 Оценка 230
Оценка 230 
 Оценить
Оценить 





| Оценка 230 Оценить
|
Язык XQuery [1] является стандартным языком запросов к данным, хранящимся в формате XML. На сайте консорциума W3C, на сегодняшний день, опубликованы ссылки более чем на 50 различных программных продуктов поддерживающих XQuery. Он используется в качестве встроенного процессора запросов к XML в коммерческих реляционных базах данных, таких как Oracle, IBM DB/2, MS SQL Server, в специализированных XML базах данных вроде Oracle Berkeley XML DB и в виде автономных библиотек для различных платформ, предназначенных для обработки файлов данных. Наиболее известной реализацией такой библиотеки является Saxon [2].
К сожалению, платформа .NET в настоящий момент не имеет встроенной поддержки XQuery. Более того, перечисленные в упомянутом списке реализации либо являются коммерческими продуктами, либо написаны не для платформы .NET. Свободно используемая версия Saxon с открытым исходным кодом написана на Java и для работы в .NET требует использования IKVM.NET [3]. В связи с этим общий объем необходимых сборок для запуска Saxon превышает 30MB. Кроме накладных расходов, связанных с необходимостью применения дополнительных компонентов, этот подход делает проблематичным использование стандартной архитектуры XML-документа, что приводит к снижению производительности и дополнительному расходу памяти.
Следует сказать несколько слов о том, почему компания Майкрософт не реализовала XQuery, ведь пререлиз MSXQuery, датированный где-то 2002 годом, еще можно найти в интернете. Ответ на этот вопрос очень прост и состоит в том, что с точки зрения архитекторов .NET заменой XQuery является технология LINQ-to-XML. Более подробно об этой позиции можно прочитать в блоге Microsoft XML Team’s WebLog [4]. Не вступая в дискуссию с более авторитетными специалистами, все же хотелось бы заметить, что всякий язык запросов, будь то SQL или XQuery, кроме функциональной нагрузки подразумевает еще и декларативную, семантическую часть, облегчающую написание запроса и его восприятие пользователями. Этот самый момент и теряется совершенно при переносе в LINQ сколько-нибудь сложного SQL- либо XQuery-запроса.
Целью настоящей статьи является описание внутренней архитектуры разработанной автором свободно распространяемой библиотеки с открытым исходным кодом QueryMachine.XQuery. Сайт проекта размещен на CodePlex http://qm.codeplex.com/. В настоящий момент эта реализация отвечает требованиям совместимости, предъявляемым стандартом, и успешно проходит опубликованный набор тестов [5]. Код проекта написан на C# и в максимальной степени использует стандартные классы из пространства имен System.Xml.
Если не рассматривать расширения LINQ, то в пространстве имен System.Xml имеется два основных класса для работы с XML-документами – это XmlDocument и XPathDocument.
Широко известный и наиболее часто применяемый класс XmlDocument является реализацией DOM-модели XML-документа как дерева узлов, хранящегося в памяти. Он содержит методы для загрузки и сохранения XML документа, его валидации, манипуляции узлами дерева и выполнения XPath-запросов по содержимому. Собственно говоря, для работы с XML документами ничего большего вроде бы как и не требуется. Однако есть одно существенное обстоятельство. Представление документа в виде дерева, где каждый узел фактически является отдельным объектом, унаследованным от XmlNode, очень и очень неэффективно. Существует оценка (правда, для реализации DOM-модели на Java), в соответствии с которой при загрузке XML-файла размером в 1 мегабайт требуется 8 мегабайт виртуальной памяти, т.е. соотношение размер данных/расход памяти составляет 1 к 8. Кроме того, необходимо учитывать, что на платформах, использующих сборку мусора, т.е в .NET и Java, на производительность всего приложения в целом оказывает влияние количество используемых объектов, попадающих в старшие поколения.
В этом смысле модель DOM является наихудшим вариантом: расход памяти, связанный с необходимостью хранения текстовых данных документа, сочетается с большим количеством связных объектов, представляющих его узлы. Заинтересованные читатели могут сами предпринять небольшое исследование с помощью великолепной программы CLRProfiler.
Справедливости ради следует отметить, что разработчики Майкрософт пошли на всевозможные ухищрения, чтобы сделать реализацию XmlDocument эффективной. Прежде всего, это интернирование строк, представляющих названия элементов и атрибутов с помощью класса XmlNameTable. Поскольку XML-документы обычно имеют осмысленный формат, количество используемых названий и пространств имен ограничено, что и позволяет их хранить в отдельной хэш-таблице, копируя ссылки на одни и те же строки в повторяющиеся узлы.
Далее, собственно класс XmlLinkedNode, являющийся базовым для всех узлов, которые могут включаться в дерево, внутри фактически реализует однонаправленный список элементов. Это позволяет экономить память, но на порядок замедляет навигацию в обратном направлении с помощью свойства XmlNode.PreviousSibling. С этой же целью реализация класса XmlNodeList, используемая при обходе дочерних узлов через свойство XmlNode.ChildNodes, во-первых, создается динамически при каждом обращении к свойству, и, во-вторых, фактически является итератором, хотя и предоставляет доступ к дочернему узлу по номеру. Поэтому использование цикла for вместо foreach для обхода дочерних узлов элемента через свойство XmlNode.ChildNodes приводит к существенной деградации производительности.
Вышеизложенное подводит к мысли, что организация XML-документа в виде дерева является не самой удачной идеей на все случаи жизни. Было бы здорово уметь обрабатывать XML-документы в один проход, вообще не загружая их в память, а навешивая функциональность непосредственно поверх парсинга. К сожалению, в общем случае это вряд ли возможно, хотя такие попытки неоднократно предпринимались [6].
Разработчики .NET решили реализовать менее радикальный способ, который, тем не менее, обеспечивает массу преимуществ. По сути, нам необходима возможность работать с XML-документом как с деревом, но при этом хранить его как можно более эффективно. Этой цели служит абстрактный класс XPathNavigator.
Идея проста. Вместо обхода узлов дерева непосредственно, через модель DOM, используется специальный курсор, позволяющий двигаться по дереву в нужном направлении. При этом внутреннее представление документа остается скрытым от разработчика и может быть как тем же самым XmlDocument (для этого достаточно вызвать метод XmlDocument.CreateNavigator), так и более оптимальным в плане использования памяти. Такое представление для XML-документа как раз и реализует класс XPathDocument.
Именно через интерфейс XPathNavigator в .NET реализован XPath и поддержка XSLT-трансформации. Этот же интерфейс является подходящим для реализации XQuery, и видимо, для этого и задумывался самими разработчиками.
Прежде всего, следует отметить, что в настоящий момент XML-классы .NET не поддерживают XPath 2.0. Поэтому, строго говоря, LINQ-to-XML не является заменой XQuery, хотя бы потому, что функции расширения XPathSelectElement и XPathSelectElements в качестве аргументов принимают выражения XPath 1.0.
Более того, класс XPathDocument не хранит информацию о типизации узлов, делая в принципе невозможным использование функций XPath 2.0 для отбора узлов на основе информации из схемы документов. К счастью, поддержка типизации в виде виртуального свойства XPathNavigator.SchemaInfo имеется и работает, например, для класса XmlDocument.
Пользуясь моментом, хотелось бы конкретизировать, чем отличается XPath 1.0 от XPath 2.0.
Как видно из вышеизложенного, новый XPath существенно усовершенствован и куда сложнее в плане реализации. Требование упорядочивания результатов во многих случаях подразумевает неявную сортировку.
XQuery по большей части является надмножеством языка XPath. Выражения XPath изначально были задуманы как простая нотация для обозначения адресации узлов документа XML, тогда как XQuery включает в себя пролог, функции, переменные, конструкторы и сложные операторы циклов. Этот язык не содержит зарезервированных слов, что позволяет конструкторам данных никогда не пересекаться с зарезервированными словами языка. На практике это означает необходимость комбинировать выражения, адресацию узлов, сопоставление типов и конструкторы, что делает интерпретацию лексем в большой степени зависимой от контекста. Для примера: идентификатор div может обозначать ссылку на элемент или оператор деления. Аналогично, символ * может обозначать групповой символ сопоставления элементов, оператор умножения или суффикс объявления типа [8].
Следующий пример иллюстрирует не слишком красивый, но, тем не менее, синтаксически корректный запрос:
declare namespace namespace = "http://example.com";
declare union <union>for gibberish {
for $for in for return <for>***div div</for>
}</union>,
if(if) then then else else- +-++-**-* instance
of element(*)* * * **---++div- div -div |
XQuery поддерживает широкий набор встроенных типов данных унаследованных от XML-схем, но не является строго типизированным, в том смысле, что допускает объявления безтиповых переменных и функций. Для выполнения эффективных вычислений реализация должна либо проводить глубокий статический анализ запроса с целью определения реальных типов выражений, либо использовать динамическую типизацию при вычислениях (метод, применяемый в современных скриптовых языках [9]).
Еще одной особенностью спецификации XQuery является широкий набор встроенных функций и большое количество арифметических операций над встроенными типами данных [10].
В частности, XQuery позволяет производить арифметические операции над датами и временными интервалами: сложение даты с временным интервалом, вычитание дат, сложение, вычитание, умножение и деление временных интервалов. Причем, как уже отмечалось выше, дата и временной интервал имеют знак. Таким образом, допустимо вычислять временной интервал между текущим моментом времени по Гринвичу, и датой основания Рима, исчисленной до новой эры.
Строковые функции fn:matches, fn:replace и fn:tokenize требуют поддержки регулярных выражений, совместимых с синтаксисом XML-схем [7]. К сожалению, стандартная реализация .NET не вполне отвечает этим требованиям, о чем недвусмысленно свидетельствуют результаты тестирования.
Это же касается преобразования чисел с плавающей точкой в строку. Существующая функция Double.ToString(“E”) выдает недостаточную точность результата по сравнению с классическим алгоритмом Guy L. Steele, Jon L. White [11], на который опираются тесты W3C:
|
Название теста |
Константа |
value.ToString("E") |
Ожидаемый результат |
|---|---|---|---|
|
Literals016 |
65535032e2 |
6.553503E+009 |
6.5535032E9 |
|
Literals017 |
65535.032e2 |
6.553503E+006 |
6.5535032E6 |
|
Literals025 |
-65535.032e2 |
-6.553503E+006 |
-6.5535032E6 |
|
Literals027 |
65535032E2 |
6.553503E+009 |
6.5535032E9 |
|
Literals028 |
65535.032E2 |
6.553503E+006 |
6.5535032E6 |
Это привело к необходимости отдельной реализации преобразований чисел с плавающей точкой в классе XQueryConvert. Алгоритм преобразования идентичен применяемому в Saxon и использует класс BigInteger [12].
Простейшим способом использования XQuery в программе является вызов методов расширения QueryNodes и QuerySingleNode стандартного XmlDocument:
using DataEngine.XQuery;
…
XmlDocument doc = new XmlDocument();
doc.Load("sgml.xml");
XmlNodeList nodes = doc.QueryNodes(@" for $id in //xref/@xrefid return //topic[@topicid = $id]"); |
При таком вызове текущий документ передается в запрос как контекст, а сами методы работают аналогично встроенным SelectNodes и SelectSingleNode.
Более широкие возможности предоставляет класс XQueryCommand:
using (XQueryCommand command = new XQueryCommand())
{
command.BaseUri = "C:\\Work\\vsnet05\\XQuery\\Samples";
command.CommandText = @" declare function local:order-value($po as element(purchase-order)) as xs:double { sum($po/order-item/(@price * @quantity)) }; local:order-value(doc('po.xml')/purchase-order)";
XQueryNodeIterator iter = command.Execute();
foreach (XPathItem item in iter)
{
System.Console.WriteLine(item.Value);
}
} |
С помощью этого класса можно компилировать запрос, устанавливать базовый URL и пути для поиска файлов данных, определять внешние переменные, схемы и модули функций.
Результат выполнения запроса с помощью метода Execute всегда последовательность элементов. Класс, являющийся последовательностью элементов – XQueryNodeIterator. Он аналогичен стандартному XPathNodeIterator.
Элемент последовательности представлен абстрактным классом XPathItem. Это стандартный класс из пространства имен System.Xml.XPath. Свойство XPathItem.IsNode определяет, чем является возвращаемый элемент: узлом или атомарным значением. Если рассматриваемый элемент является узлом, он может быть преобразован к классу XPathNavigator и далее использоваться обычным образом. Если же возвращаемый элемент является атомарным значением, то его строковое представление можно получить через свойство XPathItem.Value, а типизованное значение – через свойство XPathItem.TypedValue.
Большая часть специальных типов XML-схем вроде xs:anyUri обернута в специальные контейнерные классы. Это необходимо для правильной работы типизации XQuery.
Например, рассмотрим типы данных xs:date, xs:dateTime, xs:time. Это различные типы данных, которые могут содержать необязательную временную зону (timezone) [7]. При использовании штатного XmlValidatedReader функция ReadTypedValue возвращает тип System.DateTime, что является неправильным, поскольку для представления даты/времени с указанной временной зоной должен использоваться класс DateTimeOffset. Это происходит из-за особенностей в реализации метода XmlSchemaDatatype.ParseValue. Однако даже DateTimeOffset не вполне подходит, поскольку в соответствии с [7] даты могут иметь знак, и процессор XQuery должен поддерживать соответствующую арифметику.
Аналогичная ситуация происходит с типами xs:decimal и xs:integer. Бинарным представлением обоих типов является System.Decimal. Однако эти типы необходимо различать в операторе instance of, поэтому приходиться вводить дополнительный контейнерный класс DataEngine.CoreServices.Integer.
Следующая таблица определяет соответствие типов XML-схем стандартным типизованным значениям и значениям, используемым этой реализацией XQuery.
|
Тип XML |
XmlSchemaDataType.ParseValue |
XPathItem.TypedValue |
|---|---|---|
|
xs:string (и производные типы) |
System.String |
System.String |
|
xs:untypedAtomic |
System.String |
DataEngine.XQuery.UntypedAtomic |
|
xs:dateTime |
System.DateTime |
DataEngine.XQuery.Util.DateTimeValue |
|
xs:time |
System.DateTime |
DataEngine.XQuery.Util.TimeValue |
|
xs:date |
System.DateTime |
DataEngine.XQuery.Util.DateValue |
|
xs:duration |
System.TimeSpan |
DataEngine.XQuery.Util.DurationValue |
|
xs:yearMonthDuration |
System.TimeSpan |
DataEngine.XQuery.Util.YearMonthDurationValue |
|
xs:dayTimeDuration |
System.TimeSpan |
DataEngine.XQuery.Util.DayTimeDurationValue |
|
xs:float |
System.Single |
System.Single |
|
xs:double |
System.Double |
System.Double |
|
xs:decimal |
System.Decimal |
System.Decimal |
|
xs:integer (и производные типы) |
System.Decimal |
DataEngine.CoreServices.Integer |
|
xs:long |
System.Int64 |
System.Int64 |
|
xs:int |
System.Int32 |
System.Int32 |
|
xs:short |
System.Int16 |
System.Int16 |
|
xs:byte |
System.SByte |
System.SByte |
|
xs:unsignedLong |
System.UInt64 |
System.UInt64 |
|
xs:unsignedInt |
System.UInt32 |
System.UInt32 |
|
xs:unsignedShort |
System.UInt16 |
System.UInt16 |
|
xs:unsignedByte |
System.Byte |
System.Byte |
|
xs:gYearMonth |
System.DateTime |
DataEngine.XQuery.Util.GYearMonthValue |
|
xs:gYear |
System.DateTime |
DataEngine.XQuery.Util.GYearValue |
|
xs:gMonthDay |
System.DateTime |
DataEngine.XQuery.Util.GMonthDayValue |
|
xs:gMonth |
System.DateTime |
DataEngine.XQuery.Util.GMonthValue |
|
xs:gDay |
System.DateTime |
DataEngine.XQuery.Util.GDayValue |
|
xs:boolean |
System.Boolean |
System.Boolean |
|
xs:base64Binary |
byte[] |
DataEngine.XQuery.Util.Base64BinaryValue |
|
xs:hexBinary |
byte[] |
DataEngine.XQuery.Util.HexBinaryValue |
|
xs:anyUri |
System.String |
DataEngine.XQuery.Util.AnyUriValue |
|
xs:QName |
XmlQualifiedName |
DataEngine.XQuery.Util.QNameValue |
|
xs:NOTATION |
XmlQualifiedName |
DataEngine.XQuery.Util.NOTATIONValue |
Типизованное атомарное значение контейнерного типа может быть преобразовано к примитивным типам данных с помощью методов XPathItem.ValuesAs, XPathItem.ValueAsBoolean, XPathItem.ValueAsInt, XPathItem.ValueAsLong, XPathItem.ValueAsDouble, XPathItem.ValueAsDateTime.
Как уже было показано выше, внутреннее представление XML-документа является критическим фактором производительности и ресурсоемкости приложения. Встраиваемый процессор XQuery, на взгляд автора, должен быть компактным, достаточно производительным и расходовать минимальное количество памяти. Тем не менее, в процессе выполнения запроса могут обрабатываться достаточно большие файлы данных. Кроме того, конструкторы элементов в некоторых ситуациях порождают большие объемы промежуточных данных, не используемые в дальнейшем.
Нужно отметить, что большинство современных реализаций XQuery, да и вообще большинство кода, работающего с XML, используют стратегию, основанную на первоначальной загрузке всего документа в программу с его последующей обработкой. Такой подход является нонсенсом для любого разработчика реляционной базы данных, но почему-то считается вполне нормальным в мире XML. Обе стандартные реализации XML-документа XmlDocument и XPathDocument также предполагают первоначальную загрузку, хотя и организуют хранение с разной степенью эффективности.
На самом деле, при использовании курсора XPathNavigator считывать весь документ целиком при открытии вовсе не обязательно. Ниже будет показано, как реализовать потоковое чтение документа с буферизацией таким образом, чтобы не считывать сразу все данные.
Рассмотрим следующий запрос, который вычисляет сумму DOW первых 10 элементов FLIGHT файла input.xml:
unordered
{
let $r :=
(
for $i in 1 to 10
return (doc("input.xml")//FLIGHT)[$i]
)
return sum($r/DOW)
} |
При стандартном методе загружается файл целиком, несмотря на то, что требуется всего лишь его фрагмент. И это первая причина, по которой для XQuery хотелось бы иметь реализацию XML-документа, отличную от стандартной.
Еще одной причиной является необходимость хранения информации о типах элементов при использовании XmlValidatedReader, поскольку XPathDocument эту информацию не хранит.
Затем, для правильной работы XQuery требуются дополнительные контейнерные типы для поддержки атомарных значений. Было бы удобно сразу получать правильные данные, обращаясь к свойству XPathNavigator.TypedValue.
И наконец, очень хочется применить что-нибудь из арсенала реляционных баз данных, с тем, чтобы сделать соотношение объем данных/занимаемая память более приемлемым. Другими словами, свести древовидную структуру данных XML-документа к какому-нибудь табличному представлению.
Это не новая идея. Она успешно реализована в MonetDB [13]. Однако подход, используемый Pathfinder, требует реляционной базы и SQL. Поэтому попробуем посмотреть на проблему проще.
На самом деле, если развернуть XML в виде какой-нибудь псевдо-реляционной структуры, то дальше код XPathNavigator сможет динамически представлять ее как дерево. А к табличной структуре можно применить хорошо известную страничную организацию и виртуализовать ее по мере чтения в виде промежуточного файла на диске, не загружая документ в память целиком.
Проще говоря, можно просто писать вывод XmlReader в таблицу, и ничего больше. Такая таблица может иметь, например, такой вид:
|
№ |
Название поля |
Тип поля |
Комментрий |
|---|---|---|---|
|
1 |
NodeType |
XmlNodeType |
Тип узла (начало элемента, атрибут и пр). |
|
2 |
Perfix |
String |
Префикс узла (если есть) |
|
3 |
LocalName |
String |
Локальное имя |
|
4 |
NamespaceUri |
String |
URI |
|
5 |
Value |
String |
Значение (если есть) |
|
6 |
SchemaInfo |
IXmlSchemaInfo |
Информация о типе элемента |
К сожалению, все не так просто. Чем проще промежуточное представление, тем большая вычислительная нагрузка на реализацию XPathNavigator. В нашем случае получается, что документ как бы разбирается два раза: сначала с помощью XmlReader, а затем - XPathNavigator, каждый раз при движении по дереву. К тому же, если эту таблицу записывать на диск (а в оперативной памяти такое представление куда менее эффективно, чем стандартное), то добавятся накладные расходы, связанные с дисковыми операциями.
И тем не менее, идея очень заманчива. Ведь если не обращать внимание на эффективность, именно линейное представление обеспечивает потоковую обработку XML, т.е. возможность обхода фрагментов документа, не помещая его целиком в оперативную память. При движении курсора можно либо загружать запись из уже готовой таблицы, если соответствующий узел уже был прочитан, либо просто вызывать XmlReader.Read и обновлять таблицу.
Кроме того, при линейном представлении каждый узел XML документа оказывается естественно упорядоченным и имеет уникальный номер, что очень важно при сортировке результатов выполнения XPath-выражений, а также обеспечивает простое индексирование документа для оптимизации или выполнения функций fn:id и fn:idref.
В несколько измененном виде описанный подход оказывается вполне работоспособным. На самом деле нам требуется обеспечить две вещи: минимизировать объем обращений к диску и сделать так, чтобы движение по уже прочитанному документу не требовало существенных вычислений.
В первую очередь нужно выделить возможные типы узлов в отдельные классы пространства имен DataEngine.XQuery.DocumentModel: DmRoot, DmElement, DmAttribute, DmComment, DmPI и DmText и интернируем их с помощью System.Collections.Generic.Dictionary<> на каждом уровне вложенности. Эти объекты представляют структуру документа и создаются по мере чтения файла. Каждый узел в модели документа имеет уникальное название и тип XSD внутри родительского узла. Объекты модели остаются постоянно загруженными в оперативную память и используются в качестве ключей в таблице узлов документа. Это теоретически позволяет выполнять вычисления простейших XPath-выражений с помощью линейного поиска в ограниченном диапазоне таблицы узлов, поскольку есть возможность определить множество ключей, которые удовлетворяют заданному выражению.
Например, рассмотрим файл purchaseOrder.xml:
<?xml version="1.0" encoding="UTF-16"?> <po:purchaseOrder orderDate="2001-01-01" xmlns:po=http://www.ibm.com xmlns:xsi=http://www.w3.org/2001/XMLSchema-instance xsi:schemaLocation="http://www.ibm.com PurchaseOrder.xsd"> <shipTo country="US"> <name>Alice Smith</name> <street>125 Maple Street</street> <city>Mill Valley</city> <state>CA</state> <zip>90952</zip> </shipTo> <billTo country="US"> <name>Robert Smith</name> <street>8 Oak Avenue</street> <city>Old Town</city> <state>PA</state> <zip>95819</zip> </billTo> <po:comment>Hurry, my lawn is going wild!</po:comment> <items> <item partNum="872-AA"> <productName>Lawnmower</productName> <quantity>1</quantity> <USPrice>148.95</USPrice> <po:comment>Confirm this is electric</po:comment> </item> <item partNum="926-AA"> <productName>Baby Monitor</productName> <quantity>1</quantity> <USPrice>39.98</USPrice> <shipDate>2001-07-21</shipDate> </item> </items> </po:purchaseOrder> |
Модель документа для него будет иметь вид:
DmRoot
po:purchaseOrder [http://www.ibm.com]
@orderDate []
@xsi:schemaLocation [http://www.w3.org/2001/XMLSchema-instance]
{
shipTo []
@country []
{
name [] (mixed)
street [] (mixed)
city [] (mixed)
state [] (mixed)
zip [] (mixed)
}
billTo []
@country []
{
name [] (mixed)
street [] (mixed)
city [] (mixed)
state [] (mixed)
zip [] (mixed)
}
po:comment [http://www.ibm.com] (mixed)
items []
{
item []
@partNum []
{
productName [] (mixed)
quantity [] (mixed)
USPrice [] (mixed)
po:comment [http://www.ibm.com] (mixed)
shipDate [] (mixed)
}
}
} |
Простейшее XPath-выражение //item/quantity будет соответствовать единственному объекту DmElement quantity в модели документа. Поэтому при вычислениях достаточно просканировать таблицу узлов для поиска всех элементов, имеющих необходимый ключ.
Остальная информация об узле XML-документа, в том числе его значение и позиция родителя, оборачивается в классы XdmDocument, XdmElement, XdmProcessingInstruction, XdmWhitespace и XdmText. Эти классы играют роль полей данных в нашей таблице и имеют виртуальные методы Load и Store для сохранения в промежуточном файле. Атрибуты XdmAttribute и объявления пространств имен XdmNamespace являются частью элементов, в которых они находятся. Также в одну запись таблицы узлов сворачиваются пустые XML-элементы, которые являются листьями дерева документа, и элементы, содержащие только текстовые данные.
Для исключения чрезмерно частого сканирования таблицы узлов необходимо создать индекс, хранящий информацию о следующих узлах того же уровня (ось ::following-sibling). Этот индекс заполняется по мере обработки XML-документа.
Резюмируя сказанное, получаем класс, представляющий страницу промежуточного файла:
private
class Page
{
internalint num; // номер страницы internallong offset; // смещение в промежуточном файле internalint pin; // счетчик обращений для управления кэшированием internalbool stored; // признак, записана ли страница на дискinternal XdmNode[] nodes; // фрагмент таблицы узлов internalint[] next; // информационный массив ::following-siblinginternalint[] hindex; // индексы модели документа
…
} |
Экземпляры класса Page остаются в оперативной памяти. Для вытеснения содержимого страницы на диск элементы массива nodes сериализуются, после чего ссылка на массив обнуляется.
Массив hindex содержит дескрипторы узлов модели документа, соответствующие элементам массива nodes. Поскольку модель документа и индекс не выгружаются на диск, при вычислениях XPath-выражений чтение промежуточного файла может потребоваться лишь при обращении к текстовым значениям и атрибутам элементов.
Управление страничным файлом реализовано в классе PageFile. Наиболее часто используемые страницы остаются в оперативной памяти. Если размер исходного документа невелик, то этот файл вообще не создается. Запись в страничный файл происходит в фоновом режиме при помощи функции ThreadPool.QueueUserWorkItem.
Собственно, страничный XML-документ реализуется классом XQueryDocument в связке с XQueryNavigator и XQueryDocumentBuilder.
Рассмотрим тестовый набор четырех XML-документов, имеющих следующие характеристики:
|
Характеристика |
input.xml |
input2.xml |
auctions.xml |
book.xml |
|---|---|---|---|---|
|
Размер файла |
220 MB |
11 MB |
1 MB |
1,4 KB |
|
Количество элементов count(doc('input.xml')//*) |
12 055 489 |
152 128 |
17 132 |
37 |
|
Количество узлов XdmNode в таблице документа |
33 559 875 |
306 091 |
46 269 |
98 |
Следующая таблица отражает сравнительные характеристики усредненного времени загрузки XML-документов с помощью классов XmlDocument, XPathDocument и XQueryDocument:
|
Класс (x64, Intel Q9550, 8GB RAM) |
Рабочий набор |
Время загрузки |
Рабочий набор |
Время загрузки |
Рабочий набор |
Время загрузки |
Рабочий набор |
Время загрузки |
|---|---|---|---|---|---|---|---|---|
|
input.xml |
input2.xml |
auctions.xml |
book.xml |
|||||
|
XmlDocument |
1.3 GB |
12430 ms |
91 MB |
587 ms |
20 MB |
24,09 ms |
- |
0,35 ms |
|
XPathDocument |
700 MB |
8781 ms |
61 MB |
383 ms |
20 MB |
23,12 ms |
- |
0,34 ms |
|
XQueryDocument |
150 MB |
11739 ms |
35 MB |
592 ms |
23 MB |
59 ms |
- |
0,81 ms |
Из приведенной таблицы видно, что XQueryDocument на файле большого объема потребляет в 8 раз меньше памяти, чем DOM-модель документа, и при этом загружается быстрее. В сравнении с XPathDocument, загрузка происходит на 25% медленнее и требует в 4 раза меньше памяти.
На маленьких файлах рассматриваемое представление XML-документа уступает стандартному по всем параметрам, что на самом деле вполне закономерно, так как в процессе чтения производится большое количество дополнительных действий. Однако этот фактор не является критическим, поскольку время загрузки, в большинстве случаев, пренебрежимо мало относительно общего времени выполнения запроса.
Также заметим, что, запросы XQuery можно выполнять с использованием XmlDocument и XPathDocument, или любой другой реализации XPathNavigator. С этой целью в проект добавлены обертки XQueryNavigatorWrapper и XPathNavigableWrapper, которые обеспечивают поддержку необходимых контейнерных типов в свойстве TypedValue. Именно эти классы используются методами расширения QueryNodes и QuerySingleNode для передачи XmlDocument как контекста в запрос XQuery.
Как уже отмечалось выше, запросы XQuery являются в большой степени контекстно-зависимым и не содержат зарезервированных слов. Грамматика XQuery является частью стандарта и описана в виде форм Бэкуса-Наура (БНФ). Для предотвращения конфликтов в ней используется расширенный набор первичных лексем, обычно соответствующих операторам языка. Например, “declare namespace”, “declare default collation” и многие другие операторы пролога трактуются как единые символы: DECLARE_NAMESPACE, DECLARE_DEFAULT_COLLATION и пр. Для символа *, употребляемого в контексте объявления типа, также определяется отдельная лексема. Это позволяет свести грамматику к общеупотребительной LR(1), однако резко усложняет сканнер, на который переносится логика распознавания контекста. Сканер XQuery реализован классом Tokenizer, и представляет собой конечный автомат, в соответствии с рекомендациями W3C [8]. Наличие свойств CurrentPos, CurrentLength и методов GetState и RevertToState позволяет использовать его не только при трансляции запросов, но и в других приложениях, например, для подсветки синтаксиса XQuery.
Для парсинга применяется алгоритм таблично-управляемого восходящего анализа, генерируемого утилитой jay. Этот инструмент идентичен классическому yacc и используется, например, в проекте Mono для реализации компилятора C#. Правила грамматики вручную приведены к каноническому виду, который предполагает отсутствие метасимволов и операторных скобок, для того, чтобы грамматика могла компилироваться jay. Более подробно о классических методах построения трансляторов и yacc можно прочитать в великолепной монографии [14]. Теория также неплохо изложена в [15]. Сгенерированный код находится в классе YYParser. Для удобства работы, по аналогии со стандартным MSDataSetGenerator для схем данных, написан небольшой плагин для Visual Studio, JaySourceGenerator, который осуществляет генерацию при записи файла грамматики в редакторе VS.
Стандарт XQuery требует реализации функций fn:id и fn:idref, которые позволяют осуществлять навигацию в XML-документе по атрибутам и элементам (!), имеющим тип значений ID и IDREF, если таковые определены в его схеме. К сожалению, стандартные объекты платформы .NET не имеют никаких опубликованных интерфейсов для работы со схемами документа в виде классических DTD. Поэтому в данную реализацию XQuery дополнительно встроен собственный парсер DTD, который, не особо мудрствуя, использует ту же технологию по грамматике, опубликованной в стандарте XML [16]. Эта логика реализована в классе DTDParser.
Существенную роль в архитектуре любого транслятора играет внутреннее представление семантики исходного языка, генерируемое в процессе синтаксического разбора. Язык XQuery предполагает циклические вычисления, и требует статического анализа выражений, а возможно, и последующей оптимизации. Поэтому запрос не может выполняться прямо во время разбора, как это иногда удается сделать в простейших случаях, и требуется подбирать какие-то структуры данных, в которые будет преобразован его текст.
Для внутреннего представления транслируемого кода обычно применяются классические деревья выражений [15], либо их более новая модификация, называемая AST-деревьями (Abstract Syntax Tree). Деревья выражений не совсем удобны в том смысле, что являются достаточно простыми структурами и в определенной степени загромождают код, а AST-деревья требуют законченной архитектуры всего приложения уже на этапе синтаксического разбора и, таким образом, не позволяют выделить парсер в изолированный функциональный блок. Кроме того, обычно создается отдельный вид узлов AST-дерева для каждой синтаксической конструкции, и при достаточно объемной грамматике (а грамматика XQuery содержит 391 правило и 156 терминальных символов) вручную трудно написать нужное количество классов.
Рассматриваемая реализация XQuery не использует деревья для внутреннего представления запросов. Вместо этого предлагается организация данных, которую наиболее точно можно охарактеризовать как семантический граф. Она более наглядна, чем классические деревья выражений, и предоставляет удобную нотацию для выполнения трансляции. Эта организация данных представлена классом Notation.
Суть этого подхода состоит в том, что вместо построения деревьев описываются выражения языка как отношения между специально генерируемыми в процессе синтаксического разбора символами.
Рассмотрим фрагмент кода, который осуществляет синтаксический разбор запроса из строковой константы с последующим выводом на консоль его внутреннего представления.
Notation notation = new Notation(); TokenizerBase tok = new Tokenizer( @"let $i := 1, $j := 2 return $i * 2 + j"); YYParser parser = new YYParser(notation); StringWriter sw = new StringWriter(); parser.yyparseSafe(tok); notation.Dump(sw); System.Console.WriteLine(sw.ToString()); |
Результатом его работы будет следующее:
FilterExpr(_Expr3, 1) LetClauseOperator(_Expr4, $:i, null, _Expr3) FilterExpr(_Expr7, 2) LetClauseOperator(_Expr8, $:j, null, _Expr7) Let(_Expr9, (_Expr4 _Expr8)) FilterExpr(_Expr11, $:i) FilterExpr(_Expr13, 2) Mul(_Expr14, _Expr11, Token.ML, _Expr13) AxisStep(_Expr17, j) Add(_Expr18, _Expr14, Token.'+', _Expr17) FLWORExpr(_Expr20, (_Expr9), null, null, _Expr18) Query(_Module1, null, (_Expr20)) Root(_Module2, _Module1) |
Функторы отношений Root, FLWORExpr, Add,… определены в программе как элементы перечисления Descriptor. Идентификаторы с подчеркиванием динамически сгенерированы в процессе разбора и соответствуют экземплярам нетерминальных символов грамматики. Терминальные символы, соответствующие строковым и числовым литералам, возвращаются сканнером в виде экземпляров классов Literal, IntegerValue, DoublelValue, DecimalValue, и выводятся без подчеркивания. Круглые скобки в аргументах обозначают списки и будут рассматриваться в следующем разделе.
Свертка правила грамматики приводит к определению нового символа и добавлению в Notation отношения с помощью метода Confirm (фрагмент файла XQuery.y):
TypeswitchExpr
: TYPESWITCH '(' Expr ')' CaseClauseList DEFAULT RETURN ExprSingle
{
$$ = notation.Confirm(new Symbol(Tag.Expr), Descriptor.Typeswitch, $3, $5, $8);
}
| TYPESWITCH '(' Expr ')' CaseClauseList DEFAULT '$' VarName RETURN ExprSingle
{
$$ = notation.Confirm(new Symbol(Tag.Expr), Descriptor.Typeswitch, $3, $5, $8, $10);
}
; |
Отношения хранятся в виде таблицы записей Record в экземпляре класса Notation:
public
class Record
{
public Symbol sym; // левый символ для удобства поискаpublic Descriptor descriptor; // отношение publicobject[] args; // остальные аргументы
} |
Также определены несколько основных методов для отбора записей из этой таблицы:
public Record[] Select(Symbol sym);
public Record[] Select(Symbol sym, Descriptor desc, int arity);
public Record[] Select(Descriptor desc, int arity);
public Record[] Select(Symbol sym, int arity);
public Record[] Select(Symbol sym, Descriptor[] descs, int arity);
public Record[] Select(Symbol sym, Descriptor desc, int arity, object[] args); |
Рассматриваемый семантический граф может быть преобразован к дереву выражений с помощью рекурсивного обхода. Базой рекурсии будет выступать отношение Root, а шагом рекурсии будет замещение сгенерированных символов на соответствующие им отношения.
Аналогичным образом работает и сам транслятор, который как бы развертывает внутреннее представление в обратную сторону от корневого символа _Module2 относительно целевой грамматики. При этом шаг трансляции удается привести к предикатной форме, т.е. ограничиться запросами: “Определено ли отношение FLWORExpr/5 для символа _Expr9?”. Если да, то обрабатываем правило для FLWORExpr, иначе переходим к обработке ORExpr.
Определение элементов перечисления Descriptor при написании приложения выбирается произвольно, из соображений удобства использования, и обычно соответствует исходной грамматике, в несколько более сжатом виде.
Для проверки работы синтаксического анализа написан класс XQueryWriter, который преобразует представления запроса обратно в текст XQuery. Собственно отладка грамматики состояла в парсинге запроса с его последующим преобразованием обратно в текст. Результат такого преобразования должен совпадать с исходной версией за исключением пробелов и других символов-разделителей.
Следующий фрагмент кода иллюстрирует использование класса Notation методом XQueryWriter.WriteTypeswitch для генерации оператора typeswitch (предполагается, что в параметре rec передается отношение Typeswitch/3 или Typeswitch/4):
public
virtual
void WriteTypeswitch(Notation.Record rec)
{
WriteText("typeswitch (");
WriteExpr(rec.args[0]);
WriteText(")");
Symbol[] arr = Lisp.ToArray<Symbol>(rec.args[1]);
for (int k = 0; k < arr.Length; k++)
{
Notation.Record[] recs = notation.Select(arr[k], new Descriptor[] {
Descriptor.Case });
if (recs.Length > 0)
{
WriteText(" case ");
if (recs[0].args.Length > 2)
{
WriteText('$');
WriteVarName((VarName)recs[0].Arg0);
WriteText(" as ");
WriteSequenceType(recs[0].Arg1);
WriteText(" return ");
WriteExprSingle(recs[0].Arg2);
}
else
{
WriteSequenceType(recs[0].Arg0);
WriteText(" return ");
WriteExprSingle(recs[0].Arg1);
}
}
}
if (rec.args.Length > 3)
{
WriteText(" default $");
WriteVarName((VarName)rec.Arg2);
WriteText(" return ");
WriteExprSingle(rec.Arg3);
}
else
{
WriteText(" default return ");
WriteExprSingle(rec.Arg2);
}
} |
Как видите, метод Notation.Select позволяет определить, какое именно из правил было применено при синтаксическом разборе, и проанализировать аргументы, с тем, чтобы сгенерировать ветвь оператора case нужного вида: с определением промежуточной переменной или без него. Методы WriteExpr, WriteVarName, WriteExprSingle соответствуют правилам грамматики для нетерминальных символов Expr, VarName, ExprSingle.
Таким образом, выбранный подход к представлению семантики запроса делает код XQueryWriter наглядным и по структуре похожим на саму грамматику. Кроме того, синтаксический разбор полностью изолирован от остальных частей, что позволило приступить к написанию транслятора, имея готовый и отлаженный парсер.
Для представления выражений XQuery используется концепция списков Lisp [17]. Список Lisp – это однонаправленный список, элементами которого могут быть значения, атомы или другие списки. Атомы Lisp – это уникальные имена, обозначающие переменные, функции или другие идентификаторы при вычислениях.
Для записи списков в языке Lisp приняты специальные соглашения: cписки заключаются в круглые скобки, а их элементы разделяются пробелами. Атомы обозначаются идентификаторами, а строковые литералы заключаются в апострофы. Например:
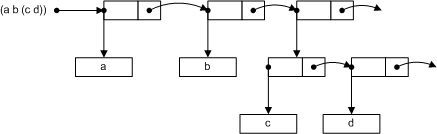
(1 2 3, ‘four’) – обозначает список чисел 1, 2, 3 и строки four;
(a b (c d)) – обозначает список, состоящий из трех элементов: атомов a и b, и вложенного списка, содержащего атомы c и d.
Списки строятся с помощью специальных структур, называемых cons-узлами (cons – от англ. consolidation – прим.ред.). Cons-узел содержит два указателя, традиционно называемые «голова» и «хвост». В Lisp для обозначения функций, возвращающих хвост и голову списка, традиционно используются названия car и cdr, соответственно. (Не ищите в этих названиях какого-то смысла. Просто так исторически сложившилось – прим.ред.) Каждому элементу списка соответствует свой cons-узел. В этой паре «голова» указывает на элемент списка, а хвост – на cons-узел следующего элемента списка. Любая «голова» может указывать как на элемент, так и на вложенный список. «Хвост» последнего элемента списка равен null.
Нотация списков может использоваться для записи композиций функций. В этом случае название функции является атомом и записывается как первый элемент списка:
f(x, g(x, y)) -> (f x (g x y))
1 + 2 * 2 -> (+ 1 (* 2 2))
Такая запись является частным случаем Lisp-формы. Под Lisp-формой обычно подразумевается соглашение о формате списка для представления какого-либо выражения. Например, условный оператор на языке Lisp записывается как (cond (<условие> <значение>) … (t <значение по умолчанию>)). На вид это выражение выглядит как обычная функция, но на самом деле вычисляется по специальным правилам: каждая пара (<условие> <значение>) является ветвью условного перехода и обрабатывается аналогично оператору switch/case/default на языке C#.
Классический Lisp является интерпретатором списков, рекурсивно вычисляющим функциональные выражения по следующим правилам:
Поддержка списков в проекте реализована как набор статических методов класса Lisp. Внутри этого класса определены внутренние классы CONS и ATOM, представляющие cons-узел и атом Lisp.
Атомы создаются с помощью функции DefAtom. В отличии от обычных реализаций, имя атома может иметь префикс, по аналогии с именами XML-элементов. Атомы подразделяются на глобальные и локальные. Глобальные атомы используются для связывания встроенных функций и определены для всего приложения, а локальные – для связывания переменных в контексте текущего запроса. В классе Lisp определены две хэш-таблицы, которые обеспечивают уникальность имен используемых атомов таким образом, что повторное использование одного и того же идентификатора означает использование единственного объекта ATOM. Такое разделение на разные категории позволяет периодически очищать таблицу локальных атомов, удаляя не используемые объекты.
Программный интерфейс для работы со списками максимально приближен к набору функций, обычно используемых в языке Lisp. Поэтому как такового класса «список», представляющего экземпляр этого типа данных, нет. Предполагается, что в качестве элементов списков могут выступать любые объекты .NET, и поэтому все статические методы класса Lisp принимают аргументы типа System.Object. Класс CONS скрыт, а доступ к элементам списка происходит посредством традиционных функций акссесоров: Car, Cdr, Nth, Nthx. Также имеется функция Format для представления списков в виде строковых выражений Lisp и класс LispParser для преобразования строковых выражений в списки.
Вот пример кода, использующий списки:
object l = Lisp.List(1, 2, ¨1111¨);
l = Lisp.Append(l, Lisp.Cons(4));
System.Console.WriteLine(l); // Результат: (1 2 “1111” 4)
System.Console.WriteLine(Lisp.Car(l)); // Результат: 1
System.Console.WriteLine(Lisp.Cdr(l)); // Результат: (2 “1111” 4)
System.Console.WriteLine(Lisp.Car(Lisp.Cdr(l))); // Результат: 2 |
В процессоре XQuery класс Lisp также используется для определения списков символов в отношениях семантического представления запроса (фрагмент XQuery.y):
Expr
: ExprSingle
{
$$ = Lisp.Cons($1);
}
| Expr ',' ExprSingle
{
$$ = Lisp.Append($1, Lisp.Cons($3));
}
; |
Функциональные формы в виде списков Lisp могут не только интерпретироваться, но и компилироваться непосредственно в байт-код MSIL. Для этого достаточно развернуть композицию функций в стек, т.е преобразовать функциональную форму в обратную польскую нотацию, аналогично алгоритму «сортировочной станции» Эдскера Дейкстра [18].
Например, форма (+ 4 (* 2 (- 3))) в постфиксной записи будет выглядеть как
4 2 3 - * + |
В качестве стека вычислений может быть использован стек CLI, который позволяет оперировать как примитивными типами данных (int, double и пр.), так и вообще любыми объектами CTS [19]. Атомы, представляющие имена функций в списках, могут быть сопоставлены инструкциям байт-кода или вызовам методов классов.
Для компиляции Lisp также необходим стек, с помощью которого будет отслеживаться тип аргументов транслируемой функции. Например, любая функция, реализующая арифметические операции должна поддерживать разные аргументы, соответствующие основным используемым при вычислениях типам данных. Более того, компилятор должен поддерживать простейшие преобразования в случае, если операнды имеют разные типы. Это приводит к необходимости реализации механизма, обычно называемого перегрузкой операций.
Результатом компиляции Lisp-выражения будет динамический метод System.Reflection.Emit.DynamicMethod, прикрепленный к классу CompiledLamda, который будет вызван в дальнейшем для выполнения вычислений. Вызов метода производится функцией Invoke этого класса.
Рассмотрим простейший запрос XQuery:
1+ 2.2 * 4 |
По правилам языка XQuery, числа 1 и 4 имеют тип xs:integer, а число 2.2 тип xs:decimal. Как уже было описано в предыдущих разделах, типу xs:integer соответствует CoreServices.Integer, а xs:decimal – System.Decimal.
Транслятор XQuery преобразует это выражение в Lisp-выражение:
(+ 1 (* 2.2 4)) |
В этой форме числовые значения уже имеют нужный тип данных. Для упрощения понимания рассмотрим следующий код на C#, который строит нужную нам форму:
CoreServices.Integer a = 1; Decimal b = 2.2; CoreServices.Integer b = 4; object expr = Lisp.List(Funcs.Add, a, Lisp.List(Funcs.Mul, b, c)); System.Console.WriteLine(expr); // результат: (+ 1 (* 2.2 4)) |
Таким образом, задача компилятора Lisp состоит в том, чтобы сгенерировать поток инструкций, который будет помещать в стек константы, выполнять необходимые преобразования типов и собственно вычислять значения. Получающийся результат показан ниже:
ldc.i4.1
newobj System.Decimal::.ctor(System.Int32 value)
newobj DataEngine.CoreServices.Integer::.ctor(System.Decimal value)
ldc.i4.s 22
ldc.i4.0ldc.i4.0ldc.i4.0ldc.i4.1conv.u1newobj System.Decimal::.ctor(System.Int32 lo, System.Int32 mid, System.Int32 hi, System.Boolean isNegative, System.Byte scale)
ldc.i4.4newobj System.Decimal::.ctor(System.Int32 value)
newobj DataEngine.CoreServices.Integer::.ctor(System.Decimal value)
.local 0: DataEngine.CoreServices.Integer
stloc DataEngine.CoreServices.Integer (0)
ldloc DataEngine.CoreServices.Integer (0)
call System.Decimal DataEngine.CoreServices.Integer::op_Explicit(DataEngine.CoreServices.Integer i1)
call System.Decimal System.Decimal::op_Multiply(System.Decimal d1, System.Decimal d2)
.local 1: System.Decimal
stloc System.Decimal (1)
call System.Decimal DataEngine.CoreServices.Integer::op_Explicit(DataEngine.CoreServices.Integer i1)
ldloc System.Decimal (1)
call System.Decimal System.Decimal::op_Addition(System.Decimal d1, System.Decimal d2)
box System.Decimal
ret |
Важнейшим аспектом компиляции выражений является связывание значений, т.е. загрузка в стек значений переменных, обозначаемых атомами. Поиск значения по хэш-таблице во время вычислений является неприемлемым из соображений производительности. Кроме того, при использовании динамических методов без генерации промежуточной сборки нет возможности определять внутренние переменные. Это значит, что единственный реальный способ передачи значений в динамический метод – это использование его аргументов.
Задачу связывания значений решает класс SymbolLink. Он содержит всего два важных свойства: само значение Value и его тип Type, поскольку на момент компиляции это значение может быть еще не определено. Фактически этот класс реализует логический указатель на значение. Компилятор при первом обходе выражения находит по хэш-таблице экземпляры SуmbolLink, соответствующие переменным. Каждая найденная ссылка затем добавляется в специальный массив. Далее перед компиляцией выражения генерируется пролог, который принимая указанный массив как аргумент динамической функции, резервирует и заполняет локальные переменные, соответствующие каждой связи. Таким образом, передача значения переменной осуществляется через свойство SymbolLink.Value.
Для иллюстрации сказанного рассмотрим запрос:
let $a := 2 return $a * 2 |
Выполнение этого запроса сводится к вычислению выражения:
(* $.a 2) |
Это выражение транслируется в следующий MSIL-код:
.local 0: DataEngine.CoreServices.Integer ldarg.0call DataEngine.CoreServices.SymbolLink[] DataEngine.CoreServices.CompiledLambda::get_Values() .local 1: DataEngine.CoreServices.SymbolLink[] stloc DataEngine.CoreServices.SymbolLink[] (1) ldloc DataEngine.CoreServices.SymbolLink[] (1) ldc.i4.0ldelem.refcall System.Object DataEngine.CoreServices.SymbolLink::get_Value() isinst DataEngine.CoreServices.Integer dupbrfalse .label_0 unbox.any DataEngine.CoreServices.Integer stloc DataEngine.CoreServices.Integer (0) br.s .label_1 .label_0: popcall DataEngine.CoreServices.Undefined DataEngine.CoreServices.Undefined::get_Value() ret .label_1: ldloc DataEngine.CoreServices.Integer (0) ldc.i4.2newobj System.Decimal::.ctor(System.Int32 value) newobj DataEngine.CoreServices.Integer::.ctor(System.Decimal value) call DataEngine.CoreServices.Integer DataEngine.CoreServices.Integer::op_Multiply(DataEngine.CoreServices.Integer i1, DataEngine.CoreServices.Integer i2) box DataEngine.CoreServices.Integer ret |
Представленный код состоит из двух частей: пролога и вычисления выражения.
В прологе определяется локальная переменная local_0. Она выделена для хранения значения переменной XQuery $a и имеет тип Integer. Затем в стек помещается указатель экземпляра класса CompiledLambda и вызывается его метод для получения значения свойства Values. В этом свойстве находится массив указателей на экземпляры SymbolLink, которые соответствуют переменным, используемым в компилируемом выражении. Код в прологе устанавливает переменную local_0, попутно проверяя правильность типа данных, находящегося в SymbolLink.Value. Если фактический тип значения не соответствует объявленному во время компиляции, функция возвращает специальное значение Undefined.Value. Этот механизм используется для обработки пустых последовательностей как операндов в выражениях и будет рассмотрен ниже. Собственно вычисление выражения далее происходит обычным образом с участием переменной local_0.
Кроме атомов в выражениях Lisp могут встречаться константы. Для примитивных типов, таких как целые числа, MSIL предусматривает набор инструкций ldc для загрузки константных значений в стек. Однако для объектных типов данных таких возможностей нет. В случае класса Integer, как видно из приведенных выше листингов, с помощью специального конструктора сначала создается System.Decimal. В общем случае, экземпляры объектов, выступающие как константы в выражениях, помещаются в специальный массив Consts, который, аналогично массиву связанных переменных Values, сохраняется в классе CompiledLambda и передается через аргументы динамического метода. Правильность типов данных в этом случае не проверяется и локальная переменная не создается.
Компилятор Lisp реализован в классе Executive. Вычисление выражения осуществляется функцией Apply. В качестве параметров она принимает вычисляемое выражение и SymbolLink, куда помещается получившийся CompiledLambda. Таким образом, поддерживается компиляция выражения «на лету», при первом вычислении формы. С помощью Apply также возможно вычислять лямбда-выражения, т.е. производить связывание параметров в выражении. Для компиляции выражения без последующего вычисления используется метод Compile. Перед компиляцией осуществляется раскрытие макросов Lisp.
В качестве Lisp-функции может использоваться любой статический метод объекта или делегат. Для этого достаточно зарегистрировать нужный тип с помощью метода DefineStaticOperator.
Следующий пример кода показывает вычисление Lisp-выражения, использующего переменные и вызов методов объекта Inner:
public
static
class Inner
{
publicstaticdouble Method1(string a)
{
return Convert.ToDouble(a,
System.Globalization.CultureInfo.InvariantCulture);
}
publicstaticdouble Method1(string a, int b)
{
return Method1(a) + b;
}
}
void Test()
{
object a = Lisp.Defatom("a");
object f = Lisp.Defatom("f");
SymbolLink link = new SymbolLink(typeof(System.Int32));
link.Value = 4;
object expr = Lisp.List(Funcs.Add, |
Здесь мы определили переменную, обозначенную атомом «a», создали для нее ссылку SymbolLink типа System.Int32 и присвоили ей значение. Далее связали статические методы класса Inner с атомом f и произвели некоторые вычисления.
Механизм компиляции Lisp-форм является компактным и эффективным средством выполнения динамических вычислений в приложении. Представление выражений в виде списков позволяет осуществлять их анализ для определения типа результата уже после трансляции фрагмента запроса, что упрощает код транслятора.
Основным типом данных в языке XQuery является последовательность.
Скалярные типы данных, рассматриваемые в примерах предыдущего раздела, с точки зрения логики языка на самом деле являются последовательностями, содержащими один элемент. Чтобы в этом убедиться, достаточно выполнить запросы “1[1]” и “1[2]”. Также процессор XQuery должен уметь корректно обрабатывать пустые последовательности. Например, вполне допустимо выражение “() * 2[1] + 1”. В этом случае, как и вообще при арифметических вычислениях, результатом будет пустая последовательность (то есть результата не будет вообще). Однако это не распространяется на случай, когда такое выражение является аргументом функции, которая может обрабатывать пустые последовательности, например, “count(() * 2[1] + 1)”. В случае, когда эта самая функция не может обрабатывать пустые последовательности, система должна генерировать исключение. Результаты вычисления XPath-выражений, естественно, тоже являются последовательностями.
Выбранный способ реализации последовательностей является фундаментом архитектуры всего процессора XQuery. С точки зрения обработки скалярных значений, самый эффективный способ реализации последовательностей – это обойтись без них вовсе, преобразуя скалярное выражение в последовательность там, где это действительно нужно. Последовательности, содержащие несколько элементов, должны быть организованы как итераторы, т.е. вычисления должны происходить по ходу перебора элементов. Иначе простейший запрос “sum(1 to 10000000)” немедленно израсходует всю память в нашей программе. Однако необходимость потоковой обработки приводит к тому, что запрос, представленный в виде Lisp-формы, не может быть вычислен, так сказать, «за один раз».
Чтобы объяснить суть проблемы, рассмотрим выражение “2+2,2*2”. Можно либо вычислить его сразу, сохранив результат в памяти и построив по нему последовательность, либо отложить вычисления и вернуть класс, задачей которого будет обрабатывать каждый элемент во время обхода последовательности. Следуя терминологии Michael Kay, две эти стратегии можно назвать Pull и Push. Эта реализация XQuery использует стратегию отложенных вычислений во всех случаях, не требующих сортировки результатов.
Для представления запроса XQuery определен базовый класс XQueryExprBase:
public
abstract
class XQueryExprBase: IBindableObject
{
publicabstractvoid Bind(Executive.Parameter[] parameters);
publicabstract IEnumerable<SymbolLink> EnumDynamicFuncs();
publicvirtualbool IsContextSensitive(Executive.Parameter[] parameters);
publicabstractobject Execute(IContextProvider provider, object[] args);
public XQueryContext QueryContext { get; };
publicobject ToLispFunction();
} |
Этот класс абстрагирует как таковое выражение XQuery. От него унаследованы классы XQueryExpr – реализация оператора последовательности, XQueryFLWORBase – операторы for и let, XQueryPathExpr – вычисления выражений XPath, XQueryFilterExpr – фильтрация последовательностей, XQuerySorter – сортировка результатов FLWOR выражений.
Таким образом, запрос XQuery транслируется в программе в дерево вложенных классов XQueryExprBase, которые связаны между собой в списковых формах. Эта организация похожа на планы выполнения SQL-запросов в реляционных СУБД, где в качестве шага исполнения выступает экземпляр XQueryExprBase.
Для примера рассмотрим запрос:
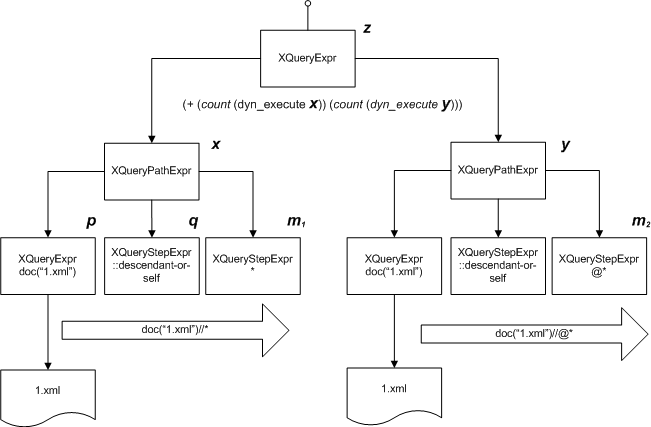
count(doc("1.xml")//*) + count(doc("1.xml")//@*) |
Результат трансляции в виде схемы может быть представлен так:
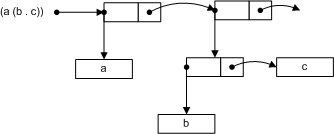
Для выполнения запроса XQueryCommand вызывает метод Execute у верхнего XQueryExpr, обозначенного на схеме буквой z. Lisp-форма внутри представляет собой сложение результатов двух встроенных функций fn:count для подсчета количества элементов последовательности и всегда возвращает единственное число. Поэтому код метода немедленно компилирует и вычисляет эту форму. Аргументом функции fn:count является результат выполнения специальной служебной функции dyn_execute. Ее задача – это вызов метода Execute у подвыражений, производных от класса XQueryExprBase, которые передаются ей как константы в аргументе. В данном случае подвыражениями являются классы XQueryPathExpr, предназначенные для обработки XPath. На схеме они обозначены как x и y. Вызов методов Execute у этих классов создаст итераторы последовательностей XQueryNodeIterator, которые попадут в функцию fn:count. Для подсчета количества элементов в каждой из последовательностей код функции осуществит их перебор, что приведет к обходу документа в соответствии с заданными выражениями XPath.
Класс XQueryPathExpr выполняет обработку выражений XPath, организуя его шаги (XPath steps в терминологии стандарта [1]) в виде конвейера выражений, где каждый элемент последовательности, порождаемый текущим выражением, становиться контекстом для последующего. Другими словами, класс x строит декартово произведение шагов p, q и m. Также XQueryPathExpr выполняет сортировку результатов, полученных на шаге m1 и m2, если статический анализ выражения XPath показывает, что результат может быть неупорядоченным или содержать дубликаты узлов документа. При этом учитывается необходимость упорядочивания, заданная блоком ordered/unorderd или оператором declare ordering. Если упорядочивать результаты не требуется, вместо буферизации с последующей сортировкой используется хэш-таблица, с помощью которой проверяется уникальность возвращаемых значений.
Каждый из элементов этого конвейера может быть как специализированным классом XQueryStepExpr, который предназначен для навигации с отбором узлов по осям XPath, так и обычным выражением XQueryExpr или XQueryFilterExpr. В приведенном примере такое выражение обозначено буквой p и содержит вызов функции fn:doc.
Еще один пример – это запрос с сортировкой:
for $i in 1 to 5 order by $i mod 3 descending return $i |
Дерево запроса в данном случае имеет более простой вид:
Как видно на схеме, использование оператора сортировки в выражении FLWOR приводит к созданию промежуточного класса XQuerySorter, задача которого – буферизация и сортировка последовательности, полученной на шаге y, по ключам, определенным в запросе. Класс XQueryFLWOR (шаг y) циклически вызывает p, изменяя текущее значение переменной цикла и выстраивая получившиеся результаты в одну последовательность. Сами ключи вычисляются одновременно со значениями, возвращаемыми оператором return на шаге p. Сформированный кортеж оборачивается в класс XQueryWrappedValue, и в таком виде попадает на шаг x, где разворачивается после выполнения сортировки. Результатом вычислений, получающимся на шаге z, будет последовательность, представленная классом XQueryNodeIterator.
Реализация операторов for и let также требует дополнительной настройки механизма связывания в Lisp, поскольку для локальных переменных, определенных с их помощью, необходимо обеспечивать поддержку областей видимости. Это означает, что переменные должны быть видимы только в выражениях, находящимися внутри самого оператора, и, возможно, будут переопределены внутри. Кроме того, названия локальных переменных могут еще конфликтовать с переменными, определенными в прологе запроса, или названиями параметров, если соответствующий оператор используется внутри функции.
Чтобы выстроить локальные переменные по областям видимости, компиляция всех Lisp-форм производится одномоментно, рекурсивным спуском по дереву выражений. При этом обработка каждого выражения происходит по следующему алгоритму: сохраняем текущую таблицу атомов, определяем новые локальные переменные, выполняем компиляцию вложенных выражений, а затем восстанавливаем первоначальные связи. Управление таблицей связей осуществляется с помощью класса XQueryResolver, который определен в контексте всего запроса.
Компиляция и связывание переменных производится в виртуальном методе XQueryExprBase.Bind. Для выражений, находящихся внутри списков, вызов Bind происходит автоматически, при обработке объекта как константы формы, если реализован интерфейс IBindableObject. Также в этом интерфейсе имеется метод EnumDynamicFuncs, через который публикуются все используемые в классе Lisp-формы, что позволяет производить их обход «сверху вниз» во время статического анализа выражения.
Такого рода анализ применяется, например, для проверки, не содержит ли объявление переменной в прологе запроса циклической ссылки на саму себя или для анализа условия фильтрации последовательности. Если условие не зависит от текущего контекста, то его вычисление можно производить один раз до обработки элементов самой последовательности. В противном случае фильтр необходимо вычислять при отборе каждого элемента.
Язык XQuery допускает объявление переменных и функций без указания фактического типа значения. Кроме того, при обработке XML-документов, типизованных с помощью схемы данных, фактический тип данных выражения XPath может быть неопределенным, т.е. различаться у разных элементов. Например, в запросе:
import schema namespace po="http://www.ibm.com" at
"purchaseOrder.xsd";
for $n in doc("purchaseOrder.xml")//(quantity | USPrice)
return $n + 1 |
переменная $n будет иметь тип значения xs:positiveInteger для элементов quantity и xs:decimal для элементов USPrice. Аналогичный пример легко построить с функцией, объявленной без указания типов значений:
declare function local:f($v)
{
$v * 2
};
local:f(2), local:f(2e-01) |
В первом случае аргумент функции – целое число типа xs:integer, и результат вычисления – тоже xs:integer, а во втором случае аргумент – это число xs:double, и результатом вычислений будет также xs:double. Таким образом, у нас имеется ситуация, когда тип операндов арифметических выражений не определен. С другой стороны, во многих случаях тип переменной объявлен или может быть вычислен явным образом из выражения:
let $n := 2 return $n * $n |
В этом запросе тип переменной $n не указан, но определяется однозначно типом присваиваемой константы.
Чтобы не усложнять реализацию и выполнять вычисления эффективно, компилятор Lisp использует следующую стратегию для арифметических операций и сравнений:
Поддержка динамического выполнения арифметических операций реализована в классе OperatorManager. В отличии от статического выполнения, когда преобразования типов и вызов операции происходят один раз при компиляции, при динамическом выполнении сопоставление и преобразование операндов делается при каждом обращении. Кроме того, в этом случае необходима постоянная упаковка (boxing) результатов, поскольку тип возвращаемого значения является System.Object. Поэтому вычисления с неопределенными типами значений происходят значительно медленнее.
Компилятор Lisp так же имеет встроенную форму cast, которая идентична преобразованию типа в языке C#. Использование этой формы приводит к изменению типа операнда в стеке трансляции и проверке соответствия типа в стеке вычислений. Таким образом обеспечивается возможность, указав типы явно, добиться того, чтобы компилятор порождал высокопроизводительный статически типизированный код.
Для правильной обработки пустых последовательностей, которые могут возникать в элементах, не имеющих текстовых значений, в реализацию Lisp также добавлены формы trap и lambda-quote. Форма trap прерывает вычисление выражения и возвращает аргумент формы как результат вычислений, т.е. работает как оператор return в языке C#. Форма lambda-quote создает внутреннее лямбда-выражение и обеспечивает продолжение вычислений в выражении в случае вызова формы trap. Этот механизм логически работает как обработка исключений, где форма trap играет роль оператора throw, а lambda-quote блока try/catch и используется вместо исключений по соображениям производительности, например при атомизации XQuery.
Под атомизацией значений в языке XQuery подразумевается преобразование XML-элемента к строке, являющейся его значением, перед выполнением арифметических операций и сравнений. Например:
<a>2</a> + 2 |
Атомизация в запросе реализуется с помощью макроса atomize. Обработка макроса приводит к форме, имеющей вид:
(+ (cast-to-number1 (let ((y (atomize# <a>2</a>))) |
В этой форме вызывается статический метод Core.Atomize, обозначенный как atomize#. Его возвращаемое значение сравнивается со специальным значение Unknown.Value. Это значение используется в процессоре XQuery для обозначения пустой последовательности как результата вычислений. Далее, при получении пустой последовательности вызывается форма trap, которая исключает дальнейшее выполнение операций. В противном случае результат преобразуется к xs:double и складывается.
Следует обратить внимание на то, что приведенный пример не использует динамические вычисления, поскольку на каждом шаге тип выражения известен при компиляции. Этого эффекта удается добиться применением формы trap, которая гарантирует строковый тип значения результата атомизации. Описанный выше прием применяется и при вычислении аргументов функций. Причем, если функция допускает пустую последовательность в качестве аргумента, то форма trap не используется.
Кроме атомизации, с помощью промежуточных функций преобразования осуществляется продвижение типов (type promotion) и подстановка типов (subtype substitution) как это описано в стандарте. Абстракция типа данных XQuery реализована в классе XQuerySequenceType, а код для выполнения преобразований – в XQueryConvert. Этот класс устроен аналогично System.Convert, но работает с XML-типами данных.
Свойство XQuerySequenceType.Cardinality определяет возможное количество элементов в последовательности типа данных XQuery. Следующая таблица показывает отношение между перечислением XmlTypeCardinality, спецификатором типа в запросе и фактическим типом переменной или аргумента функции при компиляции:
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Транслятор XQuery выбирает преобразование типов, исходя из анализа выражения, таким образом, чтобы в максимальной степени задействовать статические вычисления.
declare namespace wmh = "http://www.wmhelp.com/ext"; declare function wmh:doc($name as xs:string?, |
[XQuerySignature("doc", NamespaceUri="http://www.wmhelp.com/ext", Return = XmlTypeCode.Node, Cardinality = XmlTypeCardinality.ZeroOrOne)] publicstaticobject GetOpenXmlDocument( [Implict] Executive engine, [XQueryParameter(XmlTypeCode.String, Cardinality=XmlTypeCardinality.ZeroOrOne)] string name, [XQueryParameter(XmlTypeCode.String, Cardinality=XmlTypeCardinality.ZeroOrOne)] string id) { XQueryContext context = (XQueryContext)engine.Owner; string filename = context.GetFileName(name); if (filename == null) thrownew Exception(String.Format("File {0} is not found", name)); string ext = Path.GetExtension(filename); ContentKey key = new ContentKey(name, id); XQueryDocument doc; if (context.ExtraProperties.ContainsKey(key)) doc = (XQueryDocument)context.ExtraProperties[key]; else { if (ext == ".docx") doc = OpenDocx(context, filename, id); elseif (ext == ".xlsx") doc = OpenXlsx(context, filename, id); elsethrownew Exception(String.Format("File {0} is unknown type. Supported .docx & .xlsx file types", name)); context.ExtraProperties.Add(key, doc); } return doc.CreateNavigator(); } |
Приведенная выше функция GetOpenXmlDocument первым делом проверяет, не кэшировано ли содержимое запрашиваемого файла, так как в запросе XQuery один и тот же файл может использоваться несколько раз. Для этой цели в XQueryContext предусмотрена таблица ExtraProperties, которая позволяет ассоциировать произвольные ключи и значения в контексте запроса.
Класс ContentKey представляет собой обычный составной ключ для хэш-таблицы:
private
class ContentKey
{
publicstring FileName { get; private set; }
publicstring PartID { get; private set; }
public ContentKey(string filename, string id)
{
FileName = filename;
PartID = id;
}
publicoverridebool Equals(object obj)
{
ContentKey other = obj as ContentKey;
if (obj != null)
return other.FileName == FileName &&
other.PartID == PartID;
returnfalse;
}
publicoverrideint GetHashCode()
{
return (FileName.GetHashCode() << 6) ^ PartID.GetHashCode();
}
} |
Далее функция GetOpenXmlDocument анализирует расширение запрашиваемого файла и вызывает связанную с ним функцию чтения данных. Прочитанный документ помещается в таблицу ExtraProperties. Результатом выполнения этой функции будет XPathNavigator установленный на корневой узел XML-документа.
Для реализации функций чтения документов OpenDocx и OpenXlsx нам потребуется Open XML SDK 2.0 для Microsoft Office, который можно скачать на сайте компании Майкрософт. Ниже приведен код для функции OpenXlsx:
private
static XQueryDocument OpenXlsx(XQueryContext context, |
Здесь мы открываем файл Xlsx средствами SDK и получаем XML-документ по id. В случае, когда id равен пустой строке, возвращается основной XML-документ, соответствующий рабочей книге Excel. Далее его содержимое загружается в класс XQueryDocument и возвращается в основную функцию.
Внимательный читатель заметит, что в приведенном примере никак не предусмотрена обработка пустых последовательностей в качестве аргументов. Тем не менее, этот пример будет работать правильно, поскольку при определении функций используется несколько простых соглашений по передаче аргументов, которые учитываются транслятором XQuery:
Функции XQuery, определенные в прологе запроса или во внешнем модуле, компилируются и оборачиваются в класс LambdaExpr, а также регистрируются в таблице XQueryFunctionTable. Тип нестрогих аргументов принимается за item(). Таким образом, с точки зрения транслятора между функциями, определенными в программе, и пользовательскими функциями в запросе нет никакой разницы.
Представленная реализация пока далека от совершенства и в некоторых случаях значительно уступает коммерческим продуктам, поскольку не имеет законченного оптимизатора. Тем не менее код исключительно компактен, совместим со стандартом и может быть легко адаптирован к прикладной задаче, а применение компиляции в MSIL позволило добиться приличной производительности методом «грубой силы». Этот проект изначально не задумывался как коммерческий и имел целью опробовать некоторые идеи в области трансляции и функциональных вычислений. Техника представления XML-документов носит экспериментальный характер, и возможно, будет развиваться в следующей версии вместе с оптимизацией вычислений XPath.
Компилятор Lisp и графы для представления семантики успешно применялись автором в других местах, в частности для реализации SQL. Надеюсь, что затрагиваемые вопросы будут интересны широкому кругу специалистов, интересующихся технологиями XML.
| Оценка 230 Оценить
|
