handler method for the rule that returns a value of type “int”.
“unaryMinus” handler method simply inverts the sign of this value and returns it as the result.
You may give “void” type for a rule. In this case PegGrammar always ignore return value of such a rule. The fact allows reducing the amount of unused parameters in the handler methods (i.e. generated parser will work faster).
For example, the code above can be changed as follows:
[PegGrammar(Options = EmitDebugSources, start, grammar { any = ['\u0000'..'\uFFFF']; digit = ['0'..'9']+; spaces : void = ' '*; num : int = digit spaces; unaryMinus : int = '-' spaces simplExpr; ... } })] publicclass CalcParser { private num(digit : NToken) : int { int.Parse(GetText(digit)) } private unaryMinus(_minus : NToken, se : int) : int { -se } ... } |
As you can see an indication of a void for “spaces” rule will get rid of parameters which previously required specifying this rule.
If sub-rule defines a cycle (E * or E+) you should use System.Collections.Generic.List [T] type to describe the relevant parameter. The “T” type of parameter must have a value that matches the type of E rule. If E rule does not specify a type then parameter’s type must be NToken (note that NToken should not be used to define “T” type of a parameter but instead of System.Collections.Generic.List [T]). If the body of the loop is a sequence of sub-rules (Sequence) then use a tuple to describe the type. The types of elements of a tuple should correspond the types of sub-rules that make up the body of the loop.
Example.
mulOrDiv : int = simplExpr (('*' / '/') spaces simplExpr)*; ... private mulOrDiv(se : int, lst : List[NToken * NToken * int]) : int { ... } |
Please note if the type of “spaces” rule is void then a tuple will consist of two elements (NToken * int) rather than three elements.
If sub-rule is optional (E?) then its type must be "wrapped" in option[T] type. A value of T type is determined by the above rules.
Example.
mainRule : int = sumOrSub inputError?; ... private mainRule(se : int, _ : option[int]) : int { se } |
| СОВЕТ Tip At the time of code generation PegGrammar checks a presence of handler methods. PegGrammar also checks types of parameters of handler methods. If they differ from the expected types then PegGrammar reports an error. In this report PegGrammar describes the expected signature of the handler method. Checks are carried out for the rules which specify the return value. To make it easier to create a handler method you can set the return values of rules for which you want to create a handler methods and start the compilation. Next you need to find an error message saying that the rules don’t specify the handler method (or if incorrect) and take a correct signature. After that you will specify reasonable names of the parameters and begin to implement handlers. |
You don’t need to set the parameters for predicates since they do not return values. Predicates never change the position of the parse of a string. They answer the question of whether (or may not, for the predicate "!") be parsed a rule at the current position. In principle one can always write a grammar without the use of predicates, but often the use of predicates makes grammar simpler.
For example, the predicates are useful for recognition of comments in C:
delimitedComment = "/*" (!"*/" any)* "*/"; |
This rule recognizes the "/*" string and then zero or more characters but only if this character does not start the "*/" sequence (that is specified by !"*/" predicate). If you don’t place !"*/" predicate before a reference to the “any” rule then it would parse any character including "*" followed by "/". This rule would not "notice" the end of the comment and would not stop until it reached the end of the file. Predicate "!" indicates a failure if the rule which follow the "!" predicate is successfully mapped. This leads to the fact that when we meet the sequence “*/” at the current position then the execution of the rule “(!"*/" any)” fails which leads to stopping of the cycle (described by the rule “*”). Further we recognize "*/" string that leads to the successful parsing of “delimitedComment” rule.
Parsing identifiers is another example of where predicates help. For example the next rule parses an identifier in C #:
identifier : Identifier = !keyword "@"? identifierBody s; |
Predicate “!keyword” is needed since any keyword also satisfies the rules of identifier’s parsing. Predicate prevents parsing of keywords in accordance with identifier’s rule.
The “keyword” rule must also contain a predicate:
keyword = ("abstract" / "as" / "base" / "bool" / "break" / "byte" / "case" / "catch" / "char" / "checked" / "class" / "const" / "continue" / "decimal" / "default" / "delegate" / "do" / "double" / "else" / "enum" / "event" / "explicit" / "extern" / "false" / "finally" / "fixed" / "float" / "for" / "foreach" / "goto" / "if" / "implicit" / "in" / "int" / "interface" / "internal" / "is" / "lock" / "long" / "namespace" / "new" / "null" / "object" / "operator" / "out" / "override" / "params" / "private" / "protected" / "public" / "readonly" / "ref" / "return" / "sbyte" / "sealed" / "short" / "sizeof" / "stackalloc" / "static" / "string" / "struct" / "switch" / "this" / "throw" / "true" / "try" / "typeof" / "uint" / "ulong" / "unchecked" / "unsafe" / "ushort" / "using" / "virtual" / "void" / "volatile" / "while" ) !identifierPartCharacters; |
You can meet an identifier like abstractFactory (i.e. containing the name of one of the keywords as prefix) in the code. Enter a predicate in the “keyword”rule to prevent the parser to recognize the prefix as a keyword. Such predicate will verify that the keyword will not follow a symbol that can be used in the body of the identifier.
The PEG is not suitable for recognition grammars which can’t generally be described using context-free grammars. For example, to understand whether a certain expression in C++ is a declaration of a variable you need to know a type of an identifier. C++ (as its predecessor C) requires that all types have been declared before the use. This can be done by physical placement of types (or typedef) before using them or by a description of declaration (for example, “class A;”) before the first use of types. Thus to analyze the primitive C++ construct (like “X Y();”) we need to know what types have been declared before such construct.
To solve this problem in the normal parser (written by recursive descent parser without backtracking) we can create a list of declared types which will be supplemented with the parsing of the description of some type and cleared when we leave a scope that describes the types.
The backtracking (so inherent for the PEG) doesn’t allow doing the same in the handler methods of the rules. Backtracking may terminate recognition of certain rule of grammar (e.g. a namespace whose bodies are scopes for types) and begin to recognize the other rules.
Scopes allow you to specify a region containing a number of consecutive rules. Handler methods will be invoked when we begin the recognition of this area. When we begin the completion of its recognition handler methods will be invoked also. It’s very important that the notification of termination of scope’s recognition comes either in the case of successful recognition of the rule as whole or in case of a backtracking.
In the case of parsing C++, for example, it allows us to define the scope of the namespace. This will allow creating handler methods that will announce the beginning of the recognition of the namespace and the end of its recognition. You can save a list of available types In the first handler method and restore the previous value in the second handler method. The second handler method will be invoked even in the case of a backtracking of a rule.
Similarly for the recognition of Nemerle’s files we need to collect information about available syntactic extensions that can be loaded by “using” directive. This directive can be placed at the beginning of any namespace. Scopes can make it very simple and elegant.
You must specify a unique (within the parser) name for each scope. In addition it is necessary to declare a handler method for notification of the beginning of the scope’s recognition and/or handler method for notification of the end of the scope’s recognition.
The first must have the signature:
SomeScopeBegin() : void |
or
SomeScopeBegin() : bool |
The second must have the signature:
SomeScopeEnd(isOk : bool) : void |
or
SomeScopeEnd(isOk : bool) : bool |
If the handler method has a return value of bool type then it will be able to influence the recognition process. If you return from a handler method false then the current rule will be backtracked even if otherwise it could be successfully matched with the text.
“isOk” parameter allows you to determine whether a call of a handler method is performed as a result of a backtracking or in normal mode.
Specialty of this implementation is that the parsed line should be loaded into memory (to be presented in the form of System.String type). This requirement arose from the fact that the PEG supports backtracking (due to the use of operators of the priority selection) and an unlimited lookaheads (through the use of predicates). This leads to the fact that the most effective ways of working with a string is an indexation (or the use of pointers if a language’s implementation supports them). A position (in the parser generated by PegGrammar) is defined by an integer (int). A backtracking changes this number. The same number determines that the parsing of a rule is failed (a value is negative (equal to -1)). Using just one number (to describe the position and to identify the success or failure of parsing) makes the parser so quick.
However there is the side effect of this decision. Before parsing the text must be completely loaded into memory.
This limitation is usually not a problem for modern computers since the volume of memory is much larger than parsed data. But somewhere on the phone or in a built-in solution such decision may be unacceptable. In addition this limitation doesn’t allow you to parse potentially unbounded data structures (for example, information from the TCP-IP sockets).
The PEG actually describes a top-down recursive parser with backtracking. This type of parsers has one limitation. Without any special refinement (negatively affecting productivity and greatly complicates the parser) parsers of this type can’t work with left-recursive grammars. Left-recursive grammar is called a grammar which has left-recursive rules (direct or not). For example, this grammar is left recursive:
X = X '+' 1 / 1 |
A parser (built using PegGrammar) when find the reference to rule X will always call parsing function of X rule. That will lead to an infinite loop or a stack overflow. Thus it is necessary to avoid left recursion. The PegGrammar checks a grammar for the presence of left-recursion (both direct and indirect) and issues the appropriate error message.
Any left-recursive rule can be rewritten without left recursion. This fact is scientifically proven. For example, the above rule can be rewritten as:
X = 1 ('+' 1)* |
This is a common pattern to transform left-recursive rules into iterative rules. Additionally you may use a classic approach (an introduction of the intermediate rule) but in fact it doesn’n make any difference.
| СОВЕТ Tip The PegGrammar supports the strength of binding (priorities) for extpensable rules. Priorities allow us to describe left-recursive rules. Left recursion is especially useful when creating rules for the description of expressions. This issue is described in more details in the sections “Expandable rule”, “Expanding rule”, “Strength of binding”. |
As mentioned above in fact PegGrammar generates a classic top-down recursive parser with backtracking. Backtracking could lead to an exponential increase of parsing time. In reality we get an exponential increase of parsing time rarely. But you can still get a very significant slowdown of a parser if not to make a left factorization of rules.
We know from school’s algebra that expression:
3 * x + 3 * y |
can be rewritten as:
3 * (x + y) |
Much the same can be done with the grammar‘s rules. Instead of:
A = X Y / X Z |
we can write:
A = X (Y / Z) |
These rules will be dealt with the same grammar but in the second case the rule X will be parsed only once.
In fact the rules shown above will be memoized as PegGrammar supports a memoization for the last use of the rule. But in more complex cases (e.g. in the case of grammar “XXY / XXZ”) we may get backtracking which could lead to a degradation of a performance.
Remember also the left-factorization can negatavely affect product’s quality (grammar). So don’t get involved in it without a special need. A profiler will help to identify bottlenecks of a parser. Consider the use of the left factorization when the profiler will show that some of the rules are processed too slowly compared to others.
Today PegGrammar supports a pretty decent set of optimizations. The main optimization is inlining of grammar’s rules. This leads to an increase of the amount of code but results in a noticeable acceleration of parsing by removing the method calls.
In addition the PegGrammar generates pretty good (in terms of performance) code. The code essentially consists of statements “if” and assignment (assigning the position of the parsing to an integer variable). There are no closures, classes and other higher-level widgets in the generated code. A release version uses “goto” instead of the structural conditional statements. All this positively affects the performance of the parser.
The memoization of results of parsing rules for the same position in the source code allows avoiding repeating parsing of the same rules. For example, if you are parsing C# - like programming language you may have similar rules:
classRule = customAttribut? modifiers? "class"S ...; structRule = customAttribut? modifiers? "struct"S ...; enumRule = customAttribut? modifiers? "enum"S ...; method = customAttribut? modifiers? ...; property = customAttribut? modifiers? ...; cmassMember = classRule / structRule / enumRule / method / property; |
you don’t need to make a left factorization of these rules and create something like
cmassMember = customAttribut? modifiers? ("class"S / "struct"S / "enum"S / ...) ... |
Thanks to the memoization of last position for each rule the result of parsing for “customAttribut” and modifiers will be stored in special variables (a parser has one field for each rule). These rules will be parsed in the same position all the time. That’s why we’ll use the already available results when re-parsing the rules.
| ПРИМЕЧАНИЕ Note In theory the total memoization gives a linear speed of parsing according to the Packrat algorithm. Our experiments showed the total memoization is not applicable in a practice. The Packrat leads to high costs of the memoization and an inspection of memoized state. The amount of memory required for the state’s memorization is the product of the number of grammar’s rules, length of parsing string and the size of the data structures used for the memoization. The “Rats!” parser’s generator showed the most powerful optimizations were those that eliminated unnecessary memoization and reduces the volume of memoization’s table with which the algorithm works in certain moments. It turned out that the speed of parsing in real grammars (we used C#4.0 grammar for testing) is significantly reduced if you will use an approach similar to the Packrat. On the other hand memoization for the last position (where we attempting to parse the rule) gave improved performance and allowed to avoid a left factorization in most cases. |
PegGrammar also optimize code generation for a number of combinations of terminal rules (i.e. rules that don’t have a handler method returning a result and rules that aren’t non-recursive). Such combinations reduce and speed up the final code.
Deterministic finite automata (DFAs) are generated for terminal rules. That also helps to increase a parsing speed.
Compiling a parser in “Release” mode makes the beneficial effect also (due inlining techniques and other optimizations made .NET jit-compiler).
Each optimization doesn’t give the global acceleration. But ultimately a speed of parsing is accelerated to about ten times compared with the debug version (where almost no optimization is done). This leads to the fact that the resulting parser is almost as good as a parser written by hand.
We'd like to hear any suggestions and comments on ideas for optimizing the performance of parsers generated by the PegGrammar as, indeed, any others.
The PegGrammar is a very young product. So it's no wonder that not everything still works as desired in it. Here is a list of known issues that will eventually be eliminated:
These flaws are not so difficult to eliminate (except the last paragraph). Just before the publication of this article I had to remove several items from this list since the corresponding defects were eliminated in the PegGrammar.
The remaining shortcomings are not eliminated because appropriate facilities were not in demand in practice. We may easy to obtain sophisticated support of things that are not used in a real practice.
In addition a way that the PegGrammar was implemented (as a macro Nemerle) can be concidered as a shortcoming. But, first, it is a shortcoming only for those who don’t accept Nemerle for whatever reason. And secondly, the resulting parser can be used from any .NET-language. That makes its use not worse than the use of any builder of parsers with generation of a code (for example, ANTLR).
Today the PegGrammar allows describing left recursion grammars for expandable rules. It is not full support for left recursion. But this feature covers most of the cases when the left recursion is convenient for describing the grammar. There is a hope the PegGrammar will fully support left recursion in the near future.
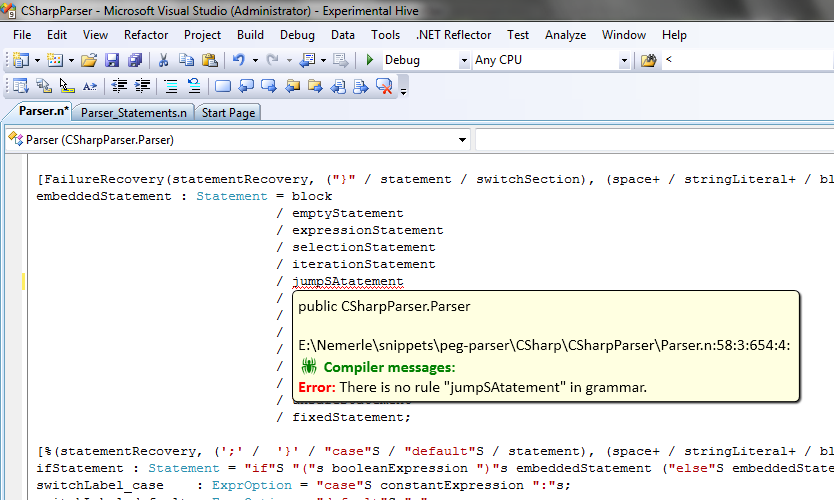
Figure 1. The reflection of grammar’s errors during editing session (in real time).
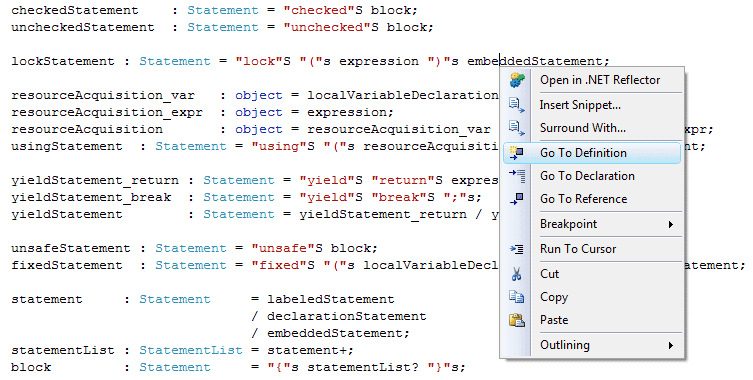
Figure 2. A branch to the rule’s definition or to the handler method.
Here there is a list of known advanteges.