 Оценка 0
Оценка 0 
 Оценить
Оценить 





| Оценка 0 Оценить
|
| Введение Платформа WEKA. Общее описание Постановка задачи и структура исходных данных Структура платформы и обзор необходимых изменений структуры Результаты и выводы. Список литературы |  |
В настоящее время всё чаще возникает задача автоматического анализа информации, что связано, в первую очередь, с резким ростом объема информации и отчетных данных, требующих обработки. Большая часть анализируемой информации является объектами, характеризующимися набором параметров, и легко представляется в реляционном виде. Однако некоторые данные имеют более сложную структуру, что серьезно затрудняет анализ программными средствами, но не отменяет его необходимость. Примером таких данных является цепочка событий или объектов, например, история посещения пользователем интернет-сайта, последовательность услуг, оказанных пациенту в медицинской организации, и пр.
Существует достаточное количество аналитических средств, но большинство из них не предоставляют возможность работы со сложноструктурированными данными. Наиболее распространенные пакеты работают с простыми реляционными схемами (например, схема «звезда») и лишь некоторые пакеты анализа данных предоставляют возможность проводить обработку данных более сложной структуры. Например, Microsoft Analysis Services, начиная с версии 2005, позволяет проводить кластеризацию цепочек с помощью алгоритма кластеризации Microsoft Sequence Clustering [6]. Но даже при наличии необходимых алгоритмов в пакете анализа данных, гибкости для решения узкоспециализированных задач может быть недостаточно [2].
Таким образом, в случае, если данные из-за сложности собственной структуры не могут быть обработаны стандартными пакетами анализа данных, возникает потребность в разработке собственного программного обеспечения, рассчитанного на решение узкоспециализированных задач. В работе будет рассмотрен получивший широкое распространение пакет информационного анализа WEKA.
В платформе WEKA не предусмотрена возможность загрузки и обработки данных со сложной структурой. В связи с этим мы попытались доработать и создать несколько классов платформы так, чтобы пользователь мог загружать и обрабатывать сложноструктурированные данные.
В статье мы постараемся изложить основные преимущества и недостатки использования платформы WEKA в качестве базы для разработки собственного программного обеспечения.
Платформа WEKA (Waikato Environment for Knowledge Analysis) была разработана в 1993 году в университете Уайкато (Новая Зеландия) и является широкоизвестной, свободно распространяемой системой анализа данных, написанной на языке Java.
WEKA включает в себя библиотеку алгоритмов машинного обучения для решения задач интеллектуального анализа данных (Data Mining), позволяет непосредственно применять алгоритмы к выборкам данных, а также вызывать алгоритмы из программ на языке Java.
Целью проекта являлось создание современной среды разработки средств машинного обучения и применения их к реальным данным, создание доступных для повсеместного применения средств машинного обучения. Предполагается, что с помощью данной среды специалист в прикладной области сможет использовать методы машинного обучения для извлечения полезных знаний непосредственно из данных, возможно, очень большого объёма. Пользователями WEKA являются исследователи в области машинного обучения и прикладных наук. Она также широко используется в учебных целях.
Платформа WEKA может быть использована как для применения встроенных (реализованных создателями платформы), так и для реализации иных алгоритмов. Основными возможностями платформы являются: предобработка данных (Data preprocessing), классификация, кластеризация, выбор атрибутов данных, визуализация данных. Помимо этого WEKA поддерживает поиск ассоциативных правил, формирование наборов исходных данных, средства автоматической документации исходного кода, алгоритм EDA[3,7].
Важной особенностью платформы является возможность доступа к классам, реализующим описанную выше функциональность, из любой программы, написанной на языке JAVA. Это позволяет внедрять элементы платформы в собственные разработки. По данным официального сайта WEKA на сегодняшний момент существует уже 50 проектов, расширяющих или использующих функциональность платформы (YALE, FastKMeans, FAEHIM и др.) [5].
Для более детального анализа мы решили ограничить задачу разработкой модуля загрузки исходных данных и модуля, отвечающего за кластеризацию данных. Мы ожидаем, что в результате изменений в коде программа будет загружать, обрабатывать и проводить кластеризацию на данных со сложной структурой. В качестве алгоритма кластеризации будет использоваться алгоритм k-средних, а в качестве меры близости – расстояние Левенштейна[1]. При этом должна быть оставлена возможность изменения меры близости независимо от алгоритма кластеризации и добавления атрибутов к исходным данным (без принципиального изменения их структуры).
Структура данных, обработка которых являлась основной целью разработанных классов, представлена на рис. 1. Таблица цепочек содержит в себе список посещений врачей пациентами, а таблица услуг – порядок оказанных врачом услуг в данное посещение.
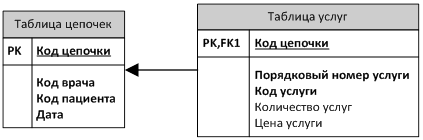
Рис. 1. Схема исходных данных
Ниже описываются основные классы существующей системы, связанные с загрузкой, обработкой и кластеризацией данных, произведенные изменения в этих классах, а также приводятся структурные схемы (точка зрения реализации) исходных и разработанных классов платформы.
На рис. 2 приведена часть структурной схемы классов платформы WEKA, связанных с процессом загрузки данных и кластеризации. Приведение полной схемы представляется избыточным в связи с локальностью задачи.
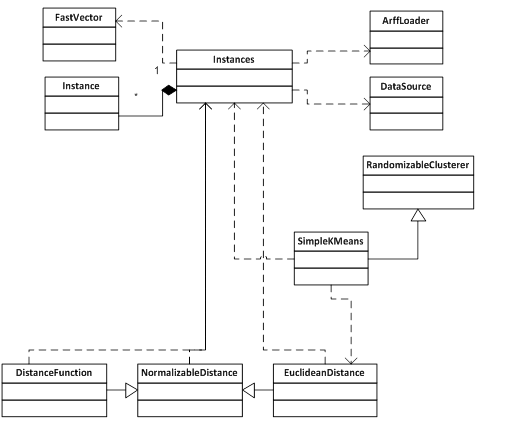
Рис. 2. Фрагмент структурной схемы платформы WEKA
За загрузку данных отвечают классы ArffLoader, DataSource и Instances (из которого и происходит вызов методов, содержащихся в ArffLoader и DataSource). Класс Instances представляет собой класс-контейнер для класса Instance. Каждый объект класса Instance представляет собой один объект из загрузки с некоторым набором параметров[4]. Помимо этого, класс Instances содержит:
За процесс кластеризации методом k-means отвечает класс SimpleKMeans. Особое внимание следует обратить на тесную связь класса SimpleKMeans с классом Instances, что вызвано зависимостью процесса кластеризации от структуры данных. На рис. 2 видно, что класс SimpleKMeans использует в своей работе класс Instances.
При проведении кластеризации используется выделенная в отдельный класс мера близости между объектами (на диаграмме – EuclidianDistance и общий для всех мер класс – normalizableDistance). Мера близости, также как и алгоритм кластеризации, использует класс Instances.
Учитывая неразрывность структуры данных и алгоритма кластеризации, при создании класса кластеризации цепочек-графов возникла необходимость не только написания самого алгоритма, но и разработки класса-контейнера для цепочек-графов, а также класса, описывающего меру близости.
Первым этапом разработки было создание структуры для хранения данных. В работе класс, реализующий хранение и доступ к элементам цепочек получил название VectorOfInstances. Формальное описание структуры данных было приведено выше. С точки зрения используемых в платформе WEKA классов такая структура могла бы быть определена как вектор элементов типа Instances. Каждый элемент такого вектора – элемент типа Instances – представляет собой цепочку, а объект класса VectorOfInstances содержит в себе весь набор данных, разбитых на цепочки.
Большинство методов, агрегирующих различные показатели, не могут быть унаследованы от класса Instances. Определение таких статистических понятий, как мода и среднее, для данных рассматриваемой структуры зависит от поставленных задач и может реализовываться различным образом, но не может быть унаследовано от уже существующих в платформе классов.
Также претерпевает изменение процесс загрузки данных. В текущей реализации платформы все данные из файла (или из другого источника) считываются в единый набор данных (этот набор содержится в объекте класса Instances). При решении рассматриваемой задачи мы сталкиваемся с двумя проблемами:
Для решения первой проблемы исходные данные были представлены в одном файле в виде денормализованной таблицы, объединившей таблицу цепочек и таблицу услуг, изображенных на рис. 1. Это позволило избежать внесения существенных и сложных изменений в базовые классы платформы.

Рис. 3. Единая таблица исходных данных
Решение второй проблемы потребовало модификации процесса загрузки данных. Корректировка алгоритма загрузки заключалась в определении начала и конца загружаемой цепочки, и выделения этой цепочки в отдельный объект типа Instances. Сам метод загрузки данных был вынесен в класс VectorOfInstances.
Создание новой структуры для хранения данных неизбежно повлекло за собой создание класса, отвечающего за меру близости, подходящую для данной структуры. Для этой цели был разработан класс, обеспечивающий вычисление меры Левенштейна, с предусмотренной возможностью расширения меры, в зависимости от количества параметров элемента цепочки. В платформе такой алгоритм не был разработан, т.к. в WEKA не предусмотрена работа с соответствующей структурой данных.
Как было указано на рис. 2, в платформе за определение расстояния между объектами отвечают сразу три класса: NormalizableDistance, DistanceFunction и класс непосредственно используемой меры близости (в данном примере – EuclidianDistance). Разделение функциональности, упрощающее создание новых мер близости для данных традиционной структуры, значительно усложняет процесс разработки новых мер близости для данных иной структуры. При этом все базовые методы содержатся в классе NormalizableDistance. В базовом классе DistanceFunction содержатся абстрактные методы distance, Instances, setInstances, которые принимают параметры типа Instance (т.е. жестко привязаны к структуре исходных данных).
При создании класса, реализующего сравнение объектов между собой по алгоритму Левенштейна, разработчику приходится значительно изменять класс NormalizableDistance. В связи со сложностью создания «универсального» класса было принято решение создать ещё один (схожий, но не совпадающий по функциональности) класс NormalizableDistanceForChains.
В класс DistanceFunction внесены небольшие изменения, связанные с абстрактными методами distance, Instances и setInstances, которые принимают параметры Instance (т.е. не могут быть использованы для данных с рассматриваемой структурой). В класс были добавлены перегруженные методы, принимающие, помимо параметров типа Instance, параметры типа Instances.
Помимо изменения структуры хранения и доступа к данным было необходимо изменить класс, отвечающий за кластеризацию с помощью алгоритма k-means (SimpleKMeans). Этот класс претерпел незначительные изменения: часть методов, напрямую задействовавших свойства классов Instance и Instances, была скорректирована для работы со сложной структурой.
Основные изменения в классе SimpleKMeans коснулись метода расчета характеристик образованных кластеров (в том числе центроида кластера), который производился с помощью методов класса Instances и, в связи с изменением структуры данных, требовал изменений.
На рис.4 представлена итоговая структурная схема, разработанных в ходе исследования классов.
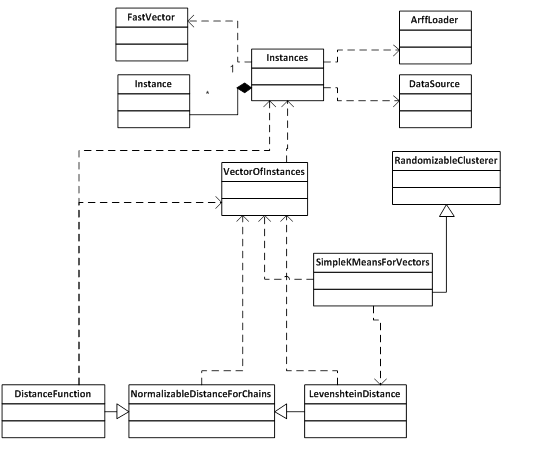
Рис. 4. Структурная схема модифицированной части платформы WEKA
Платформа WEKA, её структура и организация классов, позволяет легко вносить изменения в исходный код и менять используемые алгоритмы, если нет необходимости в изменении структуры данных. Это возможно благодаря грамотному распределению функциональности по различным классам и продуманной системе взаимодействия классов между собой:
Однако внесение более сложных изменений (например, рассмотренное в статье изменение исходной структуры данных) требует значительно больших временных затрат и требует более высокой квалификации разработчика. Это вызвано, в первую очередь, большим количеством классов, напрямую использующих свойства классов Instance и Instances, что при изменении структуры данных приводит к необходимости их модифицировать (в той или иной степени). Для проведения кластеризации данных со сложной структурой необходимо изменить и создать 6 классов. Если задачу расширить до полной функциональности платформы (загрузка, кластеризация, классификация данных; визуализация результатов; пользовательский интерфейс), то изменений потребует большая часть классов платформы.
На сегодняшний день сложно представить себе решение проблемы взаимосвязи алгоритма и структуры данных, т.к. метрики расстояния между объектами (а часто и сами алгоритмы кластеризации) зависят от данных, их полноты, структуры и природы. Поэтому, как нам кажется, решение описанных выше проблем, лежит в области разработки более гибкой связи между классами, содержащими информацию, и классами, отвечающими за их обработку.
| Оценка 0 Оценить
|