 Оценка 755
Оценка 755 
 Оценить
Оценить 





| Оценка 755 Оценить
|
Компонентные системы стали своего рода "святым Граалем" программной индустрии. В идеале, программное обеспечение должно собираться из библиотек предварительно написанных компонентов, так же, как аппаратура собирается из предварительно изготовленных чипов. На самом же деле большие куски приложений пишутся "с нуля", так что разработка ПО – это все еще больше ремесло, чем индустрия.
Компоненты в этом смысле – простые части ПО, так или иначе используемые более крупными частями или целыми приложениями. Компоненты могут выглядеть по разному. Это могут быть модули, классы, библиотеки, фреймворки, процессы или, например, Web-сервисы. Их размер может составлять от нескольких строк до нескольких тысяч. Они могут быть связаны с другими компонентами разнообразными механизмами – такими, как агрегирование, параметризация, наследование, удаленный вызов или передача сообщений.
Мы считаем, что, по крайней мере, частично отсутствие прогресса в компонентном ПО объясняется недостатками языков программирования, используемых для определения и интеграции компонентов. Большинство существующих языков предлагает только ограниченную поддержку абстрагирования и композиции компонентов. Это относится, в частности, к таким статически типизированным языкам, как Java и C#, которые широко используются при создании компонентного ПО.
Язык Scala был создан в 2001-2004 гг в лаборатории методов программирования EPFL. Он стал результатом исследований, направленных на разработку более хорошей языковой поддержки компонентного ПО. С помощью Scala мы хотели бы проверить две гипотезы. Во-первых, мы считаем, что язык программирования компонентного ПО должен быть масштабируемым в том смысле, что должна быть возможность с помощью одних и тех же концепций описать как маленькие, так и большие части. Поэтому мы сконцентрировались на механизмах абстракции, композиции и декомпозиции вместо введения большого количества примитивов, которые могут быть полезными только на каком-то одном уровне масштабирования. Во-вторых, мы считаем, что масштабируемая поддержка компонентов может быть предоставлена языком программирования, унифицирующим и обобщающим объектно-ориентированное и функциональное программирование. Некоторые из основных технических новшеств Scala – это концепции, представляющие собой сплав этих парадигм программирования. В статически типизированных языках, к которым относится Scala, эти парадигмы до сих пор были почти полностью разделены.
Чтобы проверить наши гипотезы, необходимо применить Scala’у при разработке компонентов и компонентных систем. Только серьезное использование языка сообществом разработчиков может сказать, помогают ли заключенные в языке концепции при разработке компонентного ПО. Чтобы облегчить восприятие нового языка пользователями, он должен хорошо интегрироваться с существующими платформами и компонентами. Scala разрабатывалась в расчете на совместную работу с C# и Java. Она позаимствовала у этих языков значительную часть синтаксиса и системы типов. Но в то же время, иногда прогресс требует отбросить некоторые существующие соглашения. Поэтому Scala – это не расширенный вариант любого из этих языков. Некоторые возможности отсутствуют, другие же переосмыслены для улучшения согласованности концепций.
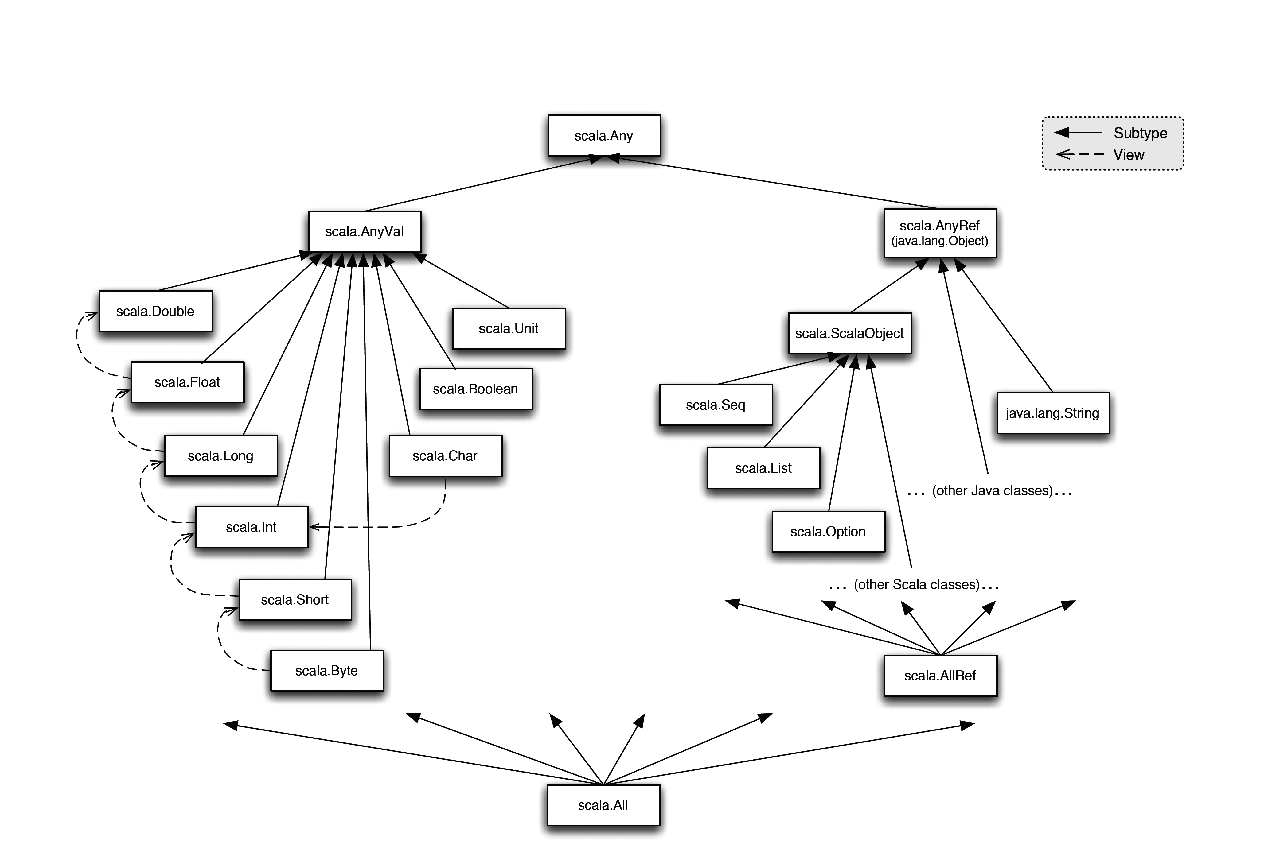
Рисунок 1. Иерархия классов Scala.
Остаток статьи посвящен обзору Scala. В нем рассматриваются следующие ключевые аспекты языка:
// Java class PrintOptions { public static void main(String[] args) { System.out.println("Options selected:"); for (int i = 0; i < args.length; i++) if (args[i].startsWith("")) System.out.println(" " + args[i].substring(1)); } } // Scala object PrintOptions { def main(args: Array[String]) : unit = { System.out.println("Options selected:"); for (val arg <- args) if (arg.startsWith("-")) System.out.println(" "+arg.substring(1)); } } |
Scala рассчитана на взаимодействие с такими ведущими платформами, как Java или C#. Она разделяет с этими языками большинство основных операторов, типов данных и управляющих структур.
Для простоты в дальнейшем мы будем сравнивать Scala только с Java. Но, поскольку Java и C#, в свою очередь, имеют много общего, сходство с Java распространяется и на C#. В чем-то Scala даже ближе к C#, чем к Java. Например, в трактовке обобщенности (genericity).
В листинге 1 приведен пример простой программы на Java и Scala. Программа распечатывает все опции, введенные в командной строке. Примеры очень похожи. Оба языка используют один и тот же класс-примитив String, вызывающий одни и те же методы. Они также используют одинаковые операторы и одинаковые условные управляющие конструкции. Пример показывает и некоторые различия между языками:
| ПРИМЕЧАНИЕ Работа с массивами подробно рассматривается в соответствующем разделе статьи |
Несмотря на различия в синтаксисе, Scala-программы могут без проблем взаимодействовать с Java-программами. В приведенном примере, Scala-программа вызывает методы startsWith и substring класса String, определенного на Java. В ней также происходит обращение к статическому полю out Java-класса System и вызов его (перегруженного) метода println. Это возможно даже несмотря на то, что в Scala нет концепции статических членов класса. На самом деле каждый Java-класс представляется в Scala как две сущности – класс, содержащий все динамические члены, и singleton-объект, содержащий все статические члены. Таким образом, System.out в Scala доступен как член объекта System.
Хотя это и не показано в приведенном выше примере, классы и объекты в Scala могут наследовать от Java-классов и реализовать Java-интерфейсы. Это позволяет использовать Scala-код во фреймворке Java. Например, Scala-класс мог бы реализовывать интерфейс java.util.EventListener. Экземпляры этого класса затем можно оповещать о событиях, поступающих от Java-кода.
В Scala используется чистая объектно-ориентированная модель, похожая на применяемую в Smalltalk: каждое значение – это объект, и каждая операция – это отправка сообщения.
На рисунке 1 показана иерархия классов Scala. Каждый класс Scala унаследован от класса Scala.Any. Подклассы Any попадают в одну из двух категорий: классы-значения, наследуемые от scala.AnyVal, и ссылочные классы, наследуемые от scala.AnyRef. Любое имя примитивного Java-типа соответствует классу-значению, и отображается на него с помощью предварительно определенного псевдонима типа. В Java AnyRef отождествляется с корневым классом java.lang.Object. Экземпляр ссылочного класса обычно реализуется как указатель на объект, хранящийся в куче программы. Экземпляр класса-значения обычно представляется напрямую, без указателей-посредников. Иногда приходится конвертировать два представления, например, когда экземпляр класса-значения виден как экземпляр корневого класса Any. Эти boxing-преобразования (и обратные им) выполняются автоматически, без явного указания в коде.
Обратите внимание, что классы-значения являются плоскими (одноуровневыми); все классы-значения – это подтипы scala.AnyVal, но не подтипы друг друга. Вместо этого используются представления (т.е. стандартные приведения, см. ниже) элементов различных классов-значений. Мы рассматривали альтернативу в виде создания подтипов классов-значений. Например, можно было бы сделать Int подтипом Float, вместо создания стандартного приведения от Int к Float. Мы отказались от этого, поскольку хотели сохранить как инвариант то, что интерпретация значения подкласса как экземпляра его суперкласса не меняет представления значения. Кроме всего прочего, мы хотим гарантировать, что для каждой пары типов S<:T и каждого экземпляра x типа S выполнено следующее равенство:
x.asInstanceOf[T].asInstanceOf[S] = x |
| ПРИМЕЧАНИЕ asInstanceOf – стандартное "приведение типов" в Scala, определенное в корневом классе Any. |
Внизу иерархии типов лежат два класса – scala.AllRef и scala.All. Тип AllRef – это подтип всех ссылочных типов; его единственный экземпляр – ссылка на null. Поскольку AllRef не является подтипом типов-значений, null не является членом любого такого типа. Например, невозможно присвоить null переменной типа int.
Тип All – это подтип любого другого типа; экземпляров этого типа не бывает. Несмотря на то, что тип All – пустой, он может быть полезен в качестве параметра типа. Например, в библиотеке Scala определено значение Nil типа List[All]. Поскольку списки в Scala ковариантны, это делает Nil экземпляром List[T] при любом типе элементов T.
Операция равенства значений (==) разрабатывалась так, чтобы быть прозрачной в отношении представления типов. Для типов-значений это обычное (числовое или булево) равенство. Для ссылочных типов == расценивается как псевдоним метода equals из java.lang.Object. Этот метод изначально определяет равенство как равенство ссылок и должен переопределяться в подклассах, чтобы реализовать естественное понятие равенства для этих подклассов. Например, boxed-версии типов-значений могли бы реализовать метод equals как сравнение boxed-значений. В Java, наоборот, == всегда означает равенство ссылок для ссылочных типов. Это реализуется несколько эффективнее, но создает проблемы связности, поскольку boxed-версии равных значений могут оказаться неравными (относительно ==).
В некоторых ситуациях нужно не определяемое пользователем, а ссылочное равенство. Примером может быть хеш-консолидация, где эффективность – это все. Для таких случаев класс AnyRef определяет дополнительный не переопределяемый метод eq, реализующий ссылочное равенство (т.е. он ведет себя как == в Java для ссылочных типов).
Еще один аспект унифицированной объектной модели Scala – каждая операция является отправкой сообщения, то есть, вызовом метода. Например, сложение x+y интерпретируется как x.+(y), т.е. как вызов метода + с x в качестве объекта-приемника и y в качестве аргумента метода. Эта идея, впервые реализованная в Smalltalk, адаптирована к более традиционному синтаксису Scala следующим образом. Во-первых, Scala рассматривает имена операторов как обычные идентификаторы. Точнее, идентификатор – это либо последовательность букв и цифр, начинающаяся с буквы, либо последовательность операторных символов. Таким образом, можно определять, например, методы с именами +, <= или :: Далее, Scala трактует идентификатор, находящийся между двумя выражениями, как вызов метода. Например, в листинге 1 можно было бы использовать синтаксис операторов (arg startsWith"-") как "синтаксический сахар" для более традиционного синтаксиса (arg.startsWith("-")).
В качестве примера объявления и применения операторов, определяемых пользователем, рассмотрим следующую реализацию класса Nat для натуральных чисел. Этот класс (очень неэффективно) представляет числа как экземпляры двух классов – Zero и Succ. Число N будет представлено как new SuccN(Zero). Начнем реализацию с trait-а, определяющего интерфейс натуральных чисел. Пока будем рассматривать trait-ы как абстрактные классы, ниже о них будет сказано подробнее. Согласно определению trait-а Nat, натуральные числа предоставляют два абстрактных метода, isZero и pred, и три обычных метода succ, + и -.
trait Nat { def isZero: boolean; def pred: Nat; def succ: Nat = newSucc(this); def +(x: Nat) : Nat = if (x.isZero) this else succ + x.pred; def -(x: Nat) : Nat = if (x.isZero) this else predx.pred; } |
Заметьте, что Scala позволяет определять методы без параметров, такие, как isZero, pred и succ в классе Nat. Такие методы вызываются каждый раз, когда выбрано их имя, никакого списка аргументов не передается. Заметьте также, что члены абстрактного класса идентифицируются синтаксически, поскольку у них нет определения. Дополнительный модификатор abstract не требуется.
Теперь расширим trait Nat singleton-объектом Zero и классом, представляющим последующие элементы, Succ.
object Zero extends Nat { def isZero: boolean = true; def pred: Nat = throw new Error("Zero.pred"); } class Succ(n: Nat) extends Nat { def isZero: boolean = false; def pred: Nat = n; } |
Класс Succ показывает разницу в синтаксисе определения классов между Scala и Java. В Scala параметры конструктора следуют за именем класса; отдельное определение конструктора класса в теле Succ не нужно. Этот конструктор называется первичным конструктором (primary constructor); при вызове первичного конструктора во время создания экземпляра класса исполняется все тело класса. На тот случай, когда нужно более одного конструктора, предусмотрен синтаксис вторичных конструкторов (secondary constructors).
Возможность создавать пользовательские инфикс-операторы ставит вопрос об их относительном старшинстве и ассоциативности. Одной возможностью может быть наличие “fixity”-деклараций в стиле Haskell или SML, где пользователи могут объявлять эти свойства оператора индивидуально. Однако такие декларации плохо сочетаются с модульным программированием. В Scala выбрана более простая схема с фиксированными старшинством и ассоциативностью. Старшинство инфикс-оператора определяется по его первой букве; это совпадает со старшинством операторов, принятым в С и Java для операторов, начинающихся со знака оператора, используемого в этих языках. Вот список операторов, отсортированный по возрастанию:
Операторы обычно лево-ассоциативны, то есть x+y+z интерпретируется как (x+y)+z. Единственное исключение из этого правила – операторы, заканчивающиеся двоеточием. Они считаются право-ассоциативными. Примером служит образующий списки оператор ::. Так, x::y::zs интерпретируется как x::(y::zs). Право-ассоциативные операторы, кроме того, по-другому интерпретируются в смысле просмотра методов. Если у обычных операторов в качестве приемника используется левый операнд, то у право-ассоциативных – правый. Например, последовательность создания списка x::y::zs эквивалентна zs.::(y).::(x). На самом деле, :: реализован как метод Scala-класса List, предпосылающего данный аргумент списку приемников и возвращающего результирующий список.
Некоторые операторы в Scala не всегда вычисляют свой аргумент; примером могут служить стандартные булевы операторы && и ||. Такие операторы можно также представить как методы, поскольку Scala позволяет передавать аргументы по имени. Например, вот сигнатура пользовательского trait-а Bool, имитирующего предопределенные булевы значения:
trait Bool { def &&(defx: Bool) : Bool; def ||(defx: Bool) : Bool; } |
В этом trait-е формальный параметр методов || и && предваряется def. Реальные аргументы этих параметров передаются в не вычисленной форме. Аргументы вычисляются при каждом упоминании имени формального параметра (то есть формальный параметр ведет себя как функция без параметров). (В среде функционального программирования это называется ленивыми вычислениями. Практически все ФЯ поддерживают в той или иной форме ленивые вычисления – либо они полностью ленивы, либо имеют соответствующую поддержку в библиотеках (хотя, строго говоря, имея возможность создавать анонимные функции, ленивость легко реализовать руками самому) – прим.ред.)
Вот два канонических экземпляра класса Bool:
object False extends Bool { def &&(defx: Bool) : Bool = this; def ||(defx: Bool) : Bool = x; } object True extends Bool { def &&(defx: Bool) : Bool = x; def ||(defx: Bool) : Bool = this; } |
Как можно увидеть из этих реализаций, правый операнд операции && (и соответственно ||) вычисляется, только если левый операнд – объект True(False).
Как показывают примеры из этого раздела, в Scala любой оператор можно определить как метод и рассматривать любую операцию как вызов метода. В целях эффективности компилятор Scala транслирует операции над типами-значениями прямо в коды примитивных инструкций; это, однако, полностью прозрачно для программиста.
Если каждая операция в Scala – это вызов метода, то как насчет разыменования и присваивания переменных? На самом деле, при работе с членами классов эти операции также расцениваются как вызовы методов. Для каждого определения переменной varx:T в классе Scala определяет методы setter и getter:
def x: T; def x_ = (newval: T) : unit; |
Эти методы ссылаются на изменяемую ячейку памяти (и обновляют ее), недоступную из Scala-программ напрямую. Каждое упоминание имени х в выражении, таким образом, становится вызовом лишенного параметров метода х. Далее, каждое присваивание х=е интерпретируется как вызов метода x_=(e).
В Scala интерпретация обращения к переменным как вызовов методов позволяет определять свойства (в смысле C#). Например, следующий класс Celsius определяет свойство degree, которое может иметь значения не меньше -273.
class Celsius { private var d: int = 0; def degree: int = d; def degree_ = (x: int) : unit = if (x >= -273) d = x } |
Клиенты могут использовать пару методов, определенных в классе Celsius, как если бы объявлялась переменная:
val c = new Celsius; c.degree = c.degree - 1 |
Scala – это функциональный язык в том смысле, что каждая функция – это значение. Он предоставляет легковесный синтаксис для определения анонимных и карринговых функций (функций, для которых допустимо частичное определение. Def sum a b = a + b – пример такой функции, мы можем определить функцию inc путем частичного применения add: def inc = add 10 – прим.ред.), а также поддерживает вложенные функции.
Чтобы проиллюстрировать использование функций как значений, рассмотрим функцию exists, проверяющую, содержит ли некий массив элемент, удовлетворяющий заданному предикату:
def exists[T](xs: Array[T], p:T => boolean) = { var i: int = 0; while (i < xs.length && !p(xs(i))) i = i + 1; i < xs.length } |
Тип элемента массива – произвольный; это выражается параметром типа [T] метода exists (параметры типов подробно рассматриваются ниже). Предикат для проверки – тоже произвольный; это выражается параметром p метода exists. Тип p – это тип функции T=>boolean, значениями которой являются все функции из домена Т в boolean. Функции параметры можно применять так же, как обычные функции; примером может служить применение p в условии цикла while. Функции, принимающие другие функции в качестве аргументов, или возвращающие их в качестве результата, называются функциями высшего порядка.
Имея функцию exists, мы можем определить функцию forall в терминах этой функции с помощью двойного отрицания: предикат выполняется для всех значений массива, если не существует элемента, для которого он не выполняется (фактически означает, что (для любого x из X P(x) = true) ( (не существует x из X, такого что P(x) = false)). Это выражается следующей функцией forall:
def forall[T](xs: Array[T], p: T => boolean) = { def not_p(x: T) = !p(x); !exists(xs, not_p) } |
Функция forall определяет вложенную функцию not_p, которая отрицает предикат параметра p. Вложенные функции могут обращаться к параметрам и локальным переменным определенным в их окружении; например, not_p обращается к параметру р функции forall.
Можно определить функцию, не давая ей имени; это используется в следующей, более короткой версии forall:
def forall[T](xs: Array[T], p: T => boolean) = !exists(xs, x: T => !p(x)); |
Здесь x:T=>!p(x) определяет анонимную функцию, которая отображает свой параметр x типа T на !p(x).
Используя exists и forall, мы можем определить функцию hasZeroRow, которая проверяет, есть ли в данной двумерной матрице целых чисел строка, состоящая из одних нулей.
def hasZeroRow(matrix: Array[Array[int]]) =
exists(matrix, row: Array[int] => forall(row, 0==));
|
Выражение forall(row, 0==) проверяет, состоит ли строка только из нулей. Здесь метод == числа 0 передается как аргумент, соответствующий параметру предиката p. Это показывает, что сами методы могут использоваться в Scala как значения; это похоже на концепцию делегатов в C#.
Если методы – это значения, а значения – это объекты, то сами методы также являются объектами. На самом деле, синтаксис типов и значений функций – это просто "синтаксический сахар" для определенных типов классов и экземпляров классов. Тип функции S=>T эквивалентен параметризованному типу класса scala.Function1[S, T], который определен в стандартной библиотеке Scala так:
package scala; trait Function1[S, T] { def apply(x: S) : T } |
Аналогичные конвенции существуют для функций, имеющих более одного аргумента. В общем случае, N-арный тип, (T1, T2, ..., Tn)=>T, интерпретируется как Functionn[T1, T2, ..., Tn, T]. Таким образом, функции интерпретируются как объекты с методами apply. Например, анонимная функция “incrementer” x:int=>x+1 будет развернута в экземпляр Function1:
new Function1[int, int] { def apply(x: int) : int = x + 1 } |
И наоборот, если значение функционального типа применяется к некоторым аргументам, неявно вставляется метод типа apply. Например, для p типа Function1[S, T] использование p(x) расширяется до p.apply(x).
Поскольку типы функций в Scala – это классы, они в дальнейшем могут уточняться в подклассах. В качестве примера можно взять массивы, которые рассматриваются как специальные функции в домене целых. Класс Array[T] унаследован от Function1[int, T], и добавляет в числе прочих методы обновления массива и длины массива.
package scala; class Array[T] extends Function1[int, T] { def apply(index: int) : T = ...; def update(index: int, elem: T) : unit = ...; def length : int = ...; def exists(p: T => boolean) : boolean = ...; def forall(p: T => boolean) : Boolean = ...; ... } |
Для применения функции, стоящей с левой стороны от присваивания, существует специальный синтаксис; это интерпретируется как применение метода update. Например, назначение a(i)=a(i)+1 интерпретируется как:
a.update(i, a.apply(i) + 1). |
Интерпретация обращений к массивам как применения функции может показаться дорогостоящей. Однако inlining-трансформации в компиляторе Scala трансформируют код, подобный приведенному выше, в примитивный доступ к массиву.
В приведенном выше определении класса Array приведены также методы exists и forall. Таким образом, определять вручную эти операции не придется. С использованием этих методов функция hasZeroRow может выглядеть так:
def hasZeroRow(matrix: Array[Array[int]]) =
matrix exists(row => row forall (0 ==));
|
Заметьте близкое соответствие этого кода вербальной спецификации задачи: "проверить, есть ли в матрице строка, в которой все элементы являются нулями". Заметьте также, что тип параметра row в анонимной функции пропущен. Этот тип может быть выведен компилятором Scala из типа matrix.exists.
Методы высшего порядка широко применяются в обработке последовательностей. В библиотеке Scala определено несколько видов последовательностей, среди них списки, потоки и итераторы. Все типы последовательностей наследуются от trait-а scala.Seq; и все они определяют наборы методов, упрощающих распространенные задачи. Например, метод map применяет указанную функцию единообразно ко всем элементам последовательности, выдавая последовательность результатов функции. Другой пример – метод filter, применяющий заданную функцию-предикат ко всем элементам последовательности, и возвращающий последовательность элементов, для которых предикат верен.
Применение этих двух функций иллюстрирует следующая функция, sqrts, принимающая список чисел с двойной точностью и возвращающая список, состоящий из квадратных корней всех неотрицательных элементов xs.
def sqrts(xs: List[double]) : List[double] =
xs filter (0<=) map Math.sqrt;
|
Заметьте, что Math.sqrt происходит из Java-класса. Такие методы могут быть переданы функциям высшего порядка так же, как методы, определенные в Scala.
Scala предоставляет специальный синтаксис для более естественного выражения комбинаций некоторых высокоуровневых функций. For comprehensions – это обобщение list comprehensions, встречающихся в языках наподобие Haskell. С помощью for comprehension функция sqrts может быть записана так:
def sqrts(xs: List[double]) : List[double]= for(val x <- xs; 0 <= x) yield Math.sqrt; |
Здесь "val x <- xs" – это генератор, который производит последовательность значений, а "0 <= x" – фильтр, исключающий из рассмотрения некоторые из получаемых значений. Comprehension возвращает другую последовательность, образованную значениями, выданными частью yield. Comprehension может содержать несколько генераторов и фильтров.
For comprehensions выражаются через комбинации методов высшего порядка map, flatMap и filter. Например, формулировка приведенного выше метода sqrts будет отображена на реализацию sqrts из раздела "Последовательности".
Сила for comprehensions в том, что они не привязаны к конкретному типу данных. Они могут быть сконструированы над любым несущим типом, который определяет подходящие методы map, flatMap и filter. В это число входят все типы последовательностей, необязательные значения, интерфейсы баз данных, а также несколько других типов. Пользователи Scala могут применять forcomprehensions к собственным типам, если они поддерживают нужные методы.
Циклы for в Scala похожи на comprehensions. Они отображаются на комбинации методов foreach и filter. Например, цикл for:
for (val arg <- args)... |
из листинга 1 отображается на:
args foreach (arg => ...) |
Важная проблема компонентных систем – как абстрагироваться от требуемых компонентов. В языках программирования есть два основных способа абстрагирования: параметризация и абстрактные члены. Первый способ, как правило, применяется для функций, а второй, как правило, для объектов. Java традиционно поддерживала функциональную абстракцию для значений и объектно-ориентированную абстракцию для операций. Новая Ява 1.5 (включающая generic-классы) поддерживает функциональную абстракцию также для типов.
Scala поддерживает оба стиля абстракций и для типов, и для значений. И типы, и значения могут быть как параметрами, так и абстрактными членами. В этом разделе рассматриваются оба стиля, а также большая часть системы типов Scala.
Следующий класс определяет простой trait, реализующий некую ячейку, доступную на чтение и запись.
class GenCell[T](init: T) { private var value: T = init; def get: T = value; def set(x: T) : unit = { value = x } } |
Класс абстрагирует некоторое значение, тип которого определяется параметром типа T. Можно также сказать, что класс GenCell – generic-класс.
Как и классы, методы также могут иметь параметры типов. Следующий метод меняет местами содержимое двух ячеек. Ячейки должны содержать однотипные значения.
def swap[T](x: GenCell[T], y: GenCell[T]) : unit = { val t = x.get; x.set(y.get); y.set(t) } |
Следующий код создает две ячейки, содержащие целые числа, и затем меняет местами их содержимое.
val x: GenCell[int] = new GenCell[int](1); val y: GenCell[int] = new GenCell[int](2); swap[int](x, y) |
Фактические аргументы типа указываются в квадратных скобках; они заменяют формальные параметры конструктора или методов класса. Scala поддерживает сложную систему выведения типа, которая разрешает опускать фактические аргументы типа в обоих случаях. Для метода или конструктора аргументы типа могут выводиться из ожидаемого типа результата или типов аргументов с помощью локального выведения типов. Следовательно, пример, приведенный выше, можно переписать без любых аргументов типа:
valx = new GenCell(1); valy = new GenCell(2); swap(x, y) |
Трактовка параметров (Parameter bounds). Рассмотрим метод updateMax, устанавливающий для ячейки максимальное значение из значений свойства и параметра. Определим updateMax так, чтобы он работал с любыми значениями ячейки, допускающими использование функции сравнения “<”, определенной в trait-е Ordered. На минуточку представим, что этот trait определен следующим образом (более совершенная версия этого trait-а содержится в стандартной библиотеке Scala).
trait Ordered[T] { def <(x:T) : boolean; } |
Метод UpdateMax может быть определен обобщенным образом с использованием полиморфизма c ограничениями (bounded-полиморфизма):
def updateMax[T <: Ordered[T]](c:GenCell[T], x:T) = if (c.get < x) c.set(x) |
Здесь описание параметра типа [T <: Ordered[T]] вводит сужающую трактовку параметра типа (bounded type parameter). Он ограничен теми типами Т, которые являются подтипами Ordered[T]. Поэтому метод < класса Ordered может быть применен к аргументам типа Т. Суженный параметр (т.е. параметр, описанный с ограничениями) типа может сам появляться как часть другой трактовки параметра, т.е. Scala поддерживает так называемый F-ограниченный полиморфизм, описанный в [8].
Вариантность (Variance). Комбинация generic-ов и subtyping-а (выделения подтипов) в языке поднимает вопрос об их взаимодействии. Если C – конструктор типа, а S – подтип T, получается ли, что C[S] – подтип C[T]? Конструкторы типа, имеющие такое свойство, называют ковариантными. Конструктор типа GenCell, очевидно, не должен быть ковариантным; иначе можно было бы создать следующую программу, приводящую во время выполнения к ошибке:
val x: GenCell[String] = new GenCell[String]; val y: GenCell[Any] = x; // недопустимо! y.set(1); val z: String = y.get |
Присутствие изменяемой (mutable) переменной в GenCell делает ковариантность опасной. На самом деле, GenCell[String] – это не особый случай GenCell[Any], так как есть вещи, которые можно сделать с GenCell[Any], но нельзя сделать с GenCell[String]; например, задать такой ячейке целочисленное значение.
С другой стороны, для не изменяющихся (immutable) структур данных ковариантность безопасна и очень естественна. Например, неизменяемый список целых чисел можно естественно представить как специальный случай списка элементов типа Any. Есть также случаи, где желательна контрвариантность (contravariance) параметров. В качестве примеров можно привести каналы вывода Chan[T], с операцией записи, принимающей параметр Т. Здесь может понадобиться Chan[S] <: Chan[T] в случае, когда T <: S.
Scala позволяет объявить вариантность параметров типов класса с помощью знаков + и -. "+" перед именем параметра указывает, что конструктор ковариантен по отношению к параметру, "-" указывает, что он контрвариантен, а отсутствие префикса говорит об отсутствии вариантности.
Например, следующий trait GenList определяет простой ковариантный список с методами isEmpty, head и tail.
trait GenList[+T] { def isEmpty: boolean; def head: T; def tail: GenList[T] } |
Система типов Scala обеспечивает опознание аннотаций вариантности с помощью отслеживания позиций применения параметров типов. Если параметр типа встречается в качестве типа возвращаемого значения функции или типа, доступного только на чтение свойства, он рассматривается как ковариантный. Если параметр типа встречается в качестве параметра метода или изменяемого свойства/поля, то он рассматривается как контрвариантный. Параметр типа также рассматривается как контрвариантный и при явном сужении трактовки типа. Аргументы невариантных параметров типов всегда находятся в невариантной позиции. Ковариантные и контрвариантные позиции меняются местами внутри аргумента типа, соответствующего контрвариантному параметру. Система типов гарантирует, что ковариантные (и соответственно, контрвариантные) параметры типов используются только в ковариантных (контрвариантных) позициях.
Вот две реализации класса GenList:
Here are two implementations of the GenList class:
object Empty extends GenList[All] { def isEmpty: Boolean = true; def head: All = throw new Error("Empty.head"); def tail: List[All] = throw new Error("Empty.tail"); } class Cons[+T](x:T, xs:GenList[T]) extends GenList[T] { def isEmpty:boolean=false; def head:T = x; def tail: GenList[T]=xs } |
Заметьте, что объект Empty представляет пустой список для любого списка с любым типом элементов. Это возможно благодаря ковариантности, так как тип Empty, GenList[All], это подтип GenList[T] для любого типа элемента Т.
Бинарные методы и расширение трактовки типа. До сих пор мы ассоциировали ковариантность с неизменяемыми структурами данных. На самом деле, это не вполне корректно – из-за бинарных методов. Рассмотрим, например, добавление метода prepend в trait GenList. Наиболее естественное определение этого метода принимает аргумент тип которого – это тип элемента списка:
trait GenList[+T] { ... def prepend(x: T): GenList[T] = // недопустимо! new Cons(x, this) } |
Однако это не типо-корректно, поскольку здесь параметр типа Т появляется в контрвариантной позиции внутри trait-а GenList. Поэтому его нельзя пометить как ковариантный. Это обидно, так как концептуально неизменяемые списки должны быть ковариантными. Проблема может быть решена при помощи обобщения prepend с использованием расширения трактовки типа (lower bound).
trait GenList[+T] { ... def prepend[S >: T](x: S): GenList[S] = // OK new Cons(x, this) } |
Теперь prepend – полиморфный метод, принимающий аргумент некоторого типа S, являющегося супертипом по отношению к Т. Он возвращает список элементов этого супертипа. Новое определение метода вполне легально для ковариантных списков, так как расширяющая трактовка типа также классифицируется как ковариантная позиция; следовательно, параметр типа Т теперь возникает внутри trait-а GenList только ковариантно.
В декларации параметра типа можно комбинировать расширение и сужение трактовки типа (upper and lower bounds). Примером может служить следующий метод, less, класса GenList, сравнивающий один список с другим:
trait GenList[+T] { ... def less[S >: T <: Ordered[S]](that: List[S]) = !that.isEmpty && (this.isEmpty || this.head < that.head || this.head == that.head && this.tail less that.tail ) } |
Параметр типа S является расширенной трактовкой типа Т (элемента списка), которая сужается до Ordered[S]. Расширение трактовки нужно, чтобы поддерживать ковариантность GenList, а сужение – чтобы гарантировать, что элементы списка можно будет сравнивать с помощью операции <.
Сравнение с подстановочными знаками (wildcards). В Java 1.5 есть способ аннотировать вариантность (указывать трактовку типа), основанный на подстановочных знаках. Эта схема, в сущности, является синтаксическим вариантом "variant parametric types", разработанных Igarashi и Viroli, и описанных в [20]. В отличие от Scala, в Java 1.5 аннотации относятся не к объявлениям типов, а к выражениям типов. Например, ковариантные обобщенные списки могут быть выражены с помощью записи GenList<?extendsT> во всех местах, где требуется ссылка на тип списка.
Такое выражение типа обозначает экземпляры типа GenList, где аргумент типа – произвольный подтип Т.
Ковариантные подстановочные знаки могут использоваться в любом выражении типа. Однако члены, где переменная типа не появляется в ковариантной позиции, будут "забыты". Например, тип GenCell<? extends Number> будет иметь только метод get типа Number, тогда как метод Set, в котором параметр типа GenCell встречается контрвариантно, будет "забыт".
В ранних версиях Scala мы тоже экспериментировали с подходами, похожими на подстановочные знаки. На первый взгляд, эта схема выглядит привлекательно благодаря своей гибкости. Один класс в ней может иметь как ковариантные, так и невариантные фрагменты; пользователь делает выбор между ними, помещая или пропуская подстановочные знаки. Однако это увеличение гибкости имеет цену, поскольку теперь пользователь класса, а не его создатель должен проверять, что вариантность не приводит противоречиям. Мы обнаружили, что на практике довольно сложно добиться непротиворечивости в использовании аннотаций, так что ошибки типов случались довольно часто. Наоборот, задание трактовки типов в декларации класса оказалось очень полезным для улучшения дизайна класса; например, такие трактовки отлично помогают определить, какие методы должны быть обобщены с расширением трактовки типа. Более того, mixin-композиция Scala (см. соотв. раздел) делает относительно простым явное разложение классов на ковариантные и контрвариантные фрагменты; используемая в Java схема одиночного наследования с интерфейсами, скорее всего, значительно затруднила бы это. По этим причинам поздние версии Scala используют трактовку типов в декларациях.
Объектно-ориентированная абстракция может использоваться в Scala как альтернатива функциональной абстракции. Например, вот версия типа “cell”, использующего объектно-ориентированную абстракцию:
abstract class AbsCell { type T; val init: T; private var value: T = init; def get: T = value; def set(x: T) : unit = { value = x } } |
Класс AbsCell не определяет ни параметров типов, ни обычных параметров. Вместо этого он содержит абстрактный член типа, Т, и абстрактную переменную init. Экземпляры этого класса могут быть созданы с помощью реализации этих абстрактных членов с конкретными определениями. Например:
val cell = new AbsCell { type T = int; val init = 1 } cell.set(cell.get * 2) |
Тип cell – AbsCell { type T = int }. Здесь тип класса AbsCell уточнен: { type T = int }. Это делает псевдоним типа cell.T=int известным коду, обращающемуся к значению cell. Следовательно, допустимы специфичные для типа операции, подобные приведенной ниже:
cell.set(cell.get * 2) |
Типы, зависящие от пути (Path-dependent types). Можно обращаться к AbsCell, не зная конкретного значения типа, ассоциированного с ним.
Например, следующий метод сбрасывает значение заданной ячейки в исходное, независимо от его типа:
def reset(c: AbsCell) : unit = c.set(c.init); |
Почему это работает? В приведенном выше примере тип выражения c.init – c.T, а тип метода c.set - c.T=>unit. Поскольку формальный тип параметра и тип аргумента совместимы, вызов метода типо-корректен.
c.T – это экземпляр типа, зависимого от пути. В общем случае, такие типы имеют следующую форму – x1.....xn.t, где n>0, x1, ..., xn означают неизменяемые значения, а t – член типа xn. Типы, зависимые от пути – оригинальная концепция Scala, их теоретическое обоснование взято из ?Obj-исчисления [30].
Типы, зависимые от пути, полагаются на неизменность пути префикса. Вот пример нарушения этой неизменности:
var flip = false; def f(): AbsCell = { flip = !flip; if (flip) new AbsCell { type t = int; val init = 1} else new AbsCell { type t = String; val init = "" } } f().set(f().get) // Недопустимо! |
В этом примере последовательные вызовы f() возвращают попеременно целочисленные и строковые ячейки. Последнее выражение в приведенном выше коде ошибочно, так как оно пытается присвоить int-ячейке значение типа String. Система типов такого не допускает, поскольку вычисляемым типом f().get должен быть f().T. Это не определенный (well-formed) тип, так как вызов метода f() – это не путь.
Выбор типа и singleton-типы. В Java, где классы, как и в Scala, могут быть вложенными, тип вложенного класса указывается префиксом – именем внешнего класса. В Scala этот тип также может быть выражен, в виде Outer#Inner, где Outer – это имя внешнего класса, в котором определен класс Inner. Оператор “#” указывает выбранный тип. Заметьте, что это концептуально отличается от зависимого от пути типа p.Inner, где путь p указывает значение, а не класс. Следовательно, выражение типа Outer#t не является определенным (well-formed), если t – это абстрактный тип, определенный в Outer.
На самом деле, зависимые от пути типы в Scala могут быть преобразованы в выбор типа (type selection). Зависимый от пути тип p.t рассматривается как сокращенная запись p.type#t. Здесь p.type – это singleton-тип, представляющий собой просто объект, обозначенный как p. Сами по себе singleton-тип полезны также для поддержки формирования цепочек вызовов методов. Рассмотрим, например, класс С с методом incr, увеличивающий значение защищенного целочисленного поля, и подкласс D класса С, добавляющий метод decr, уменьшающий это значение.
class C { protected var x = 0; def incr: this.type = { x = x + 1; this } } class D extends C { def decr: this.type = { x = x - 1; this } } |
Теперь можно составить цепочку вызовов incr и decr:
val d = new D; d.incr.decr; |
Без singleton-типа this.type это было бы невозможно, так как метод d.incr должен был бы иметь тип С, который не содержит члена decr. В этом смысле this.type похож на (ковариантное применение) mytype Kim Bruce-а [7].
Семейный полиморфизм (family polymorphism) и self-типы. Концепция абстрактных типов Scala чрезвычайно хорошо подходит для моделирования семейств типов, которые изменяются вместе ковариантно. Эту концепцию мы назвали "семейным полиморфизмом". В качестве примера рассмотрим паттерн "наблюдатель", применяемый в данном случае для реализации модели "издатель/подписчик". Есть два класса участников – субъекты и наблюдатели. Субъекты определяют метод subscribe, с помощью которого регистрируются наблюдатели. Они также определяют метод publish, оповещающий всех зарегистрированных наблюдателей. Оповещение производится с помощью вызова метода notify, определяемого всеми наблюдателями. Обычно publish вызывается, когда изменяется состояние субъекта. С субъектом может быть связано несколько наблюдателей, а каждый наблюдатель может отслеживать нескольких субъектов. Метод subscribe принимает идентификатор регистрируемого наблюдателя как параметр, а метод наблюдателя notify принимает в качестве параметра субъекта, производящего оповещение. Таким образом, субъекты и наблюдатели ссылаются друг на друга в сигнатурах методов.
Все элементы этого паттерна проектирования укладываются в следующую систему:
trait SubjectObserver { type S <: Subject; type O <: Observer; class Subject : S { private var observers: List[O] = List(); def subscribe(obs: O) = observers = obs::observers; def publish = for(val obs <- observers) obs.notify(this); } trait Observer { def notify(sub: S): unit; } } |
Trait верхнего уровня SubjectObserver содержит два класса-члена: один – для субъектов, другой – для наблюдателей. Класс Subject определяет методы subscribe и publish. Он поддерживает список всех зарегистрированных наблюдателей в private-переменной observers. Trait Observer только объявляет абстрактный метод notify.
Заметьте, что классы Subject и Observer не ссылаются друг на друга напрямую, поскольку такие "жесткие" ссылки помешают ковариантному расширению этих классов в клиентском коде. Вместо этого SubjectObserver определяет два абстрактных типа S и O, которые уточняются соответствующими типами Subject и Observer. Subject и Observer используют эти абстрактные типы для ссылок друг на друга.
Заметьте также, что класс Subject содержит явное указание базового типа:
class Subject : S
{
...
|
Здесь S называется self-типом класса Subject. Если задан self-тип, он используется как тип this внутри класса (в отсутствие self-типа тип this совпадает с типом самого класса). В классе Subject self-тип необходим, чтобы обеспечить типо-корректность вызова obs.notify(this).
Self-типы могут быть произвольными; они не обязаны иметь какое-то отношение к определяемому классу. Непротиворечивость типов по-прежнему гарантируется благодаря двум требованиям: (1) self-тип класса должен быть подтипом self-типов всех своих базовых классов. (2) при создании экземпляра класса выражением new, проверяется, что self-тип класса – это супертип типа создаваемого объекта.
Self-типы впервые появились в ?Obj-исчислении. Они относительно редко используются в Scala-программах, но, тем не менее, в ситуациях, где семейный полиморфизм используется в комбинации с явными ссылками, без них не обойтись.
Механизм, определяемый паттерном publish/subscribe, можно использовать с помощью наследования от SubjectObserver и определения специфичных для приложения классов Subject и Observer. Ниже приведен пример – объект SensorReader, принимающий сенсоры в качестве объектов и дисплеи в качестве наблюдателей.
object SensorReader extends SubjectObserver { type S = Sensor; type O = Display; abstract class Sensor extends Subject { val label: String; var value: double = 0.0; def changeValue(v: double) = { value = v; publish; } } abstract class Display extends Observer { def println(s:String) = ... defnotify(sub: Sensor) = println(sub.label + "hasvalue" + sub.value); } } |
В этом объекте тип S уточняется типом Sensor, а тип O – типом Display. Таким образом, эти два, ранее абстрактных, класса теперь определены с помощью замены определений. Такое "затягивание узла" необходимо при создании конкретных экземпляров классов. С другой стороны, можно определить абстрактный класс SensorReader, который может быть детализирован позже в клиентском коде. В этом случае два абстрактных типа следует переопределить снова с помощью определений абстрактных типов.
class AbsSensorReader extends SubjectObserver { type S <: Sensor; type O <: Display; ... } |
Следующий код показывает использование объекта SensorReader.
object Test { import SensorReader._; val s1 = new Sensor { val label = "sensor1" } val s2 = new Sensor { val label = "sensor2" } def main(args: Array[String]) = { val d1 = new Display; val d2 = new Display; s1.subscribe(d1); s1.subscribe(d2); s2.subscribe(d1); s1.changeValue(2); s2.changeValue(3); } } |
Обратите внимание на директиву import, которая делает члены объекта SensorReader доступными без префикса коду объекта Test. Выражения импорта в Scala – более общие, чем в Java. Их можно использовать повсеместно, причем импортировать члены любого объекта, а не только package-а.
Наличие двух абстракций типов в одном языке поднимает вопрос о сложности языка – нельзя ли было обойтись одной? В этом разделе мы покажем, что функциональная абстракция типов (ака обобщенные типы) может в принципе быть смоделирована с помощью объектно-ориентированной абстракции типов (иначе абстрактных типов). Одну форму можно трансформировать в другую. Идея трансформации в общих чертах описана ниже.
Предположим, что у нас есть параметризованный класс C с параметром типа Т (код напрямую обобщается в множественные параметры типов). Трансформация состоит из четырех частей, затрагивающих определение класса, создание экземпляров класса, вызовы конструкторов базового класса и экземпляры типов класса.
1. Определение класса C трансформируется так:
class C { type t; /* остальная часть класса */ } |
Таким образом, параметры исходного класса моделируются с помощью абстрактных членов трансформированного класса. Если параметр типа t имеет сужения и/или расширения, они переносятся в определение абстрактного типа. Вариантность параметров типа не переносится; вместо этого вариантность влияет на формирование типов (см. пункт 4).
2. Создание каждого экземпляра new C[T] с аргументом типа Т трансформируется в:
new C { type t = T } |
3. Если C[T] выступает в роли конструктора суперкласса, его классы-наследники дополняются определением:
type t = T
|
4. Каждый из типов C[T] трансформируется в один из следующих типов, каждый из которых дополняет класс С уточнением:
Такой код работает, если не встречается конфликтов имен. Поскольку имя параметра становится членом класса, оно может конфликтовать с другими членами, включая унаследованные члены, сгенерированные по именам параметров базовых классов. Этих конфликтов имен можно избежать переименованием, например, дополнением каждого имени уникальным номером.
Возможность трансформации из одного стиля абстракции в другой полезна, так как снижает концептуальную сложность языка. В случае Scala обобщенные типы становятся не более, чем "синтаксическим сахаром", который можно устранить трансформацией в абстрактные типы. Однако возникает вопрос, насколько обосновано наличие этого синтаксического сахара, и нельзя ли обойтись одними абстрактными типами, то есть ограничиться синтаксически меньшим языком. Есть два аргумента за включение обобщенных типов в Scala. Во-первых, трансформацию в абстрактные типы не так уж просто писать вручную. Это приводит потерь выразительности, и есть также проблема случайных конфликтов имен между именами абстрактных типов, эмулирующих параметры типов. Во-вторых, обобщенные и абстрактные типы обычно играют в Scala-программах различные роли. Обобщенные типы обычно используют, когда нужна только реализация экземпляра типа, а абстрактные типы – когда нужна ссылка на абстрактный тип из клиентского кода. Последнее встречается, в частности, в двух ситуациях. Может понадобиться спрятать точное определение члена типа от клиентского кода, чтобы получить нечто вроде инкапсуляции, известной по модульным системам в SML-стиле. Или же может потребоваться переопределить тип ковариантно в подклассах, чтобы получить семейный полиморфизм.
Можно ли пойти другим путем и перекодировать абстрактные типы в обобщенные? Оказывается, это значительно труднее, и требует полного переписывания программы. Это было показано в исследованиях в области модульных систем, где доступны оба вида абстракции [21]. На самом деле такая сложность неудивительна, если рассматривать проблему с точки зрения основ теории типов обеих систем. Обобщенные типы (без F-ограничений) могут выражаться в System F<: [описанной в 9], тогда как абстрактные типы требуют системы, основанной на зависимых типах. Последние, в общем, выразительнее предыдущих, например, ?Obj с его зависимыми от пути типами позволяет закодировать F<:.
Повторное использование существующих компонентов ПО при создании новых систем имеет множество преимуществ: оно уменьшает стоимость и время разработки, снижает требования к поддержке, а также повышает надежность ПО.
Поэтому объектно-ориентированные языки программирования содержат механизмы, обеспечивающие возможность повторного использования существующих программных сущностей, например, классов. В этом разделе рассматривается работа механизмов повторного использования кода в Scala на примере кода, приведенного ниже. Этот код определяет обобщенный класс Buffer[T] для сборки последовательностей элементов.
class Buffer[T] { var xs: List[T] = Nil; def add(elem: T) : Unit = xs = elem::xs; def elements: Iterator[T] = new BufferIterator; class BufferIterator extends Iterator[T] { var ys = xs; def hasNext: Boolean = !ys.isEmpty; def next: T = { val res = ys.head; ys = ys.tail; res } } } |
Реализация класса Buffer работает со следующей абстракцией итератора:
trait Iterator[T] { def hasNext: Boolean; def next: T; } |
Наследование. Как и в большинстве распространенных объектно-ориентированных языков, главный механизм повторного использования классов в Scala основывается на одиночном наследовании; то есть программисты могут специализировать классы, создавая подклассы. Чтобы расширить класс Buffer дополнительными методами forall и exists, можно, например, создать подкласс IterableBuffer, определяющий новую функциональность:
class IterableBuffer[T] extends Buffer[T] { def forall(p: T => Boolean) : Boolean = { val it = elements; var res = true; while (res && it.hasNext) res = p(it.next); res } def exists(p: T => Boolean) : Boolean = { val it = elements; var res = false; while (!res && it.hasNext) res=p(it.next); res } } |
Композиция типов (mixin-композиция). Проблема приведенного выше кода состоит в ограниченной возможности повторного использования. Представьте, что существует независимое расширение класса Buffer, моделирующее стек:
class Stack[T] extends Buffer[T] { def push(elem: T) : Unit = add(elem); def pop : T = { val y = xs.head; xs = xs.tail; y } } |
Одиночное наследование не позволяет повторно использовать существующие определения методов forall и exists совместно со стеком. Поэтому Scala предоставляет механизм композиции mixin-классов, позволяющий программистам повторно использовать различия в определениях классов (то есть использовать все новые определения, которые не были унаследованы, в определении нового класса). Этот механизм позволяет объединить IterableBuffer и Stack:
class IterableStack[T] extends Stack[T] with IterableBuffer[T]; |
Этот код определяет класс IterableStack[T], который наследует все определения из Stack[T], и, кроме того, включает новые определения из IterableBuffer[T]. Смешивание класса С с другим классом D законно, только если суперкласс D – подкласс суперкласса C. Так, mixin-композиция в приведенном выше коде вполне корректна, так как суперкласс класса IterableStack – подкласс суперкласса IterableBuffer.
Это требование в Scala введено по причинам типобезопасности. Поскольку при составлении mixin-классов в другой класс копируются только различия, могло бы случиться так, что некоторые привнесенные члены ссылались бы на унаследованные члены, отсутствующие в новом контексте, порождая исключение “метод не найден”.
Неоднозначности. В Scala каждый класс наследуется только от одного суперкласса, и получает члены класса от нескольких других классов в процессе составления mixin-класса. Представьте, например, следующий подкласс класса Buffer, который вводит метод sameElements, а также внутренне используемый метод forall.
class ComparableBuffer[T] extends Buffer[T] { def forall(p: T => Boolean) : Boolean = { val it = elements; var res = true; while (res && it.hasNext) res=p(it.next); res } def sameElements(b: IterableBuffer[T]) : Boolean = forall(elem => b.exists(elem.equals)); } |
Можно создать новый класс стека MyStack, который содержит функциональность, предоставляемую как IterableBuffer, так и ComparableBuffer, используя оба класса как mixin-ы.
class MyStack[T] extends Stack[T] with IterableBuffer[T] with ComparableBuffer[T]; // Ошибка! |
В Scala методы, определенные в mixin-ах, либо представляют новые методы, либо переопределяют соответствующие методы суперкласса. Как показано в предыдущем примере, может случиться так, что два mixin-а определят один и тот же метод. Классу MyStack неясно, какой из методов forall использовать. Такая неоднозначность порождает ошибку времени компиляции, которая должна быть явно устранена программистом. Возможное решение – ввести новый метод forall, который перенаправляет вызовы нужной реализации. Следующий код использует примитив super[C], позволяющий ссылаться на конкретные определения в mixin-классе C:
class MyStack[T] extends Stack[T] with IterableBuffer[T] with ComparableBuffer[T] { override def forall(p: T => Boolean) = super[IterableBuffer].forall(p); } |
Кроме неоднозначностей, есть еще одна серьезная проблема множественного наследования – дилемма бриллиантового наследования, возникающая, если класс является наследником двух классов, разделяющих один суперкласс. Без дальнейших ограничений эти суперклассы в данном сценарии будут унаследованы дважды. Это приведет к удвоению состояния, инкапсулированного в данных суперклассах, и выльется в серьезные проблемы с непротиворечивостью.
Чтобы избежать этого, Scala позволяет подмешивать класс в другой класс, только если он не использовался ранее в этом другом классе как суперкласс или mixin. К сожалению, это правило накладывает сильные ограничения, исключая множество случаев, когда двойное наследование от одного класса не является проблемой – в частности, для классов без инкапсулированного состояния (в эту категорию попадают интерфейсы Java). По этой причине в Scala введено понятие trait-ов. Trait-ы – это абстрактные классы, не инкапсулирующие состояния ни в виде определений переменных, ни в виде предоставления конструкторов с параметрами. Однако, в противоположность Java-интерфейсам, они могут реализовать конкретные методы.
Поскольку trait-ы не инкапсулируют состояния, двойное наследование от них в Scala разрешено. Таким образом, в иерархии суперклассов класса можно использовать один trait несколько раз.
Повторное использование класса IterableBuffer запрещено, так как он может быть смешан только с подклассами Buffer. Но функциональность, предоставляемая IterableBuffer, зависит только от наличия метода elements. Scala позволяет выразить это так:
trait Iterable[T] { def elements: Iterator[T]; def forall(p: T => Boolean) : Boolean = { val it=elements;varres=true; while (res&&it.hasNext) res=p(it.next); res } def exists(p: T => Boolean) : Boolean = { val it = elements; var res = false; while (!res && it.hasNext) res=p(it.next); res } } |
Trait Iterable, как и ранее, определяет методы forall и exists, но откладывает реализацию метода elements – он абстрактен в терминологии Java. В противоположность классу IterableBuffer, этот trait может быть смешан с любыми классами. Если Iterable подмешивается к классу, не имеющему конкретного метода elements, то результирующий класс будет содержать отложенный метод elements, иначе конкретный метод будет реализовать отложенный метод, упомянутый в trait-е Iterable. Таким образом, при создании mixin-классов конкретные методы всегда переопределяют абстрактные. Этот принцип используется в следующем альтернативном определении класса IterableBuffer:
class IterableBuffer[T] extends Buffer[T] withIterable[T]; |
Механизм композиции mixin-классов в Scala упрощает создание сложных классов с большой функциональностью из меньших и более простых, моделирующих только отдельные аспекты. В предыдущем разделе показано, как можно использовать trait-ы для создания абстракции обобщенных типов, которая может использоваться для добавления новых методов или реализации отложенных методов существующих классов. Trait-ы, подмешанные в класс, могут также переопределять существующие методы, как показано в следующем коде:
trait Displayable[T] { def elements: Iterator[T]; override def toString() : String = { val res = new StringBuffer; for (val elem <- elements) res.append(""+elem); res.toString() } } class DisplayableBuffer[T] extends IterableBuffer[T] withDisplayable[T]; |
Теперь класс DisplayableBuffer[T] содержит метод toString(), определенный в trait-е Displayable[T].
Представленная техника переопределения методов работает только если метод в суперклассе или в подмешанных trait-ах – конкретный. Но часто хочется определить обобщенные trait-ы, которые улучшают существующий метод, не конкретизированный в суперклассе, путем переопределения этого метода. В качестве примера рассмотрим создание строительного блока для синхронизации итераторов, чтобы они могли использоваться параллельно. Наивное определение выглядит так:
// ошибочное определение trait-а trait SynchronizedIterator[T] extends Iterator[T] { override def next: T = synchronized { super.next } override def hasNext: Boolean = synchronized { super.hasNext } } |
Это определение неверно, поскольку супер-trait Iterator не предоставляет конкретных реализаций методов next и hasNext. То есть, ни модификатор override, ни ссылку super использовать нельзя.
Scala все же позволяет программистам определить такую абстракцию. Но это требует использования модификатора abstract для всех методов, переопределяющих абстрактные методы в статическом суперклассе, и даже для тех, которые предполагается переопределить конкретными методами в mixin-композиции.
trait SynchronizedIterator[T] extends Iterator[T] { abstract override def next: T = synchronized { super.next } abstract override def hasNext: Boolean = synchronized { super.hasNext } } |
Нельзя создавать экземпляры классов, содержащих методы, помеченные модификаторами abstract и override – такие классы сами должны быть объявлены с модификатором abstract. Более того, такие классы могут смешиваться только с классами, которые предоставляют конкретные версии всех подмешиваемых методов, помеченных как abstract и override.
Trait-ы наподобие SynchronizedIterator очень полезны для синхронизации произвольных реализаций итераторов с помощью простой mixin-композиции. Например, можно реализовать синхронизированный итератор для класса Buffer, основываясь на несинхронизированной версии, определенной в классе BufferIterator в начале раздела "Повторное использование классов".
class Buffer[T] { ... def elements: Iterator[T] = new BufferIterator with SynchronizedIterator[T]; } |
В данном случае обобщенный класс синхронизированных итераторов предоставляет синхронизированные методы, перенаправляющие вызов соответствующим методам другого несинхронизированного итератора. Преимущество такого подхода – в гибкости, поскольку решать, какой итератор использовать – синхронизированный или несинхронизированный – можно динамически. С другой стороны, этот подход не гарантирует статически, что схема синхронизации будет работать во время исполнения, так как программисты могут легко обойти паттерн программирования, предоставляя несинхронизированный iterator.
Подход, основывающийся на композиции mixin-классов статически (во время компиляции) превращает итераторы в синхронизированные итераторы, гарантируя, что синхронизация не будет нарушена программистами во время исполнения. В Scala у программиста есть выбор между составлением абстракций во время исполнения с помощью композиции объектов или во время компиляции, с использованием композиции классов. Выбор в основном зависит от требований к гибкости и безопасности.
Программистам часто приходится иметь дело со структурированными данными. В объектно-ориентированном языке структурированные данные обычно реализуются как набор классов, представляющих различные структурные конструкции. При работе со структурированными данными программист может полагаться только на методы, предоставляемые этими классами.
Предположим, что нам нужно реализовать простой интерпретатор ?-исчисления. Используя схему объектно-ориентированной реализации, мы придем к решению, подобному приведенному ниже:
trait Term { def eval: Term = this; def apply(arg: Term) : Term = new App(this, arg); def subst(name: String, term: Term) : Term; } class Var(name: String) extends Term { def subst(str: String, term: Term) = if (name == str) term else this; } class Fun(arg: String, body: Term) extends Term { def apply(par: Term) : Term = body.subst(arg, par).eval; def subst(str: String, term: Term) : Term = if (str == arg) this else new Fun(arg, body.subst(str, term)); } class App(fun: Term, arg: Term) extends Term { def eval: Term = fun.eval.apply(arg.eval); def subst(name: String, term: Term) = new App(fun.subst(name, term), arg.subst(name, term)); } |
И хотя нас интересует исключительно метод eval, в trait Term придется вводить методы apply и subst, чтобы иметь возможность реализовать eval для класса App, не полагаясь на динамические проверки типов и приведения типов. Схема объектно-ориентированной декомпозиции требует предвидеть все операции, занимающиеся обходом данной структуры. Даже внутренние методы должны быть до некоторой степени открыты. Добавление новых методов трудоемко и ведет к ошибкам, поскольку требует изменения всех классов или создания их подклассов. Связанная с этим проблема – реализация операций распределена по всем участвующим классам, что усложняет понимание операций и их изменение.
Приведенный выше пример показывает, что существуют случаи, когда функциональная декомпозиция выгоднее. В функциональном языке программист обычно отделяет определение структуры данных от реализации операций. В то время, как структуры данных обычно определяются с использованием алгебраических типов данных, операции над этими типами – это простые функции, использующие сопоставление с образцом как основной принцип декомпозиции. Такой подход позволяет реализовать функцию eval, без необходимости реализации искусственных вспомогательных функций.
Scala предоставляет естественный способ решения приведенной выше задачи в функциональном стиле, предоставляя программисту механизм создания структурированных данных, похожих на алгебраические типы данных, и механизм декомпозиции, основанный на сопоставлении с образцом.
Вместо введения алгебраических типов в ядро языка, в Scala улучшен механизм абстракции классов для упрощения конструирования структурированных данных. Классы, отмеченные модификатором case, автоматически определяют конструктор с теми же аргументами, что и первичный конструктор. Более того, в Scala есть выражения сопоставления с образцом, позволяющие использовать эти конструкторы case-классов как образцы. Прежде чем перейти к деталям, посмотрим на определение ?-термов с использованием case-классов.
trait Term; case class Var(name: String) extends Term; case class Fun(arg: String, body:Term) extends Term; case class App(fun: Term, arg: Term) extends Term; |
С данными определениями можно создать ?-терм, не используя примитив new – простым вызовом конструкторов, ассоциированных с case-классами: Fun("f", Fun("x", App(Var("f"), Var("x")))). Выражения сопоставления с образцом в Scala предоставляют средства декомпозиции, использующие эти конструкторы как образцы. Вот реализация функции eval, использующая сопоставление с образцом:
object Interpreter { def eval(term: Term) : Term = term match { case App(fun, arg) => eval(fun) match { case Fun(par, body) => eval(subst(body, par, eval(arg))); } case _ => term } private def subst(t: Term, v: String, t0: Term) = t match { case Var(str) => if (str == v) t 0 else t case Fun(str, t1) => if (str == v) t Fun(str, subst(t1, v, t0)) case App(f, t1) => App(subst(f, v, t0), subst(t1, v, t0)) } } |
Выражение x match { case pat1 => e1 case pat2 => e2... } сравнивает значение х с образцами pat1, pat2 и т.д. в заданном порядке. Приведенный выше код использует образцы вида Constr(x1, ..., xn), где Constr – конструктор case-класса, а xi означает переменную. Объект соответствует образцу, если является экземпляром соответствующего case-класса. В процессе сопоставления находится первое соответствие образцу, создаются экземпляры переменных, описанных в образце и выполняется выражение, стоящее справа от образца (отделенное от образца знаком =>). Обратите внимание, что _ означает образец по умолчанию, соответствующий любому значению.
Преимущество такой схемы функциональной декомпозиции состоит в том, что в систему просто добавлять новые функции. С другой стороны, интеграция нового case-класса может потребовать изменения всех выражений сравнения. Некоторые приложения могут выиграть от возможности определения вложенных образцов или защищенных образцов. Например, вложенному образцу caseFun(x, Var(y))ifx==y=>... соответствует только Fun(v, Var(v)). Эквивалентность двух переменных х и у в предыдущем образце обеспечивается т.н. защитным выражением x == y.
| ПРИМЕЧАНИЕ Паттерны в Scala линейны в том смысле, что переменные могут встречаться в паттерне только один раз. |
XML – популярный формат данных. Scala разрабатывалась для упрощения создания и поддержки программ, работающих с XML. Она предоставляет модель данных для XML. Обработка XML может производиться путем разбора данных с использованием выражений сравнения.
Модель данных для XML в Scala – это неизменяемое представление упорядоченного неранжированного дерева. В таком дереве у каждого узла есть метка, последовательность дочерних узлов и ассоциативный список атрибутов и их значений. Все это описано в trait-е scala.xml.Node, который, кроме того, содержит эквиваленты XPath-операторов child и descendant-or-self, записываемые как \ и \\. Для элементов, текстовых узлов, комментариев, инструкций по обработке и ссылок на сущности существуют конкретные подклассы.
XML-синтаксис в Scala-программах можно использовать напрямую, например, в определениях значений.
val labPhoneBook =
<phonebook>
<descr>Phone numbers of <b>XML</b> hackers.</descr>
<entry>
<name>Burak</name>
<phone where="work">+41216936867</phone>
<phone where="mobile">+41786015436</phone>
</entry>
</phonebook>;
|
Значение labPhoneBook – это XML-дерево; один из его узлов – это phone, помеченный атрибутом where со значением "work", с последовательностью, состоящей из текстового узла "+412…". Из XML-синтаксиса можно перейти в Scala, используя скобки { и } (аналогично соглашениям, принятым в XQuery). Например, узел date с дочерним текстовым узлом, содержащим дату, можно определить как
<date>{ df.format(new java.util.Date()) }</date>.
|
Типы XML-документов обычно указываются в так называемых схемах. Популярными стандартами схем являются DTD [6], XML Schema[15] и RELAX NG [28]. На данный момент простую поддержку DTD предоставляет утилита dtd2scala. Она конвертирует DTD в набор определений классов, которые могут принимать значения, соответствующие DTD-описанию. Соответствие существующих XML-документов DTD можно проверить с помощью специального метода загрузки, пытающегося создать экземпляры соответствующих классов (используя соответствие образцу). В будущем планируется расширение поддержки типов, предоставляемых XML Schema, включая проверку статических типов через регулярные типы.
При декомпозиции XML-узлов можно использовать соответствие образцам. Scala позволяет использовать при этом XML-синтаксис, правда, только для элементов. Следующий пример показывает, как добавить запись в элемент phonebook.
import scala.xml.Node; def add(phonebook: Node, newEntry: Node) : Node = phonebook match { case <phonebook>{ cs@_* }</phonebook> => <phonebook>{ cs }{ newEntry }</phonebook> } val newPhoneBook = add(scala.xml.nobinding.XML.load("savedPhoneBook"), <entry> <name>Sebastian</name> <phone where="work">+41216936867</phone> </entry>); |
Функция add находит элемент phonebook, привязывая его дочернюю последовательность к переменной cs (регулярное выражение _* соответствует произвольной последовательности). Затем она конструирует новый элемент phonebook, состоящий из содержимого cs, за которым следует содержимое переменной newEntry.
Регулярные выражения расширяют поиск по обычным алгебраическим образцам, обсуждавшийся в предыдущем разделе, знаками * (от нуля до произвольного количества повторов последовательности), ? (ноль или одно вхождение последовательности) и | (для описания альтернативных последовательностей). Их можно применить к любой последовательности, т.е. к любому экземпляру Seq[A]. Их использование показано в следующем примере:
def findRest(z: Seq[Char]) : Seq[Char] = z match { case Seq(_*, ’G’, ’o’, ’o’*, ’g’, ’l’, ’e’, rest@(_*)) => rest } |
Этот шаблон используется для поиска последовательности букв "Gogle", "Google", и т.д. Если в z найдено соответствие, функция возвращает то, что осталось после вхождения, в противном случае генерируется ошибка исполнения. Возникающие неоднозначности (например, если в z встречается несколько "Go*gle") разрешаются с использованием политики наиболее длинной правой части (обычно при использовании регулярных выражений это называется политикой жадного поиска, когда выбирается наиболее длинная подстрока, соответствующая шаблону – прим. ред.). В данном примере этому соответствует первое найденное вхождение символов "Gogle" (с одним или несколькими "o").
Поиск по образцу обычно позволяет найти одно вхождение образца. При XML-запросах часто требуется найти все вхождения. Гибкий механизм конструкторов списков, применяемый в Scala, можно использовать для работы с XML в лаконичном и элегантном стиле, сильно напоминающем XQuery. В следующем примере мы выберем все элементы entry из labAddressBook и labPhoneBook в переменные a и p, соответственно. Если содержимое имени двух таких вхождений совпадает, генерируется элемент result, который содержит в качестве дочерних элементов адрес и номер телефона, взятые из соответствующих вхождений.
for (val a <- labAddressBook\\"entry"; val p <- labPhoneBook\\"entry";a\"name"==p\"name") { yield <result>{a.child}{p\"phone"}</result> } |
Язык Scala как таковой не предоставляет никаких примитивов для параллельного программирования. Вместо этого ядро языка создавалось так, чтобы упростить создание библиотек, предоставляющих различные модели параллелизма, строящиеся поверх поточной модели языка-основы. В этом разделе будет продемонстрирована мощь Scala на примере реализации небольшой библиотеки для отказоустойчивых активных объектов, подобных акторам Erlang (Erlang – функциональный язык, предназначенный для конкурентного (многопоточного) программирования, разработанный фирмой Ericsson, и используемый в телекоммуникационных системах этой фирмы – прим.ред.).
Представьте, что вы написали серверный класс MyServer, вызываемый через метод startServer. Scala позволяет сделать этот сервер многопоточным просто смешав его с классом Thread.
class MyConcurrentServer extends Thread with MyServer { override def run() = startServer; } |
Можно обобщить вышеприведенный код в класс (назовем его Process), который может принимать произвольный код и исполнять его в отдельном потоке.
class Process(def body: unit) extends Thread { override def run() = body; } |
Чтобы еще больше упростить порождение новых процессов, можно реализовать функцию spawn в рамках singleton-объекта.
object Process { def spawn(def body: unit) : Process = { val p = new Process(body); p.start(); p } } |
Теперь можно запустить процесс, но как его остановить? Процесс останавливается, когда кончается исполняемый код, то есть когда код в body доходит до конца. Иногда нужно убить процесс, не дожидаясь этого. Это можно сделать, введя метод exit в класс Process, и, для удобства – в singleton-объект Process.
object Process { def spawn(def body: unit) : Process = { val p = new Process(body); p.start(); p } def exit(p: Process, reason: AnyRef) = p.exit(reason); } class Process(def body: unit) extends Thread { private var exitReason: AnyRef = null; override def run() = { try { body } catch { case e: InterruptedException => exitReason.match { case null => Console.println("Process exited abnormally" + e); case _ => Console.println("Process exited with reason:" + exitReason); } } } def exit(reason: AnyRef) : unit = { exitReason = reason; interrupt() } } |
Простой запуск объекта в отдельном потоке еще не делает его активным. Все вызовы методов и обращения к полям из других потоков должны быть синхронизированы – в целях безопасности. Ручное кодирование синхронизации может привести к ошибкам, взаимоблокировкам и неэффективному коду.
Лучший подход к коммуникации потоков – использование обмена сообщениями, т.е. реализация Erlang-подобной модели акторов. В Erlang у каждого актора (или процесса, в терминологии Erlang) есть почтовый ящик, в который другие процессы могут асинхронно посылать сообщения. Процесс, владеющий почтовым ящиком, может выборочно получать сообщения из этого ящика. В Scala можно реализовать почтовые ящики следующим образом:
class MailBox { def send(msg: Any) : unit; def receive[a](f: PartialFunction[Any, a]) : a; def receiveWithin[a](msec: long) (f: PartialFunction[Any, a]) : a; } |
Сообщения помещаются в почтовый ящик методом send. Сообщение удаляется методом receive, который получает процессор сообщения f в качестве аргумента. f – это частичная функция, преобразующая сообщение к некоторому произвольному типу. Обычно эта функция реализуется как выражение сравнения с образцом. Метод receive блокирует поток, пока в почтовом ящике не появится сообщение, для которого определен процессор сообщений. Соответствующее сообщение удаляется из почтового ящика, и заблокированный поток перезапускается с помощью применения процессора сообщений к сообщению. Получатели и отправители сообщений упорядочены по времени, то есть сообщения обрабатываются по мере поступления.
Теперь можно расширить класс Process, смешивая его с классом MailBox.
class Signal extends Message; case class Normal() extends Signal; case class Exit(p: Process, m: Message) extends Message; class Process(def body: unit) extends Thread with MailBox { private var exitReason: AnyRef = null; private var links: List[Process] = Nil; override def run() = try { body; signal(Normal()) } catch { case _ : InterruptedException => signal(exitReason); case exitSignal => signal(exitSignal); } private def signal(s: Message) = links.foreach(p: Process => p.send(Exit(this, s))); def !(msg: Message) = send(msg); def link(p: Process) = links = p::links; def unlink(p: Process) = links = links.remove(p2 => p == p2); def spawnLink(def body: unit) = { val p = new Process(body); p.link(this); p.start(); p } def self = this; def exit(reason: AnyRef) : unit = { exitReason = reason; interrupt() } } |
Чтобы создать отказоустойчивую систему, нужно обязательно уметь обнаруживать сбои в процессах. Этого можно добиться, сделав возможным связывание процессов. Если процесс (A) связан с другим процессом (B), А в момент смерти отправит сигнал B. Это делает возможным отслеживать сбои в процессах и реализовать деревья надзора, где процесс-надзиратель отслеживает рабочие процессы и может в случае сбоя перезапустить их.
Чтобы реализовать это на Scala, придется добавить список на класс Process и предоставить методы связи, а также сигнализации о сбое. Теперь можно создать полноценный класс Process (см.листинг 2)
Класс Process можно использовать для реализации небольшого сервера счетчиков (см. листинг 3). Этот сервер реализует счетчик, значение которого может увеличиваться и считываться посылкой сообщений Increment и GetValue, соответственно. Сам сервер состоит из единственного метода server. Объект Counter предоставляет функциональный интерфейс к процессу-счетчику.
object Counter { class Messages(); case class Increment() extends Messages; case class GetValue(from: Process) extends Messages; case class Stop() extends Messages; case class Value(value: int) extends Messages; def start: Process = spawn(server(0)); def increment(Counter: Process) : unit = Counter ! Increment(); def value(Counter: Process) : Int = { Counter ! GetValue(self); receive { case Value(value) => value } } def stop(Counter: Process) : unit = Counter ! Stop(); private def server(v: int) : unit = { var stop = false; var value = v; while (!stop) { receive { case Increment() => value = value + 1; case GetValue(from) => from ! Value(value); case Stop => stop = true; } } } } |
Каждая компонентная система с мощными конструкциями абстракции и композиции сталкивается с проблемой, когда дело доходит до интеграции подсистем, разработанных различными командами в разное время. Проблема состоит в том, что интерфейс компонентов, разработанных той или иной группой, часто не подходит клиентам, намеренным использовать этот компонент. Рассмотрим, например, библиотеку с классом наподобие GenList, обсуждавшегося выше. Клиент этой библиотеки может захотеть рассматривать такие списки как множества (sets), поддерживающие операции включения членов или проверки вхождения элемента во множество. Однако поставщик класса не предполагал такого сценария использования, и, следовательно, не включил эти методы в интерфейс класса GenList.
Можно сказать, что наследование позволяет клиентам приспосабливать методы класса к своим требованиям; однако это истинно, только если клиент всегда создает экземпляры класса сам. Если библиотека возвращает такие операции как:
def fromArray(xs: Array[T]) : GenList[T]
|
то наследование нельзя использовать, чтобы превратить GenList в SetList после того, как он будет возвращен методом fromArray. Это ограничение можно обойти включением фабричных методов [16] в библиотеки. Но это требует применения весьма сложных фреймворков, и это невозможно в случае библиотечных компонентов.
Эту неудовлетворительную ситуацию называют проблемой внешней расширяемости. Утверждается, что эта проблема не дает превратиться разработке программных компонентов в зрелую промышленную отрасль [22].
Scala представляет новую концепцию решения проблемы внешней расширяемости – виды (views). Они позволяют расширять класс новыми членами и trait-ами. Виды в Scala переводят в объектно-ориентированное представление используемые в Haskell классы типов (type classes). В отличие от классов типов, область видимости видов можно контролировать, причем в разных частях программы могут сосуществовать параллельные виды.
Вид в Scala содержит обычное определение метода. Рассмотрим, например, следующий trait для простого обобщенного множества:
trait Set[T] { def include(x:T): Set[T]; def contains(x:T): boolean } |
Вид на класс Set из класса GenList описывается следующим определением метода (другими словами, описанный ниже вид дополняет класс GenList необходимыми методами так, чтобы его можно было использовать там, где требуется класс Set – прим.ред.):
def view[T](xs: GenList[T]) : Set[T] = new Set[T] { def include(x: T) : Set[T] = x prepend xs; def contains(x: T) : boolean = !isEmpty && (xs.head == x || xs.tail contains x) } |
Следовательно, если xs – это GenList[T], то view(xs) будет возвращать Set[T].
Единственное отличие от обычного определения метода состоит в том, что виды вставляются автоматически компилятором Scala. Скажем, "е" выступает в выражении типа Т. Вид неявно применяется к "е" в одной из двух ситуаций: когда ожидаемый тип "e" – не (супертип) Т, или когда выбранный член "e" не является членом Т. Рассмотрим следующий пример, в котором xs является переменной типа List[T]:
val s: Set[T] = xs;
xs contains x
|
Компилятор вставит в эти строки применения определенного выше вида:
val s: Set[T] = view(xs);
view(xs) contains x
|
Какие виды доступны для вставки? Scala рассматривает в качестве кандидатов все виды, к которым имеется доступ из точки вставки без префиксного выражения. Это включает как виды, определенные локально или в некоторой области видимости, так и виды, унаследованные от базовых классов или импортированные из других объектов выражением import. Локальный вид не прячет виды, определенные в прилегающей области видимости. Вид применим, если он может быть применен к выражению, и он позволяет отобразить это выражение на желаемый тип. Из всех кандидатов Scala выбирает наиболее точно подходящий вид. В данном случае точность интерпретируется так же, как при разрешении перегрузки в Java и Scala. Если применимого вида нет, или среди применимых не удается выбрать подходящий – генерируется ошибка.
Локальность обеспечивается тем ограничением, что в качестве кандидатов рассматриваются только те виды, которые доступны без префикса. Клиенты могут приспосабливать под свои нужды набор доступных видов, выборочно импортируя объекты, определяющие виды.
Виды часто используются в библиотеке Scala, чтобы дать возможность Java-типам поддерживать trait-ы Scala. Примером может служить Scala-trait Ordered, определяющий набор операций сравнения. Виды на этот тип от всех базовых типов и класса String определены в модуле scala.Predef. Поскольку члены этого модуля неявно импортируются в каждую Scala-программу, эти виды всегда доступны. С точки зрения пользователя, это похоже на расширение Java-классов новыми trait-ами.
До сих пор методы видов должны были быть видимы статически в точке вставки. Виды становятся еще более полезными, если можно абстрагироваться от конкретного вставляемого метода. В качестве примера рассмотрим обобщенный метод maximum, возвращающий наибольший элемент непустого списка.
def maximum[T <% Ordered[T]](xs: List[T]) : T = { var mx = xs.head; for (val x <- xs.tail) if (mx < x) mx = x mx } |
У этого метода есть параметр типа, ограниченный конструкцией [T <% Ordered[T]]. Этот параметр типа может быть воплощением любого типа Т, являющегося подтипом Ordered[T], или видимым как Ordered[T]. В частности, можно применить maximum к спискам базовых типов, для которых существуют стандартные виды Ordered.
Заметьте, что применение метода из вида должно быть вставлено в условие x > mx метода maximum. Откуда берется этот метод вида? Поскольку он не известен статически в точке вставки, он должен быть передан как параметр. На самом деле, для каждого ограниченного параметра типа view [t<:T] к списку параметров класса или метода добавляется неявная переменная (view:t => T). При вызове метода или конструктора класса передается конкретный метод вида, подбирающий тип параметра вида. Выбор этого метода вида аналогичен выбору вида при преобразованиях типов, рассматривавшихся в предыдущем разделе.
Например, вызов метода:
maximum(List(1,-3,42,101)) |
будет дополнен до:
maximum(view)(List(1,-3,42,101)) |
где view – это метод, преобразующий int в Ordered[int], и определенный в scala.Predef.
Сами методы видов могут иметь параметры типов. Это позволяет определять условные виды (conditional views). Например, имеет смысл лексикографически сравнивать списки до тех пор, пока тип элемента списка разрешает сравнение. Это выражается следующим методом вида:
def view[T <% Ordered[T]](x: List[T]) = new Ordered[List[T]] { def <(y: List[T]) : Boolean = !y.isEmpty && (x.isEmpty || x.head<y.head || x.head == y.head && x.tail < y.tail) } |
Метод отображает элементы типа List[T] на экземпляры типа Ordered[List[T]], как определено в разделе "Функциональная абстракция", при условии, что сам тип элемента списка T является видимым как Ordered[T].
.Net Framework и JVM во многом схожи – в том, что они оба поддерживают одиночное наследование классов, множественное наследование интерфейсов, самоописываемые типы, ленивую загрузку типов. Кроме того, .Net Framework предоставляет поддержку свойств, атрибутов, типов-значений (структур), перечислений и событий. Хотя Scala и разрабатывалась с оглядкой на Java, ставилась также задача поддержки всех возможностей .NET.
Различия между JVM и .Net начинаются с базовых классов обеих платформ, то есть java.lang.Object и System.Object. Однако Scala абстрагируется от этого и вводит тип scala.AnyRef как корень иерархии ссылочных типов (см раздел Классы). В .Net-версии Scala scala.AnyRef – это псевдоним System.Object, а не java.lang.Object.
java.lang.Object определяет несколько методов, среди которых – знакомые equals, hashCode и toString. В System.Object опредены семантически эквивалентные методы с другими именами. Поскольку scala.AnyRef – это только псевдоним для одного из базовых классов, можно ожидать, что под .Net его методы будут называться так же, как в System.Object. Однако это может расколоть язык Scala и помешать созданию Scala-программ, компилируемых и работающих без изменений на обеих платформах.
В Scala корнем иерархии классов является класс scala.Any, прямой суперкласс scala.AnyRef (см. рисунок 1). В нем уже определены методы equals, hashCode и toString. Это приводит к необходимости трансляции эквивалентных методов System.Object(Equals -> equals, ToString -> toString, GetHashCode > hashCode) для того, чтобы они переопределяли соответствующие методы в scala.Any. Это значит, что, скажем, метод ToString любого .NET-типа доступен как toString из Scala-программы. Более того, определение метода toString в Scala-классе будет переопределять System.Object.ToString.
Метод getClass из java.lang.Object представляет большую проблему совместимости. Он возвращает экземпляр java.lang.Class, который используется в первую очередь для рефлексии. В System.Object определен похожий метод, GetType, но он возвращает экземпляр System.Type, который служит для того же, что и java.lang.Class. Хотя и возможно реализовать getClass для .Net (посредством использования runtime-библиотек JSharp от Microsoft), этот метод считается платформно-зависимым и не присутствует в .Net версии Scala. В Scala на .Net следует использовать родной метод GetType и родные возможности .Net Reflection.
Еще одна возможность, реализованная несколько иначе, чем на обеих платформах – клонирование объектов. В JVM это поддерживается методом clone класса java.lang.Object. Каждый класс, которому требуется клонирование, должен реализовать интерфейс java.lang.Cloneable и переопределить метод clone, если семантики поверхностного копирования, принятой по умолчанию, недостаточно. Однако метод clone не объявлен в интерфейсе Cloneable, и его реализация в классе говорит только о намерении программиста поддерживать клонирование объектов данного класса. С другой стороны, System.Object определяет метод MemberwiseClone, который возвращает поверхностную копию объекта и не может быть переопределен. Клонирование объектов поддерживается путем реализации интерфейса System.ICloneable, объявляющего метод Clone, который должен быть реализован в реализующем классе.
class MyClone with ICloneable { def Clone() : Object = super.MemberwiseClone(); } |
Эти меры позволяют компилировать и исполнять на .NET большинство программ, написанных для JVM. Для улучшения совместимости на уровне кода нужно отобразить многие дополнительные методы java.lang.String на соответствующие методы System.String. Иногда этого нельзя добиться простой трансляцией имени метода. Примером может служить java.lang.String.substring(int, int), принимающий в качестве второго аргумента индекс символа, следующего за искомой подстрокой, в то время, как System.String.Substring(int, int) принимает длину подстроки. В данном случае компилятор Scala генерирует код адаптации, так что никаких изменений программы не нужно. В то же время все методы System.String доступны по своим обычным именам.
val s1 = "1243".substring(1,3)); //"23"; val s2 = "1243".Substring(1,3)); //"234"; |
Свойства в .Net – это механизм уровня метаданных, ассоциирующий пару методов getter/setter с одним общим именем. В C# имеется специальный синтаксис для определения свойств.
public class Celsius { private int d = 0; public int degree { get { returnd; } set { if (value >= -273) d = value; } } } |
В дальнейшем для получения значения свойства используется его имя, как и в случае поля; для задания нового значения используется синтаксис назначения поля:
Celsiusc = new Celsius();
c.degree = c.degree - 1;
|
Scala использует похожую технику в своей трактовке переменных, которые также могут использоваться для определения свойств (см. раздел Переменные и свойства). Методы .Net-свойства getter и setter транслируются в соответствии с соглашениями Scala и могут использоваться как определенные в Scala.
val c = new Celsius; c.degree = c.degree - 1; |
.NET позволяет свойствам иметь параметры (индексированные свойства). В C# они объявляются с помощью особого синтаксиса.
abstract class Map { public abstract Object this[Objectkey] { get; set; } } |
Чтобы предоставить доступ к таким свойствам, C# использует синтаксис индексирования массива.
public void inverse(Mapmap, Objectkey)
{
Objectvalue = map[key];
map[value] = key;
}
|
Такие свойства нельзя, как свойства, лишенные параметров, приспособить с помощью трансляции. Они могут быть транслированы согласно схеме, используемой для реализации массивов в Scala. getter индексированного свойства переименовывается в apply, а setter – в update. Таким образом, с точки зрения Scala класс Map будет выглядеть так:
class Map { def apply(key: AnyRef): AnyRef; def update(key: AnyRef, value: AnyRef) : Unit; } |
И может быть использован сходным c C# образом.
def inverse(map: Map, key: AnyRef) = { val value = map(key); map(value) = key; } |
Определяемые пользователем типы-значения – это возможность, впервые появившаяся в .Net Framework. Объекты типов-значений размещаются в стеке(точнее сказать, размещаемые в стеке или в телах других объектов – прим.ред.), в противоположность ссылочным типам, размещаемым в куче. Они также передаются по значению, когда используются как аргументы методов. Во многих ситуациях, например, в библиотеках коллекций, код рассчитан на работу со ссылочными типами. Конверсия типов-значений в ссылочные типы называется boxing-ом, обратно – unboxing-ом. Как и в C#, компилятор Scala статически определяет потребность в такой конвертации и генерирует соответствующий код.
Понятие типов-значений в Scala не включает в себя определяемые пользователем типы-значения. Следовательно, определять типы-значения .NET в Scala нельзя. Чтобы использовать их в Scala-программах, их придется написать на каком-то другом языке.
Структуры. Типы-значения в .NET являются наследниками System.ValueType. В C# это незаметно, поскольку есть специальный синтаксис определения структур.
struct Point { public Point(int x, int y) { this.x = x; this.y = y; } public int x; public int y; } |
Определенные во внешних сборках .NET структуры могут быть использованы как нормальные ссылочные типы:
def r(p: Point) : double = Math.Sqrt(p.x * p.x + p.y * p.y); def dist(p1: Point, p2: Point) : double = { val p = new Point(p1.x - p2.x, p1.y - p2.y); r(p); } |
Перечисления. В .NET поддерживаются типобезопасные перечисления. Перечисление является наследником System.Enum, который, в свою очередь, наследуется от System.ValueType. Члены перечисления – это именованные константы любого целого типа (int, short и т.д.), кроме char. Каждое перечисление определяет отдельный тип, и его члены нельзя использовать как значения нижележащего типа перечисления; это возможно только с помощью явного приведения типов.
В C# перечисления определяются с помощью специального синтаксиса.
public enum Color
{
Red,
Green,
Blue
}
|
При использовании .NET-перечислений в Scala-коде они расцениваются как ссылочные типы. Их члены видны как статические поля типа перечисления.
class Color extends System.Enum; object Color { val Red: Color; val Green: Color; val Blue: Color; } |
В .NET-сборке эти поля представляются как литералы. Значения литералов фиксированы и хранятся в метаданных сборки, на них нельзя ссылаться во время исполнения. Вместо этого компилятор встраивает (inline) значения, ассоциированные с полями.
Чтобы перечисления были полезными, к ним должны быть применимы некоторые базовые операции, например, операции сравнения (==, !=, <, <=, >, >=) или битовые операции (|, &, ^). Эти операции в типе перечисления выглядят как методы. Они распознаются JIT-компилятором и реализуются как операции над базовыми примитивными типами.
На дизайн Scala оказали влияние многие языки и исследовательские работы, перечислить их все невозможно. Следующее перечисление включает только часть повлиявших на дизайн Scala работ.
Конечно, Scala впитала значительное число концепций и синтаксических соглашений Java [18] и C# [12]. Способ выражения свойств во многом заимствован из Sather [37]. Из Smalltalk [17] взята концепция унифицированной объектной модели. Из Beta [25] пришла идея, что все, включая классы, должно допускать вложенность. Дизайн mixin-ов в Scala восходит к объектно-ориентированным линейным mixin-ам [5], но определяет mixin-композицию симметрично, похоже на mixin-модули [11, 19, 42] или trait-ы [36]. Абстрактные типы в Scala очень похожи на абстрактные типы сигнатур в SML [24] и OCaml [23], обобщенные в контексте полноценных компонентов. For-конструкторы списков (for comprehensions) основаны на монадных включениях Haskell [39], хотя их синтаксис больше напоминает XQuery [2]. Их можно рассматривать как объектно-ориентированную версию параметризованных классов типов [10, 32], но они более общи в том, что декларации экземпляров могут быть локальными и имеют область видимости. Classboxes [1] предоставляют ключевые преимущества видов в динамически типизированных системах. В отличие от видов, они позволяют повторное локальное связывание, так что расширения классов могут выбираться с помощью динамической диспетчеризации.
В некотором смысле Scala – это продолжение работы Pizza [31]. Как и Pizza, Scala компилируется под Java VM, добавляя функции высшего порядка, generic-и и сопоставление с образцом, конструкции, которые исходно были созданы в сообществе функционального программирования. В то время как Pizza обратно совместима с Java, цель Scala – всего лишь возможность взаимодействия, так что у нее больше степеней свободы в дизайне.
Следующая цель Scala – предоставить расширенные конструкции для абстракции и композиции компонентов – общая с несколькими недавними исследовательскими разработками. Абстрактные типы – это более консервативная конструкция для получения многих (но не всех) примуществ виртуальных классов gbeta [13, 14]. Тесно связаны с этим также и слои делегирования (delegation layers) из FamilyJ [34], а также работы над вложенным наследованием в Java [27]. Jiazzi [26] – это расширение Java, добавляющее модульный механизм, основанный на unit-ах, мощной форме параметризованных модулей. Jiazzi поддерживает идиомы расширяемости, похожие на Scala, такие, как возможность реализации mixin-ов.
Язык программирования Nice [3] – это недавно появившийся объектно-ориентированный язык, похожий на Java, но происходящий от ML? [4]. Nice включает множественную диспетчеризацию, открытые классы и ограниченную форму ретроактивной абстракции, основанную на абстрактных интерфейсах. Nice не поддерживает модульную проверку типов на стороне реализации. В то время, как Nice и Scala – это языки, существенно отличающиеся от Java, оба они рассчитаны на взаимодействие с Java-программами и библиотеками, а их компиляторы порождают байт-код Java.
MultiJava – это консервативное расширение Java, которое добавляет симметричную множественную диспетчеризацию и открытые классы. Оно предоставляет альтернативное решение многих проблем, которыми занимается и Scala. Например, множественная диспетчеризация дает решение проблемы бинарных методов, которая в Scala решается абстрактными типами. Открытые классы предоставляют решение проблемы внешней расширяемости, которая в Scala решается с помощью видов. Только в MultiJava встречается возможность динамического добавления новых методов в класс, так как открытые классы интегрированы с обычным процессом динамической загрузки в Java. Напротив, только Scala позволяет определять область видимости внешних расширений класса в программе.
Scala – это одновременно и большой, и относительно маленький язык. Это большой язык в том смысле, что он обладает богатыми синтаксисом и системой типов, комбинирующими концепции объектно-ориентированного и функционального программирования. Следовательно, пользователям, приходящим из любого языкового сообщества, придется изучать новые конструкции. Большая часть разнообразия Scala порождена желанием быть ближе к таким традиционным языкам, как Java и C# – чтобы облегчить принятие Scala пользователями этих языков.
Scala – это также и относительно маленький язык в том смысле, что он построен на скромном наборе весьма общих концепций. Многие конструкции являются синтаксическим сахаром, который может быть удален с помощью трансформации. Такие обобщения, как унифицированная объектная модель, позволяют абстрагироваться от многих примитивных типов и операций, перекладывая работу с ними на плечи библиотеки Scala. Спецификация и реализация Scala также показывают, что ее сложность управляема. Современный frontend компилятора Scala имеет размер, сравнимый с frontend-ом Sun Java 1.4 – мы собираемся существенно уменьшить его, переписав полностью на Scala. Текущая спецификация Scala [29] (около 100 страниц) значительно меньше текущей спецификации Java 1.4 [18] (около 400 страниц). Эти числа трудно сравнивать, однако, поскольку спецификации Scala все еще недостает зрелости спецификации Java, и она использует краткие формулы во многих местах, где спецификация Java использует словесное описание.
Scala была выпущена для общего пользования на платформе JVM в январе 2004 года и на платформе .NET в июне 2004 года. Реализация завершена, за исключением runtime-типов, которые должны появиться в конце 2004 года. В будущем мы собираемся поэкспериментировать с улучшенной систематической поддержкой типов для XML, а также расширить набор стандартных библиотек Scala. Мы также планируем продолжить работу над формализацией ключевых аспектов языка и над разработкой оптимизаций, выполняемых компилятором.
| Оценка 755 Оценить
|
