Здравствуйте, Ночной Смотрящий, Вы писали:
НС>Здравствуйте, Доктор ТуамОсес, Вы писали:
ДТ>>А какое это всё имеет отношение к тому, что был ли Джобс мразью или нет?
НС>Никакого. Еще вопросы есть?
Тогда зачем Вы обсуждаете это в теме, посвящённой тому, какой же мразью был Джобс?
Здравствуйте, Ночной Смотрящий, Вы писали:
НС>Здравствуйте, IID, Вы писали:
IID>>Разверни подробнее. И с примерами (реальными, а не сферическими в вакууме).
НС>Примеров я тебе тут уже приводил. Спектрумовский вариант — синтаксический. Ты же сам пишешь, что даже не AST хранится, а голые токены. VB, Python, .NET, Java — это уже разной степени подробности семантические структуры.
А причём тут AST ? Сдаётся мне что ты на ходу придумываешь определения байткода. Вот пример определения из педивикии:
Bytecode, also known as p-code (portable code), is a term which has been used to denote various forms of instruction sets designed for efficient execution by a software interpreter as well as being suitable for further compilation into machine code. Since instructions are processed by software, they may be arbitrarily complex, but are nonetheless often akin to traditional hardware instructions; virtual stack machines are the most common, but virtual register machines have also been built.[1] Different parts may often be stored in separate files, similar to object modules, but dynamically loaded during execution.
The name bytecode stems from instruction sets which have one-byte opcodes followed by optional parameters. Intermediate representations such as bytecode may be output by programming language implementations to ease interpretation, or it may be used to reduce hardware and operating system dependence by allowing the same code to run on different platforms. Bytecode may often be either directly executed on a virtual machine (i.e. interpreter), or it may be further compiled into machine code for better performance.
Unlike human-readable source code, bytecodes are compact numeric codes, constants, and references (normally numeric addresses) which encode the result of parsing and semantic analysis of things like type, scope, and nesting depths of program objects. They therefore allow much better performance than direct interpretation of source code.
Спектрумовская реализация попадает под это определение идеально. Поэтому интереса спорить о корректности определений больше не имею.
IID>>Парсинг токенов в 48к был сделан за счёт оригинальной схемы набора.
НС>Не всех. Выражения типа 1+2-3 таки парсились по честному.
Числа не парсились. А свёртка арифметических выражений это уже оптимизация. В байткоде LUA, например, такой свёртки нет.
НС>>>Ну и, возвращаясь к началу, в БК была примерно такая же схема, может чуть погибче. IID>>В чём гибче ?
НС>Больше допускалось вариаций в плане синтаксиса.
Здравствуйте, IID, Вы писали:
IID>Bytecode, also known as p-code (portable code), is a term which has been used to denote various forms of instruction sets designed for efficient execution by a software interpreter as well as being suitable for further compilation into machine code. Since instructions are processed by software, they may be arbitrarily complex, but are nonetheless often akin to traditional hardware instructions; virtual stack machines are the most common, but virtual register machines have also been built.
Выделил жирным. Обрати внимание.
IID>Unlike human-readable source code, bytecodes are compact numeric codes, constants, and references (normally numeric addresses) which encode the result of parsing and semantic analysis of things like type, scope, and nesting depths of program objects. They therefore allow much better performance than direct interpretation of source code.
А это про то, что требование семантики я на ходу придумал.
Вобщем, читай внимательнее то, что сам цитируешь.
IID>Спектрумовская реализация попадает под это определение идеально.
Совсем не попадает. Это не instruction set, он совсе не akin to hardware и не выполняет семантического анализа.
НС>>Не всех. Выражения типа 1+2-3 таки парсились по честному.
IID>Числа не парсились. А свёртка арифметических выражений это уже оптимизация.
Я не про свертку. А про то, что выражения хранились as is практически, но потом интерпретатор их парсил (тогда было принято преобразовывать в обратную польскую запись, но как конкретно в спекки я хз).
В р-коде, кстати, выражения записываются либо в виде дерева, либо в виде инструкций стековой машины, уже упорядоченные по приоритету и ассоциативности операторов. Чего в спектруме, разумеется, не было.
Здравствуйте, Ночной Смотрящий, Вы писали:
НС>Здравствуйте, IID, Вы писали:
IID>>Bytecode, also known as p-code (portable code), is a term which has been used to denote various forms of instruction sets designed for efficient execution by a software interpreter as well as being suitable for further compilation into machine code. Since instructions are processed by software, they may be arbitrarily complex, but are nonetheless often akin to traditional hardware instructions; virtual stack machines are the most common, but virtual register machines have also been built.
НС>Выделил жирным. Обрати внимание.
Первое — выполняется. Второе — опциональное.
IID>>Unlike human-readable source code, bytecodes are compact numeric codes, constants, and references (normally numeric addresses) which encode the result of parsing and semantic analysis of things like type, scope, and nesting depths of program objects. They therefore allow much better performance than direct interpretation of source code.
НС>А это про то, что требование семантики я на ходу придумал. НС>Вобщем, читай внимательнее то, что сам цитируешь.
Типы (число/строка/массив) анализируются. Прекалькуляция переменных во внутреннее представление. А scope и nesting depths в принципе отсутствуют. Какой ещё семантический анализ ты хочешь в ключе синклер-бейсика ?
IID>>Спектрумовская реализация попадает под это определение идеально.
НС>Совсем не попадает. Это не instruction set,
Токены бейсика вполне себе инструкции.
НС>он совсе не akin to hardware
Это опционально.
НС>и не выполняет семантического анализа.
в какой-то мере выполняет.
НС>>>Не всех. Выражения типа 1+2-3 таки парсились по честному.
IID>>Числа не парсились. А свёртка арифметических выражений это уже оптимизация.
НС>Я не про свертку. А про то, что выражения хранились as is практически, но потом интерпретатор их парсил (тогда было принято преобразовывать в обратную польскую запись, но как конкретно в спекки я хз).
Калькулятор (так называлась FP подсистема спектрум-бейсика, доступная по однобайтовому рестарту) был стековый, как и современные FPU.
НС>В р-коде, кстати, выражения записываются либо в виде дерева, либо в виде инструкций стековой машины, уже упорядоченные по приоритету и ассоциативности операторов. Чего в спектруме, разумеется, не было.
Это не обязательно.
Здравствуйте, IID, Вы писали:
IID>Первое — выполняется.
Нет, не выполняется.
IID> Второе — опциональное.
Оно там все — опционально. Термин размытый. Но де-факто никто поток токенов р-кодом не называет.
НС>>А это про то, что требование семантики я на ходу придумал. НС>>Вобщем, читай внимательнее то, что сам цитируешь.
IID>Типы (число/строка/массив) анализируются.
Нет. Только в момент исполнения.
IID> Прекалькуляция переменных во внутреннее представление.
Это не прекалькуляция. Это даже не парсинг. Это исключительно лексический анализ. Т.е. даже до обработки синтаксиса нетерминалов дело не доходит.
НС>>Совсем не попадает. Это не instruction set, IID>Токены бейсика вполне себе инструкции.
Нет. Под инструкциями здесь понимается процессороподобный низкоуровневый набор, а не обработанные лексером ключевые слова ЯВУ.
НС>>и не выполняет семантического анализа. IID>в какой-то мере выполняет.
В какой? Хотя бы один пример?
IID>Это не обязательно.
Обязательно. Это самое самое начало семантического анализа, а с современных языках им вообще парсер до семантики занимается. Собственно, в спектруме очень очень мало работы выполняется при сохранении строки программы. То, что там вообще хоть какой то эффект наблюдается — это в силу крайней примитивности и дохлости Z80.
Ну и самое главное — в БК было абсолютно то же самое, только без хитрой клавиатуры. Строка при сохранении парсилась по честному, из набора символов. Но в результате в памяти хранилось примерно то же самое, что и в спектруме. Так что твой пассаж про то, что якобы крутой 1801ВМ1 работал медленнее из за отсутствия препарсинга даже близко не соответствует действительности. Да, тормоза при выводе текста — это из-за графической подсистемы — текстовый режим там был чисто программный, аппаратный знакогенератор отсутствовал как класс. В отличие от синклера.
Здравствуйте, Ночной Смотрящий, Вы писали:
НС>Здравствуйте, IID, Вы писали:
IID>>Первое — выполняется.
НС>Нет, не выполняется.
IID>> Второе — опциональное.
НС>Оно там все — опционально. Термин размытый. Но де-факто никто поток токенов р-кодом не называет.
НС>>>А это про то, что требование семантики я на ходу придумал. НС>>>Вобщем, читай внимательнее то, что сам цитируешь.
IID>>Типы (число/строка/массив) анализируются.
НС>Нет. Только в момент исполнения.
IID>> Прекалькуляция переменных во внутреннее представление.
НС>Это не прекалькуляция. Это даже не парсинг. Это исключительно лексический анализ. Т.е. даже до обработки синтаксиса нетерминалов дело не доходит.
НС>>>Совсем не попадает. Это не instruction set, IID>>Токены бейсика вполне себе инструкции.
НС>Нет. Под инструкциями здесь понимается процессороподобный низкоуровневый набор, а не обработанные лексером ключевые слова ЯВУ.
НС>>>и не выполняет семантического анализа. IID>>в какой-то мере выполняет.
НС>В какой? Хотя бы один пример?
IID>>Это не обязательно.
НС>Обязательно. Это самое самое начало семантического анализа, а с современных языках им вообще парсер до семантики занимается. Собственно, в спектруме очень очень мало работы выполняется при сохранении строки программы. То, что там вообще хоть какой то эффект наблюдается — это в силу крайней примитивности и дохлости Z80. НС>Ну и самое главное — в БК было абсолютно то же самое, только без хитрой клавиатуры. Строка при сохранении парсилась по честному, из набора символов. Но в результате в памяти хранилось примерно то же самое, что и в спектруме. Так что твой пассаж про то, что якобы крутой 1801ВМ1 работал медленнее из за отсутствия препарсинга даже близко не соответствует действительности. Да, тормоза при выводе текста — это из-за графической подсистемы — текстовый режим там был чисто программный, аппаратный знакогенератор отсутствовал как класс. В отличие от синклера.
а какое это всё имеет отношение к тому что джобс был конченой мразью?
Здравствуйте, Ночной Смотрящий, Вы писали:
НС>Обязательно. Это самое самое начало семантического анализа, а с современных языках им вообще парсер до семантики занимается.
Ну ты завернул, сравнив примитивный бейсик с современными языками.
НС>Собственно, в спектруме очень очень мало работы выполняется при сохранении строки программы. То, что там вообще хоть какой то эффект наблюдается — это в силу крайней примитивности и дохлости Z80.
Тогда все процессоры были крайне примитивными и дохлыми. Любая оптимизация была во благо.
НС>Ну и самое главное — в БК было абсолютно то же самое, только без хитрой клавиатуры. Строка при сохранении парсилась по честному, из набора символов. Но в результате в памяти хранилось примерно то же самое, что и в спектруме.
Нифига не то же самое. Я не поленился, скачал эмулятор БКшки и проверил. Проверка синтаксиса произошла при запуске, а не при наборе программы.
НС>Так что твой пассаж про то, что якобы крутой 1801ВМ1 работал медленнее из за отсутствия препарсинга даже близко не соответствует действительности. Да, тормоза при выводе текста — это из-за графической подсистемы — текстовый режим там был чисто программный, аппаратный знакогенератор отсутствовал как класс. В отличие от синклера.
Здрасьте приехали. Это когда у синклера появился аппаратный знакогенератор ? В спектруме единственный режим дисплея — графический, 256х192 точек, монохром отдельно (6кб), аттрибуты отдельно (768байт). Тормоза БКшки исключительно из-за её кривизны (в том числе жирнейшего формата экрана). Заметь, кривизны БКшки, а не её процессора.
Уважаемые господа IID и ночной смотрящий!
Я настоятельно прошу Вас прекратить ОФФтоп и вернуться к теме "какой же всё-таки мразью был Стив Джобс".
В противном случае я буду вынужден обратиться к модераторам и добиться вашего забанивания
Здравствуйте, Доктор ТуамОсес, Вы писали:
ДТ>Уважаемые господа IID и ночной смотрящий! ДТ>Я настоятельно прошу Вас прекратить ОФФтоп и вернуться к теме "какой же всё-таки мразью был Стив Джобс".
Ты кто такой, чтобы указывать, что и где нам обсуждать?
ДТ>В противном случае я буду вынужден обратиться к модераторам и добиться вашего забанивания
Давай, пробуй. А лучше сам себя забань — был вроде пункт про самовольное модерирование в правилах.
Здравствуйте, Ночной Смотрящий, Вы писали:
НС>Здравствуйте, Доктор ТуамОсес, Вы писали:
ДТ>>а какое это всё имеет отношение к тому что джобс был конченой мразью?
НС>Заклинило? Я тебе уже на этот вопрос отвечал, перечитай.
Вообщем последнее китайское предупреждение
Если Вы будете продолжать оффтопить вместо того, чтобы обсуждать какой же конченной мразью был Джобс,
я буду вынужден обратиться к модераторам. И Вы будете забанены
Здравствуйте, Доктор ТуамОсес, Вы писали:
ДТ>Вообщем последнее китайское предупреждение
Еще раз спрошу — ты кто вообще такой, предупреждениями угрожать?
ДТ>Если Вы будете продолжать оффтопить вместо того, чтобы обсуждать какой же конченной мразью был Джобс, ДТ>я буду вынужден обратиться к модераторам. И Вы будете забанены
Я тебе уже сказал — в путь. Ты — последний, чье мнение я буду учитывать при написании сообщений.
Не хотел отвечать, но доктор уж очень просил.
НС>>Обязательно. Это самое самое начало семантического анализа, а с современных языках им вообще парсер до семантики занимается. IID>Ну ты завернул, сравнив примитивный бейсик с современными языками.
Семантический анализ как бы не раньше бейсика придумали.
НС>>Собственно, в спектруме очень очень мало работы выполняется при сохранении строки программы. То, что там вообще хоть какой то эффект наблюдается — это в силу крайней примитивности и дохлости Z80. IID>Тогда все процессоры были крайне примитивными и дохлыми. Любая оптимизация была во благо.
Да я ж не против. Только и преувеличивать ее роль тоже не стоит. IID>Нифига не то же самое. Я не поленился, скачал эмулятор БКшки и проверил. Проверка синтаксиса произошла при запуске, а не при наборе программы.
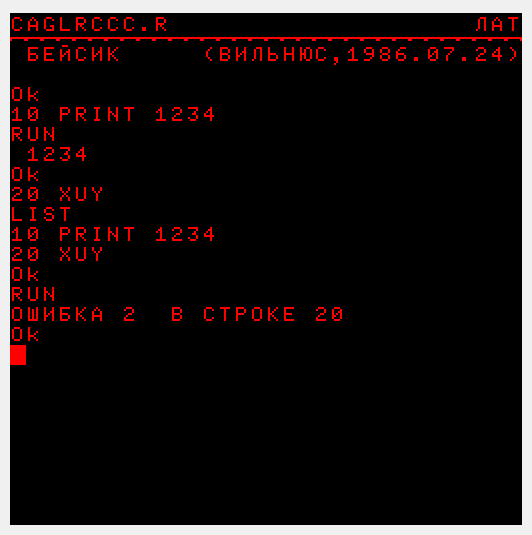
Это потому что в вильнюсском бейсике компиляция была ленивой, только после запуска RUN. Именно тогда формировался т.н. "шитый" код. Техника из Форта взята.
Здравствуйте, Uzumaki Naruto, Вы писали:
UN>На этом тему я думаю и закрываем... с сегодняшнего дня — о покойных или ничего или только хорошее...
хорошее или правду
Здравствуйте, Ночной Смотрящий, Вы писали:
НС>Это потому что в вильнюсском бейсике компиляция была ленивой, только после запуска RUN. Именно тогда формировался т.н. "шитый" код. Техника из Форта взята.
Э-э-э, а при чём тут форт?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском